#AI编程助手
共 485 篇相关文章
 产品体验
产品体验·11 分钟
10款主流AI编程工具全面横评:从Cursor到Claude Code怎么选
深度对比GitHub Copilot、Cursor、Claude Code、Windsurf等10款AI编程工具,从功能定位、适用人群、定价策略三个维度分析,帮助开发者找到最适合的AI编程助手。
阅读全文 →
 产品体验
产品体验·10 分钟
Windsurf AI做游戏实测:四款工具中表现最差
实测用Windsurf AI开发2D超级马里奥游戏,频繁超时报错、代码质量差、耗时近一小时仍问题多多。与DeepSeek、ChatGPT Codex、GitHub Copilot横向对比,Windsurf表现垫底,附详细对比表格与选择建议。
阅读全文 →
 行业洞察
行业洞察·5 分钟
Gemini CLI停服:10万Star说停就停,三大替代方案对比
Google Gemini CLI突然停服,10万Star项目说关就关。深度对比Claude Code、Aider、Cline三大开源终端AI编程替代工具,帮助开发者快速迁移工作流,避免厂商锁定风险。
阅读全文 →
 科技前沿
科技前沿·6 分钟
Opus 4.8登陆Cosmos:长时间任务自主执行能力解析
Claude Opus 4.8模型正式上线Cosmos平台,支持多小时连续任务执行和ticket-to-PR端到端工作流,与Linear、Sentry深度集成,大幅减少人工干预,标志着AI编程助手进入自主执行新阶段。
阅读全文 →
 产品体验
产品体验·5 分钟
Claude Code Fast模式降价:双模式工作流重塑AI编程体验
Anthropic调整Claude Opus 4.8 Fast模式定价,开发者可灵活切换Fast与Normal双模式工作流。本文解析降价影响、交互式与异步任务的最佳搭配策略及实践建议。
阅读全文 →
 产品体验
产品体验·10 分钟
Claude Code前端UI太丑?这个开源Skill让AI学会专业设计
AI编程工具写出的前端页面总是缺乏设计感?UI-UX-Pro-Max-Skill 是一个开源设计增强Skill,内置67种UI风格、161套配色体系,支持Claude Code和Cursor,让AI按设计规范生成高质量前端代码。
阅读全文 →
 教程攻略
教程攻略·7 分钟
Codex安装注册使用全攻略:从下载到VS Code集成实战
详细图文教程讲解OpenAI Codex客户端的下载安装、海外手机号注册验证、套餐选择及VS Code插件集成使用方法,附文件搜索和网页记账本编程实战演示。
阅读全文 →
 科技前沿
科技前沿·4 分钟
OpenAI Codex 全新版本发布:AI编程助手迎来重大升级
OpenAI 正式发布全新版本 Codex,在代码生成准确性、多语言编程支持和开发者工作流整合方面带来显著改进。本文解析新版 Codex 的核心变化及其对 AI 编程赛道的影响。
阅读全文 →
 产品体验
产品体验·8 分钟
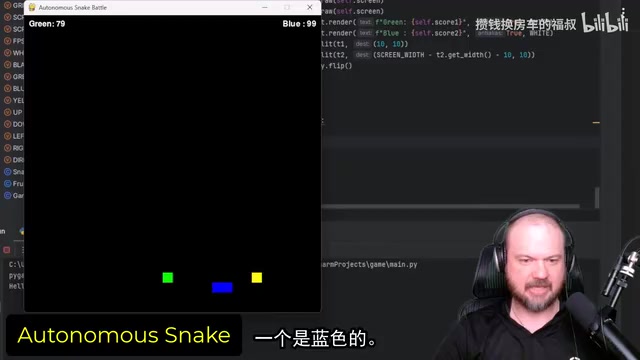
O3 vs Gemini 2.5 Pro vs Claude 3.7:AI编程能力实测对比
通过贪吃蛇对战、强化学习训练、太阳系模拟器、足球游戏四大任务,实测对比O3、Gemini 2.5 Pro、Claude 3.7等AI模型的编程能力,揭示各模型在不同复杂度任务中的真实表现。
阅读全文 →
 产品体验
产品体验·8 分钟
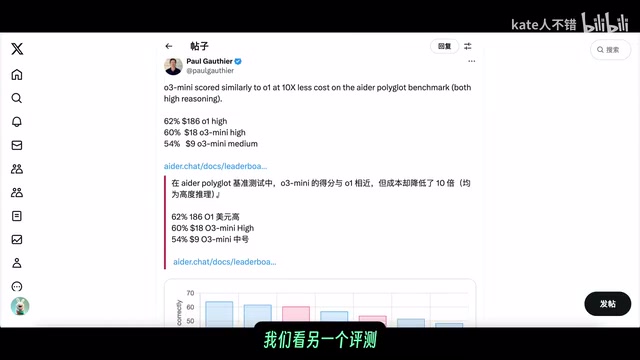
o1、o1 pro与o3-mini-high编程能力深度对比:Deep Research实测分析
通过Deep Research功能系统对比OpenAI o1、o1 pro和o3-mini-high三个模型的编程能力,涵盖代码生成质量、优化能力、错误率与调试表现,附官方基准数据与实际案例分析,帮助开发者选择最适合的AI编程模型。
阅读全文 →
 产品体验
产品体验·8 分钟
13大AI模型编程能力实测:谁才是最强编程助手?
