#GPU利用率
共 21 篇相关文章

·7 分钟
Claude Opus 4.8发布:判断力、诚实度与自主工作能力全面升级
Anthropic发布Claude Opus 4.8,带来更敏锐的判断力、更诚实的自我认知和更长的独立工作时长三大核心升级,价格保持不变。本文详解Opus 4.8的关键改进及其对AI Agent应用的影响。
阅读全文 →
 产品体验
产品体验·8 分钟
摩尔线程AI Coding Plan:全栈国产AI编程服务,免费体验30天
摩尔线程推出AI Coding Plan智能编程服务,基于自研MTT S5000 GPU和GLM-4代码模型,实现全栈国产化。兼容VS Code、Cursor等主流IDE,提供30天免费体验和梯度化套餐,为开发者提供国产AI编程替代方案。
阅读全文 →
 产品体验
产品体验·9 分钟
Claude Code vs Cursor深度对比:计费模式与最优方案选择
从计费模式、使用场景和预算匹配三个维度深度对比Claude Code与Cursor。涵盖四种预算方案($20-$220/月),帮助轻度到重度开发者找到最具性价比的AI编程工具组合。
阅读全文 →
 行业洞察
行业洞察·6 分钟
NVIDIA Blackwell创下金融LLM推理STAC-AI新纪录
NVIDIA Blackwell架构GPU在金融行业权威基准STAC-AI中刷新LLM推理性能纪录。深入解析Blackwell架构优势、TensorRT-LLM软硬件协同优化策略,以及大语言模型在金融交易情绪分析、风控合规等场景的应用前景。
阅读全文 →
 前沿研究
前沿研究·7 分钟
Cursor Composer 2训练揭秘:分布式强化学习架构全解析
