#AI基准测试
共 10 篇相关文章

·7 分钟
AI基准测试:当前最被低估的技术创业机会
AI基准测试正成为巨大的创业机会。传统评测被刷爆、供需严重失衡,谁能构建高质量公共AI基准测试,谁就掌握行业话语权。本文解析为何AI评测基础设施是高回报的差异化路径。
阅读全文 →

·5 分钟
Gemini Omni多模态理解力测试:荒诞场景提示词挑战AI极限
Google Gemini Omni模型通过一个极其荒诞的提示词测试,展示了在复杂多模态理解方面的惊人能力。本文解析这一创意压力测试背后的语义理解、跨领域知识整合与创意生成能力边界。
阅读全文 →
 前沿研究
前沿研究·7 分钟
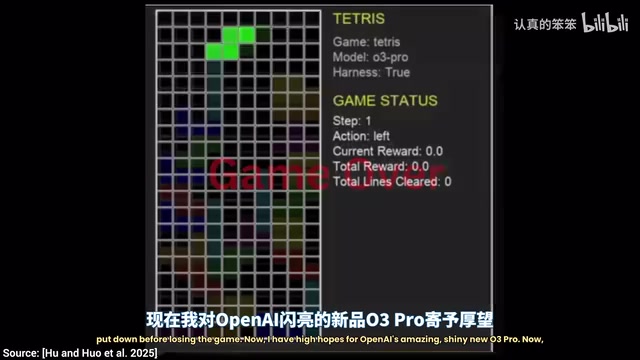
AI玩游戏实力大比拼:O3 Pro展现惊人规划能力
研究者用俄罗斯方块、超级马里奥、推箱子等经典游戏测试各大AI模型,O3 Pro展现出前所未有的规划能力,成为唯一通关全部关卡的模型。游戏测试揭示AI正从模式匹配向真正的战略思维演进。
阅读全文 →
 产品体验
产品体验·8 分钟
Gemini 3.1 Pro vs Claude Opus 4.6:五项实测谁更强
通过SVG图形生成、交互组件、网站构建、复杂推理等五个真实场景,实测对比Gemini 3.1 Pro与Claude Opus 4.6的实际表现,附综合评价与分层使用建议。
阅读全文 →
 产品体验
产品体验·8 分钟
Claude 4.5 vs Gemini 3 Pro:编程能力全面对决
基于ARC-AGI-V2、SWE-Bench、Terminal Bench 2.0等五大基准测试,深入对比Claude 4.5与Gemini 3 Pro在编程实战和知识推理上的真实表现,帮你找到最适合的AI编程助手。
阅读全文 →
 行业洞察
行业洞察·6 分钟
NVIDIA Blackwell创下金融LLM推理STAC-AI新纪录
NVIDIA Blackwell架构GPU在金融行业权威基准STAC-AI中刷新LLM推理性能纪录。深入解析Blackwell架构优势、TensorRT-LLM软硬件协同优化策略,以及大语言模型在金融交易情绪分析、风控合规等场景的应用前景。
阅读全文 →
 教程攻略
教程攻略·7 分钟
Agent Tank攻略:AI写代码打坦克大战,青铜到王者上分指南
Agent Tank是一款用AI Agent编写坦克战斗策略的赛博斗蛐蛐对战游戏。本文详解游戏机制、段位晋升实战技巧、人机协作复盘流程,教你用Claude Code或Codex快速从青铜冲上王者。
阅读全文 →
 深度解读
深度解读·7 分钟
MARVIS项目:嵌入式AI Agent赋能太空自主探索全解析
深入解析MARVIS项目如何将大语言模型Agent部署到太空飞行器,涵盖Agent架构设计、边缘硬件Token性能实测、专家评估结果及太空通用智能基准测试规划,探索从POC到深空自主探索的完整技术路线。
阅读全文 →
 前沿研究
前沿研究·9 分钟
MEME基准测试揭示LLM记忆系统致命缺陷:依赖推理准确率不足50%
MEME基准首次全面评估LLM记忆系统的依赖推理能力,测试6大主流系统结果显示最佳准确率仅42%。本文深度解析级联推理、缺失推理等关键任务的失败根因,并探讨下一代AI Agent记忆架构的改进方向。
阅读全文 →
 产品体验
产品体验·9 分钟
OMI OpenCode实战:免费开源多智能体AI编程框架详解
深入解析OMI OpenCode多智能体编排框架,通过SysForce编排器实现AI编程团队协作。涵盖安装配置、实战演示、免费与付费方案对比,助你用开源工具构建高效AI编程工作流。
阅读全文 →