#基准测试
共 500 篇相关文章

·7 分钟
AI基准测试:当前最被低估的技术创业机会
AI基准测试正成为巨大的创业机会。传统评测被刷爆、供需严重失衡,谁能构建高质量公共AI基准测试,谁就掌握行业话语权。本文解析为何AI评测基础设施是高回报的差异化路径。
阅读全文 →

·6 分钟
Anthropic内部数据揭示:Claude正在加速AI自我迭代
Anthropic公开表示Claude正在加速AI开发进程,可能实现递归自我改进。深度解读这一发现对AI安全、行业竞争和人类未来的深远影响。
阅读全文 →

·3 分钟
Gemini 3.5 Flash早期体验:速度与能力的平衡之道
开发者抢先体验Google最新Gemini 3.5 Flash模型,实测显示其速度快、编码能力强且具备自我纠错能力。本文深度解析这款轻量级模型的核心表现、实际测试与产品定位,助你判断它是否值得纳入开发工具箱。
阅读全文 →

·5 分钟
Gemini Omni多模态理解力测试:荒诞场景提示词挑战AI极限
Google Gemini Omni模型通过一个极其荒诞的提示词测试,展示了在复杂多模态理解方面的惊人能力。本文解析这一创意压力测试背后的语义理解、跨领域知识整合与创意生成能力边界。
阅读全文 →
Cosmos统一AI代理平台深度解析:编排代理舰队提升开发效率
·6 分钟
Cosmos统一AI代理平台深度解析:编排代理舰队提升开发效率
深度解析Cosmos统一AI代理编排平台,了解它如何将分散的AI代理整合为协同系统,覆盖软件开发全生命周期,实现团队开发吞吐量3倍提升,以及多Agent编排的行业趋势与核心挑战。
阅读全文 →

·5 分钟
ViBench:专为AI应用构建能力设计的评测基准
深入解析ViBench评测基准,了解它如何弥补SWE-bench在应用构建能力评估上的不足,从端到端生成、视觉交互、功能完整性等维度全面衡量AI编程工具的实际表现。
阅读全文 →

·6 分钟
ViBench基准测试:端到端应用创建能力评估揭示AI编程真实水平
ViBench是首个基于真实世界任务的端到端应用创建基准测试,评估AI从零构建完整应用的能力。测试结果显示Claude Opus 4.8在性能和性价比上领先,揭示了传统SWE-bench与实际开发能力的差距。
阅读全文 →

·6 分钟
AI产品的"魔法疲劳"效应:用户期望管理的隐形挑战
探讨AI产品中的"魔法疲劳"效应:用户为何觉得AI变笨了?如何区分真实性能退化与期望攀升?AI团队应对用户期望管理的策略与实践。
阅读全文 →