深度解析Cursor如何在Fireworks上训练Composer 2模型,涵盖异步流水线架构、MoE模型数值精度挑战、Router Replay技术、全球分布式GPU集群协同等核心技术方案,揭示AI编程工具从应用公司迈向基础模型公司的关键路径。
阅读全文 →
 前沿研究
前沿研究·5 分钟
Cursor Composer 2分布式RL训练技术解析
深度解析Cursor如何通过分布式强化学习训练Composer 2模型,涵盖异步流水线设计、MoE数值对齐、全球权重同步、在线离线RL协同等核心技术细节,揭示AI编程工具从应用到基础模型的转型路径。
阅读全文 →
 产品体验
产品体验·5 分钟
GLM 5.1满血旗舰模型实测400 TPS,两分钟从草图到完整应用
实测智谱GLM 5.1 High Speed API,满血旗舰模型输出速度达400 Token/s。从草图还原页面到零基础生成完整解谜游戏,验证速度与能力兼得的AI编程新体验。
阅读全文 →
 教程攻略
教程攻略·6 分钟
本地部署大模型怎么判断显存爆了?一文看懂显存监控方法
本地部署大模型时如何判断显存是否爆满?本文详解专用显存与共享GPU内存的区别,教你通过任务管理器快速判断显存溢出,并提供模型量化、上下文长度控制等避免爆显存的实用建议。
阅读全文 →
 教程攻略
教程攻略·6 分钟
GB200 NVL72块调度实战:Slurm如何榨干机架级NVLink性能
深入解析NVIDIA GB200 NVL72机架级NVLink架构特点,详解Slurm块调度策略如何通过拓扑感知分配、减少资源碎片化来最大化72 GPU互联效率,附配置要点与工作负载优化实践。
阅读全文 →
 教程攻略
教程攻略·11 分钟
NVIDIA Model Optimizer训练后量化(PTQ)实战指南
