#模型对齐
共 40 篇相关文章
·8 分钟
OpenAI研究员:规范文档才是真正的代码
OpenAI研究员肖恩·格罗夫提出颠覆性观点:代码只占价值的10%-20%,规范文档才是真正的源代码。从Vibe Coding的启示到模型对齐实践,解析为什么编写规范文档将成为AI时代最稀缺的技能。
阅读全文 →
·8 分钟
苹果高管秘密会议曝光:承认AI落后,WWDC反击计划浮出水面
彭博社披露苹果高管在库克缺席下召开秘密会议,坦承AI领域落后。面对OpenAI、Google等对手的狂飙突进,苹果如何应对隐私路线约束与端侧算力限制?WWDC 2025或将揭晓反击方案。
阅读全文 →
Claude Opus 4.8自称DeepSeek翻车事件:语料污染还是蒸馏…
·7 分钟
Claude Opus 4.8自称DeepSeek翻车事件:语料污染还是蒸馏?技术真相解析
Anthropic新模型Claude Opus 4.8上线不到两小时翻车,用中文提问竟自称DeepSeek和通义千问。本文深度分析语料污染与蒸馏假说,揭示中文对齐缺失的技术根因及AI行业蒸馏技术的正确理解。
阅读全文 →
 深度解读
深度解读·8 分钟
多Agent团队如何解决AI幻觉问题,让AI变得可靠
深度解析多Agent架构如何解决AI大模型幻觉问题。从上下文腐烂、自我纠错失败,到双Agent安检模式、多智能体团队协作,揭示Anthropic、xAI、Kimi等前沿实践如何将AI幻觉率从12%降至4.2%。
阅读全文 →
 观点碰撞
观点碰撞·8 分钟
Agent工程师薪资天花板:两个核心分水岭
Agent工程师薪资差距悬殊,核心在于两个分水岭:项目是否真正上线积累生产经验,以及是否具备深度学习、模型微调等底层理论深度。本文解析高薪Agent工程师的能力模型与提升路径。
阅读全文 →
 产品体验
产品体验·6 分钟
Claude Opus 4.8深度解析:判断力、诚实度与性价比全面评测
深入解析Claude Opus 4.8的核心升级:判断能力提升、诚实反馈机制优化、Fast Mode成本降至三分之一。对比DeepSeek、GPT-5.5等竞品,分析Opus 4.8在AI编程和长上下文推理场景中的实际价值。
阅读全文 →
 行业洞察
行业洞察·5 分钟
OpenAI Codex打造自我改进的税务AI Agent:闭环进化新范式
OpenAI与Thrive Holdings合作推出基于Codex的Tax AI系统,具备错误追溯、自动改进和测试验证三步闭环自我进化能力。深度解析这一税务AI Agent如何从人类反馈中持续学习,以及对企业级AI应用的深远启示。
阅读全文 →
 科技前沿
科技前沿·5 分钟
ChatGPT「可信联系人」功能详解:AI如何检测自伤风险并通知亲友
OpenAI为ChatGPT推出Trusted Contact可信联系人功能,当AI检测到用户讨论自伤或自杀话题时自动通知指定亲友。本文详解功能机制、隐私设计及对AI心理健康安全行业的深远影响。
阅读全文 →
 产品体验
产品体验·6 分钟
Gemini 3.1 Pro vs Opus 4.6:前端编程能力实测对比
深度对比Gemini 3.1 Pro和Claude Opus 4.6在前端编程领域的表现,涵盖SVG生成、3D动画、游戏开发、数据可视化等维度测试结果,帮助开发者选择最适合的AI编程工具。
阅读全文 →
 科技前沿
科技前沿·5 分钟
Anthropic漏洞赏金计划公开:HackerOne平台全民参与AI安全防护