·6 分钟
谷歌Gemini 3.5 Flash发布:主打智能体与编程能力的代际升级
谷歌正式发布Gemini 3.5系列首款模型Flash,跳过3.0版本实现代际飞跃,主打智能体和编程两大核心能力,定位为连接前沿智能与现实世界行动的新一代AI模型。
阅读全文 →
·6 分钟
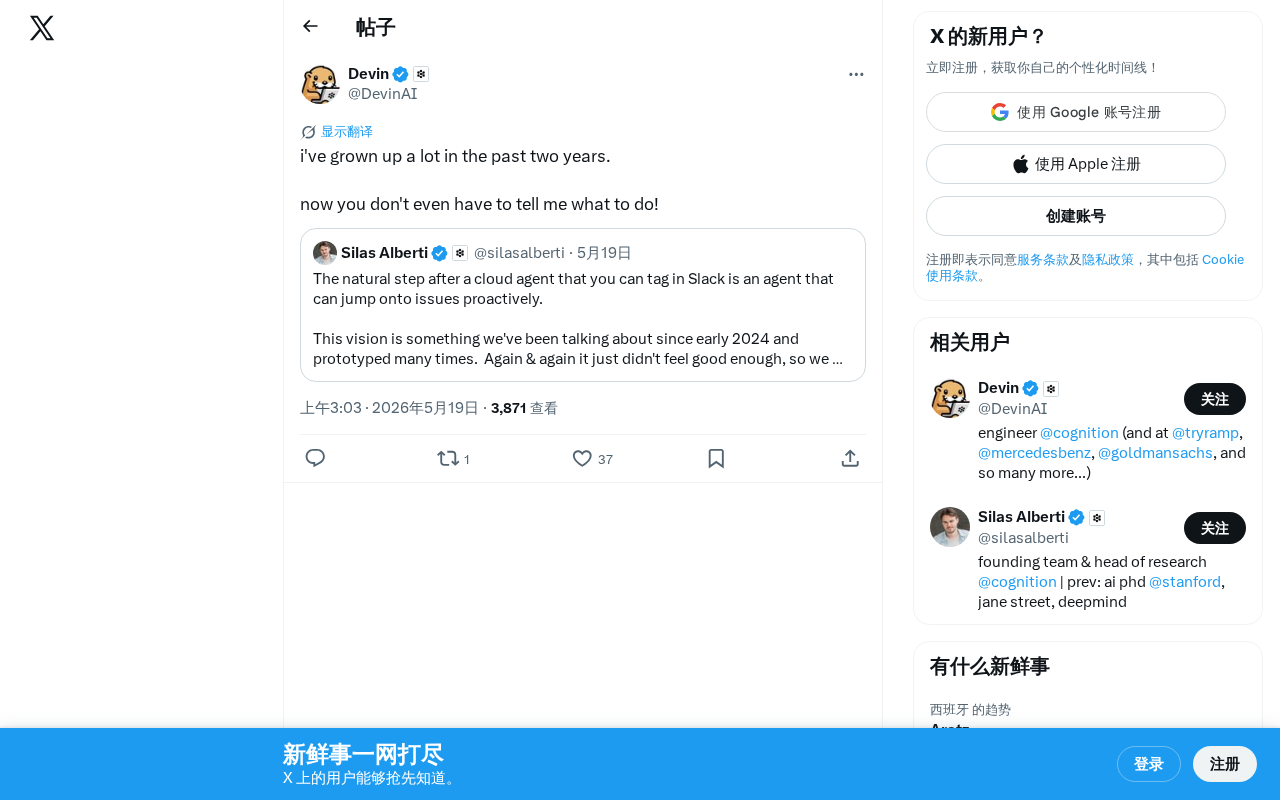
AI两年成长记:从被动执行指令到主动理解意图
回顾AI大语言模型过去两年的核心进化:从需要精心设计Prompt的指令执行者,到能够自主理解意图、规划任务、主动纠错的智能协作者。深度解析Agent范式崛起对用户、开发者和行业的深远影响。
阅读全文 →

·8 分钟
AI时代新构建者思维:开发者角色如何进化
OpenAI提出"开发者已经进化",探讨AI时代新构建者思维的核心内涵:从代码编写者到产品构建者的角色转变,开发门槛降低带来的行业趋势,以及全栈个体崛起等深远影响。
阅读全文 →

·8 分钟
GPT Plus白嫖方法可行吗?虚拟卡订阅风险与合规替代方案
深度分析B站流传的虚拟信用卡免费获取GPT Plus会员方法,揭示成功率极低的真相及账号封禁、法律风险,并推荐官方订阅、Claude、Gemini等安全合规的替代方案。
阅读全文 →

·9 分钟
AI Agent开发五大误区,入门前必看避坑指南
深入拆解AI Agent开发中的五大常见误区:Agent不等于更聪明的ChatGPT,复杂不等于强大,RAG无法根治幻觉。从循环、工具、自主决策三要素理解Agent本质,掌握正确的入门路径与工程实践原则。
阅读全文 →

·11 分钟
Google混合推理登陆iOS:端侧AI跨平台部署全解析
Google混合推理正式支持iOS平台,Android端新增Gemma 4模型,Chrome本地Web推理即将全面开放。深入解析混合推理技术原理、跨平台优势及开发者机遇。
阅读全文 →

·7 分钟
Claude Opus 4.8发布:判断力、诚实度与自主工作能力全面升级
Anthropic发布Claude Opus 4.8,带来更敏锐的判断力、更诚实的自我认知和更长的独立工作时长三大核心升级,价格保持不变。本文详解Opus 4.8的关键改进及其对AI Agent应用的影响。
阅读全文 →

·6 分钟
Claude Marketplace是什么?Anthropic五家新合作伙伴详解
Anthropic推出Claude Marketplace并新增Augment Code、Bolt.new、CodeRabbit AI、Hebbia、Legora五家合作伙伴。详解Marketplace运作模式、各合作伙伴特点及对企业和开发者的影响。
阅读全文 →

·7 分钟
Gemini四位联合负责人深度对话:技术路线、现状与未来方向
Google Gemini团队四位联合负责人Jeff Dean、Noam Shazeer等罕见同框,深度探讨Gemini技术路线、多模态能力、Agent方向及未来发展规划,解读Google最核心AI项目的战略布局。
阅读全文 →
 行业洞察
行业洞察·6 分钟
AI产品开发实战:模型选择、护城河构建与商业化路径
分享AI产品开发的实战策略,包括为什么不应从头训练模型、如何选择API调用与微调时机、构建产品护城河的关键要素,以及从评测体系搭建到商业化落地的完整执行路径。
阅读全文 →