深入解析NVIDIA Model Optimizer训练后量化(PTQ)工作流,涵盖INT8/INT4量化原理、校准方法、RTX GPU优化策略及大语言模型量化部署最佳实践,助你在消费级显卡上高效运行大模型。
阅读全文 →
 深度解读
深度解读·8 分钟
AI模型部署流水线摩擦:TensorRT如何系统性消除推理优化瓶颈
深入解析AI模型从训练到生产部署中的流水线摩擦问题,详解TensorRT自动化优化、ONNX模型导出、Triton推理服务器等关键技术,提供消除部署瓶颈的最佳实践方案。
阅读全文 →
 深度解读
深度解读·9 分钟
NVIDIA Fleet Intelligence详解:GPU集群实时监控与智能优化方案
深入解析NVIDIA Fleet Intelligence集群智能平台,涵盖GPU集群实时可视化监控、AI异常检测、利用率优化与能效管理等核心功能,帮助数据中心运营者提升大规模GPU基础设施的运维效率与资源利用率。
阅读全文 →
 产品体验
产品体验·10 分钟
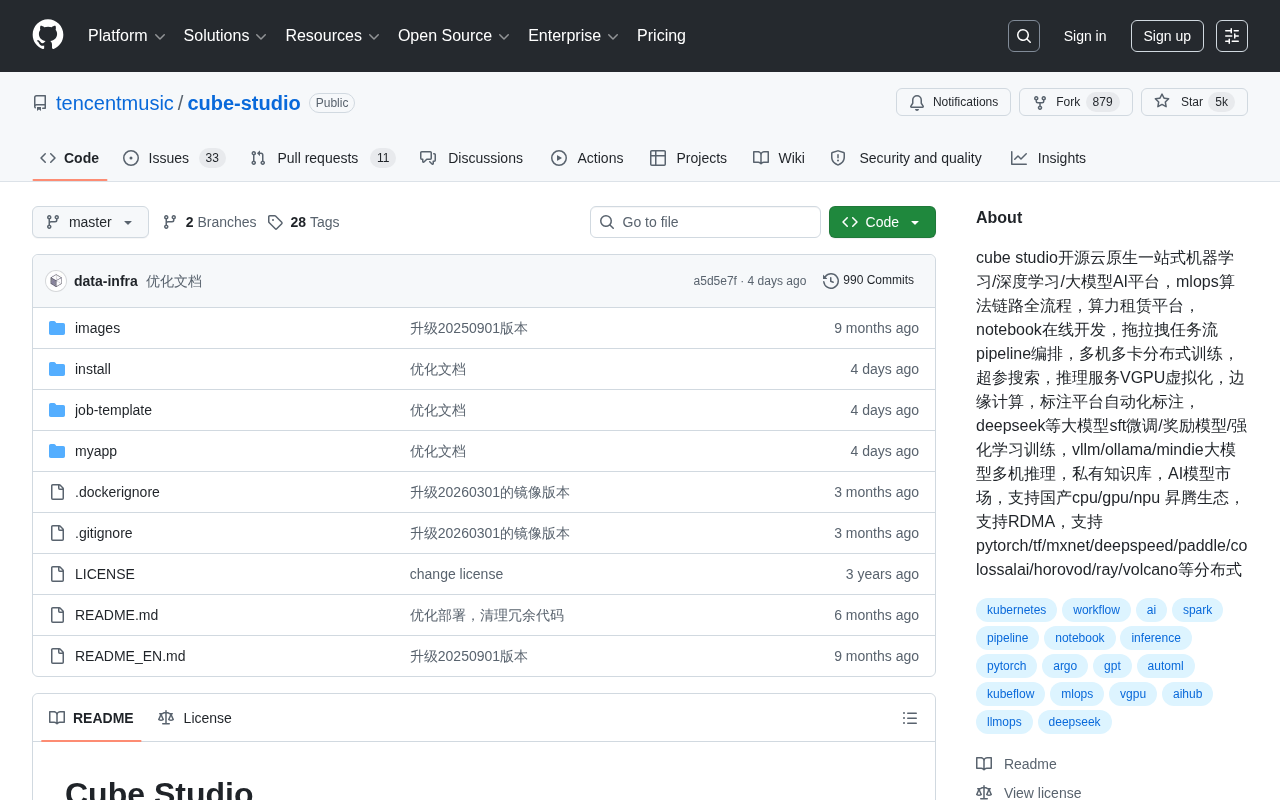
Cube Studio深度解析:腾讯开源一站式MLOps平台
深度解析腾讯音乐开源的Cube Studio一站式AI平台,涵盖架构设计、分布式训练、大模型微调推理、国产化适配等核心能力,帮助企业高效落地MLOps全流程。
阅读全文 →
 观点碰撞
观点碰撞·9 分钟
Vibe Coding七个月后彻底翻车:234次提交全部归档,从零手写
一位开发者用AI进行Vibe Coding七个月,完成234次提交和1690行代码后项目彻底崩溃。本文复盘他的五条血泪教训,揭示AI编程的真实边界:AI写功能不写架构,速度是幻觉,技术债务指数级累积。
阅读全文 →
 教程攻略