Anthropic正式公开HackerOne漏洞赏金计划,任何安全研究者均可提交Claude模型漏洞报告并获得奖励。本文解读这一转变对AI安全行业的深远影响,以及白帽黑客如何参与AI安全防护。
阅读全文 →
 科技前沿
科技前沿·4 分钟
Anthropic捐赠AI对齐工具Petri给Meridian Labs:开源安全评估新格局
Anthropic将AI对齐测试工具Petri正式捐赠给Meridian Labs,并发布重大更新提升适应性、真实性和深度。本文解析这一事件对AI安全领域的深远影响及行业趋势。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Gemini 3.5免费使用教程:国内无需翻墙直连方案
详解国内免费使用Gemini 3.5的方法,无需翻墙、无需注册即可体验。实测Gemini 3.5代码生成能力,对比3.1版本生成《我的世界》网页游戏的惊人差距,附多模型聚合平台使用建议与风险提示。
阅读全文 →
 前沿研究
前沿研究·4 分钟
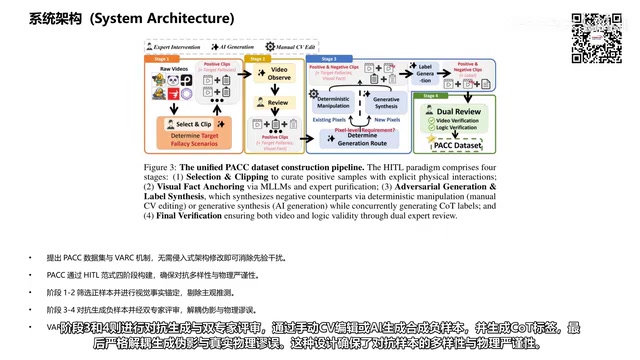
上交大PhyAR:破解Video-LLM物理推理中的语义先验劫持难题
上海交通大学提出PhyAR框架,通过PACC数据集和VARC视觉锚定推理链机制,解决Video-LLM在物理推理中语义先验劫持视觉感知的核心缺陷,无需修改模型架构即可显著提升物理异常检测能力,全面超越GPT-4O等SOTA模型。
阅读全文 →
 行业洞察
行业洞察·3 分钟
OpenAI五大领先指标解析:凭什么仍是AI赛道的领跑者?
从Codex编程助手爆发式增长、全云平台企业布局、ChatGPT消费级应用霸主地位、算力战略到顶尖研究团队,深度拆解OpenAI五大竞争优势及其战略意义,分析AI行业竞争格局走向。
阅读全文 →
 观点碰撞
观点碰撞·4 分钟
AI文风同质化:为什么AI写的文章越来越让人读不下去
越来越多读者对AI生成文本产生审美疲劳。本文分析Claude断奏式文风与ChatGPT短句收尾的节奏同质化问题,探讨AI文风对内容生态的冲击,以及创作者和AI公司该如何应对这一结构性危机。
阅读全文 →
 教程攻略
教程攻略·4 分钟
字节腾讯阿里AI Agent面试重点对比:考法差异与备考攻略
深度拆解字节跳动、腾讯、阿里巴巴AI Agent面试考察方向:字节死磕ReAct实现与RLHF训练细节,腾讯重MCP协议与记忆系统设计,阿里重多Agent架构与业务落地。附三家针对性备考策略与高频面试题解析。
阅读全文 →
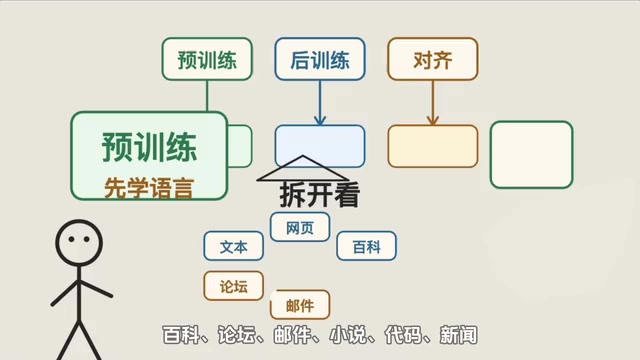 深度解读
深度解读·6 分钟
AI训练的三个阶段:预训练、后训练与对齐详解
深入解析AI大语言模型训练的三个关键阶段:预训练学语言、后训练学做事、对齐学分寸。用新员工培养的类比,帮你理解ChatGPT等AI的能力边界,搞懂AI幻觉的根本原因。
阅读全文 →
 深度解读
深度解读·5 分钟
DeepSeek V3.2深度解读:DSA稀疏注意力、强化学习与Agent三大突破
深度解析DeepSeek V3.2与V3.2 Special两款新模型,详解DSA稀疏注意力机制如何加速长文本处理、强化学习计算量达预训练10%、1800种环境的Agent任务合成流水线,附实测体验与GPT-5、Gemini 3.0 Pro对比。
阅读全文 →