横向评测GPT-4.1、Claude 3.7 Sonnet、Gemini 2.5 Pro等13大AI模型的编程能力,通过同一道高难度算法题从代码正确性、解题思路、多语言转换等8个维度打分,揭晓最强AI编程助手排名。
阅读全文 →
 行业洞察
行业洞察·8 分钟
Claude Code六大底层升级:AI编程从实验室走向工业化
Anthropic对Claude Code进行史上最大规模底层升级,一次性解决终端闪烁、思考假死、玄学报错、上下文死锁、连接不稳、会话崩溃六大顽疾。深度解析这次升级如何将AI编程工具竞赛从能力层拉到基础设施层,以及对开发者工作流的深远影响。
阅读全文 →
 产品体验
产品体验·9 分钟
Augment Remote Agent实测:10个云端AI Agent并行编程体验
深入实测Augment Remote Agent功能,支持10个云端AI Agent并行编程,涵盖自动修Bug、生成PR、文档生成等场景。详解使用流程、实战案例与核心优势,帮助开发者提升编程效率。
阅读全文 →
 教程攻略
教程攻略·7 分钟
Claude Code Monitor工具详解:事件驱动替代轮询,省token更高效
深入解析Claude Code全新内置Monitor工具的工作原理与实际应用。了解事件驱动监控如何替代传统轮询方式,通过流过滤和轮询差异两种模式实现开发服务器监控、测试实时反馈等场景,大幅减少token消耗。
阅读全文 →
 教程攻略
教程攻略·8 分钟
Claude Code调用GPT模型低成本方案:月费10元搭建AI编程工作流
详解如何通过ClipRoxyAPI本地代理服务,将Claude Code的编程交互体验与GPT Codex Team模型结合,实现月费10元以内、额度充足的AI辅助编程方案,涵盖账号准备、代理部署、授权配置全流程。
阅读全文 →
 产品体验
产品体验·8 分钟
ABCoder实战:AI代码幻觉问题的解决方案演示
通过Hertz框架SSE服务实战对比,演示ABCoder如何通过MCP协议让AI模型查阅真实源码,解决大语言模型代码生成中的幻觉问题,实现从猜测到查证的范式转变。
阅读全文 →
 教程攻略
教程攻略·9 分钟
Claude Code桌面版安装配置教程:免账号使用+接入DeepSeek+中文汉化
详细图文教程教你安装Claude Code桌面版,通过开发者模式免账号使用,借助CSwitch接入DeepSeek等国产模型,完成中文汉化及自定义Skill配置,打造低成本AI编程工作流。
阅读全文 →
 教程攻略
教程攻略·7 分钟
Claude Code入门指南:对比普通AI编程的5大核心优势
深度解析Claude Code与普通AI对话工具的核心区别,从交互方式、上下文理解、执行力、记忆能力、工具调用五大维度对比,帮助开发者了解这款AI编程助手的真正实力。
阅读全文 →
 产品体验
产品体验·8 分钟
OpenCode:Go语言打造的终端AI编程神器深度体验
深度解析OpenCode终端AI编程工具,基于Go语言构建,启动速度极快,支持Gemini、Claude等多模型,内置Vim编辑器和LSP集成。对比Claude Code和Aider的优劣势,附安装配置教程与实际使用体验。
阅读全文 →
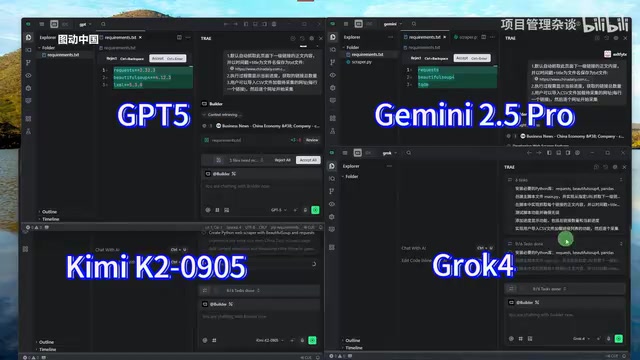 产品体验
产品体验·6 分钟
AI编程实测:GPT-5、Gemini 2.5 Pro、Kimi K2、Grok4爬虫任务全部失败
使用Cursor IDE对GPT-5、Gemini 2.5 Pro、Kimi K2和Grok 4进行静态网页爬虫实测对比,四款顶级大模型全部失败,Claude以126页成绩领先。深度分析各模型失败原因及对开发者的启示。
阅读全文 →