教程攻略·11 分钟
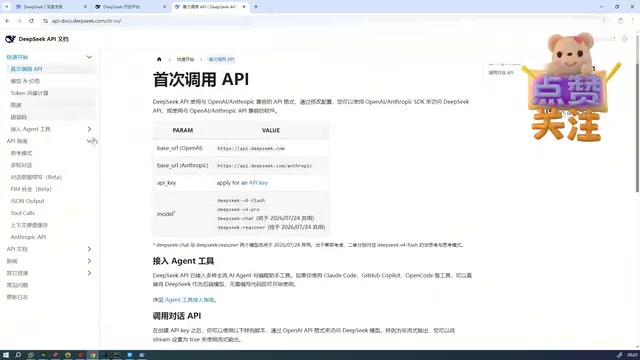
Claude Code实战教程:安装配置、DeepSeek接入与编程技巧全攻略
详解Claude Code安装配置、DeepSeek V4 Pro替代方案、IDE集成方法,附一次对话生成完整前后端项目实战案例、Skill技能系统与MCP配置,以及十条AI编程实战经验总结。
阅读全文 →
 产品体验
产品体验·8 分钟
SwarmUI完全指南:高性能Stable Diffusion界面工具
深度解析SwarmUI这款基于C#的模块化Stable Diffusion Web界面,对比AUTOMATIC1111、ComfyUI等主流工具,详解其高性能架构、模块化扩展和易用性设计,帮你选择最适合的AI绘画前端工具。
阅读全文 →
 产品体验
产品体验·11 分钟
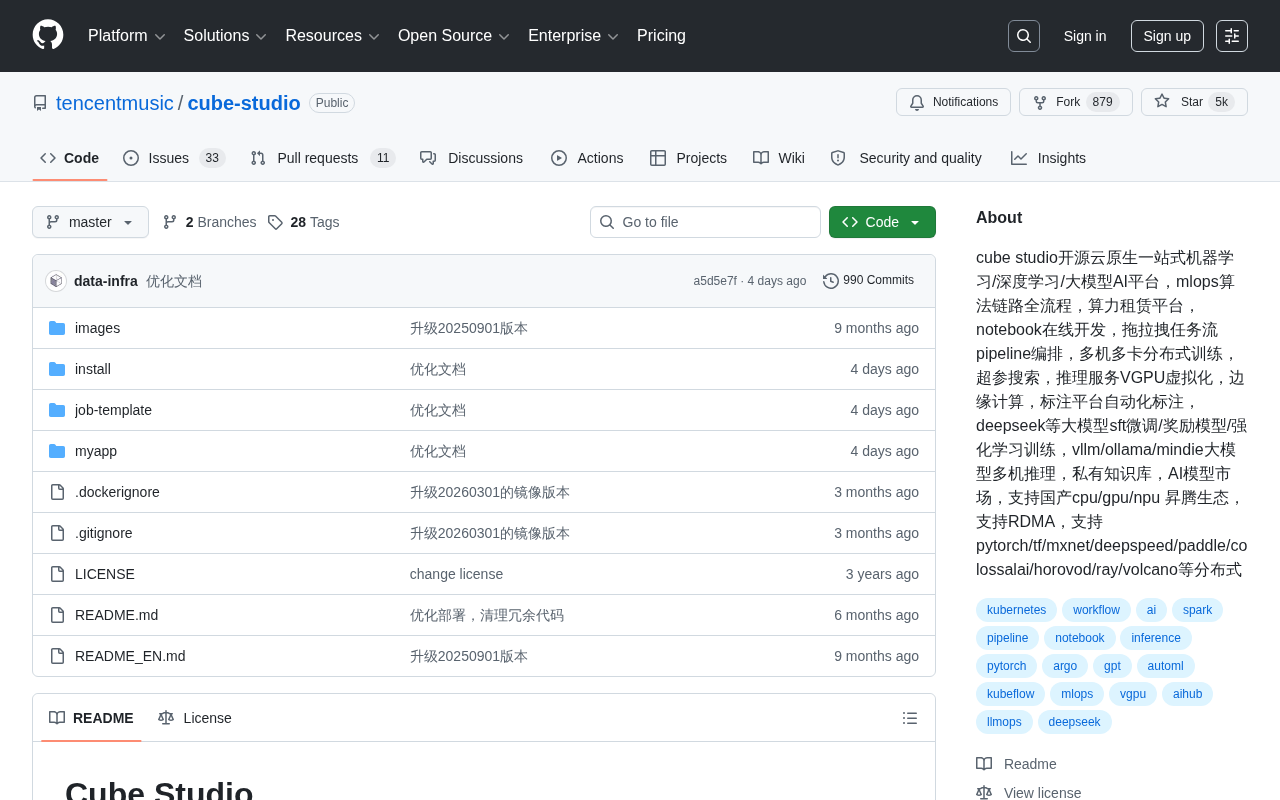
Cube Studio:腾讯开源一站式AI平台,覆盖大模型训练到推理全流程
深度解析腾讯音乐开源的Cube Studio云原生AI平台,涵盖分布式训练、大模型微调、vLLM推理部署、VGPU虚拟化及国产化昇腾适配等核心能力,助力企业高效落地MLOps全流程。
阅读全文 →
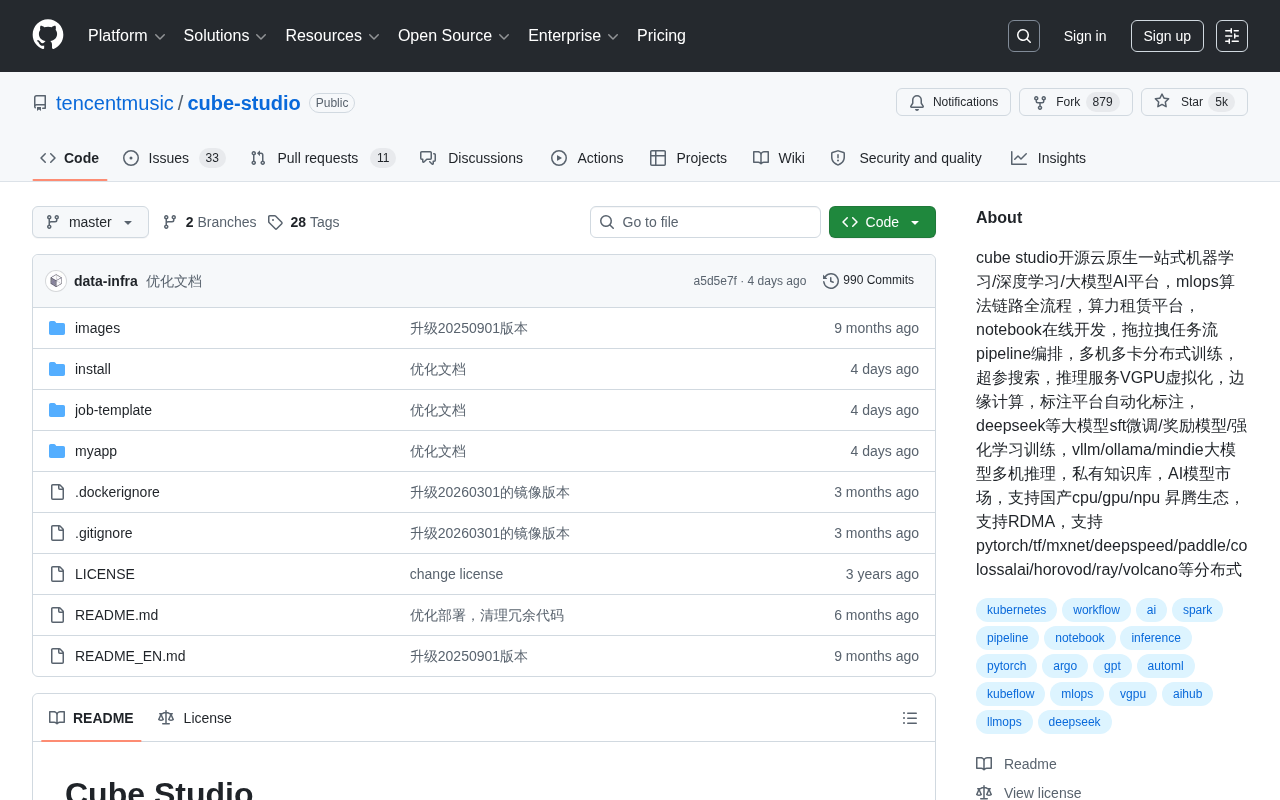 产品体验
产品体验·8 分钟
Cube Studio深度解析:腾讯开源云原生AI平台,MLOps全流程实战指南
深度解析腾讯音乐开源的Cube Studio云原生AI平台,覆盖分布式训练、大模型SFT/RLHF微调、vLLM推理部署、VGPU虚拟化、国产昇腾适配等核心能力,助力企业快速构建MLOps全流程体系。
阅读全文 →