#混合专家模型
共 40 篇相关文章
AI编程为何进步最快?四大结构性优势深度解析
·5 分钟
AI编程为何进步最快?四大结构性优势深度解析
AI编程能力的进步速度远超文案写作和图像生成,背后有四大结构性原因:反馈即时明确、GitHub提供天然优质数据、评判标准统一可量化、完美适配强化学习。本文深度拆解代码任务的独特优势,解释为何编程成为AI发展最快的赛道。
阅读全文 →
Claude Opus 4.8自称DeepSeek翻车事件:语料污染还是蒸馏…
·7 分钟
Claude Opus 4.8自称DeepSeek翻车事件:语料污染还是蒸馏?技术真相解析
Anthropic新模型Claude Opus 4.8上线不到两小时翻车,用中文提问竟自称DeepSeek和通义千问。本文深度分析语料污染与蒸馏假说,揭示中文对齐缺失的技术根因及AI行业蒸馏技术的正确理解。
阅读全文 →

·7 分钟
Gemini四位联合负责人深度对话:技术路线、现状与未来方向
Google Gemini团队四位联合负责人Jeff Dean、Noam Shazeer等罕见同框,深度探讨Gemini技术路线、多模态能力、Agent方向及未来发展规划,解读Google最核心AI项目的战略布局。
阅读全文 →
 产品体验
产品体验·6 分钟
GPT-5.5对决DeepSeek-V4:四轮实测谁更强?
GPT-5.5与DeepSeek-V4四轮全方位实测对比,涵盖世界知识、上下文记忆、逻辑推理和编程开发,详解两大旗舰AI模型的真实表现差异与各自优劣势。
阅读全文 →
 教程攻略
教程攻略·9 分钟
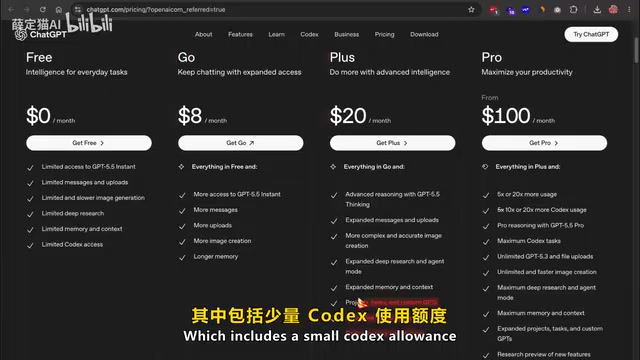
Ollama+Gemma 4本地运行Codex:零成本AI编程完整指南
详解如何用Ollama本地部署Gemma 4模型运行Codex,实现零成本AI编程。涵盖安装配置、模型选择、实际效果演示,替代每月20-200美元的付费方案,适合独立开发者和预算有限的团队。
阅读全文 →
 观点碰撞
观点碰撞·10 分钟
Replit CEO访谈:AI编程模型见顶,SaaS末日正在发生
Replit CEO Amjad Massad深度访谈解读:AI编程模型接近性能天花板,竞争转向产品工程;SaaS正被AI Agent替代;IDE已死;多模型协同架构成为趋势。涵盖Agent迭代、企业变革与创业建议。
阅读全文 →
 科技前沿
科技前沿·8 分钟
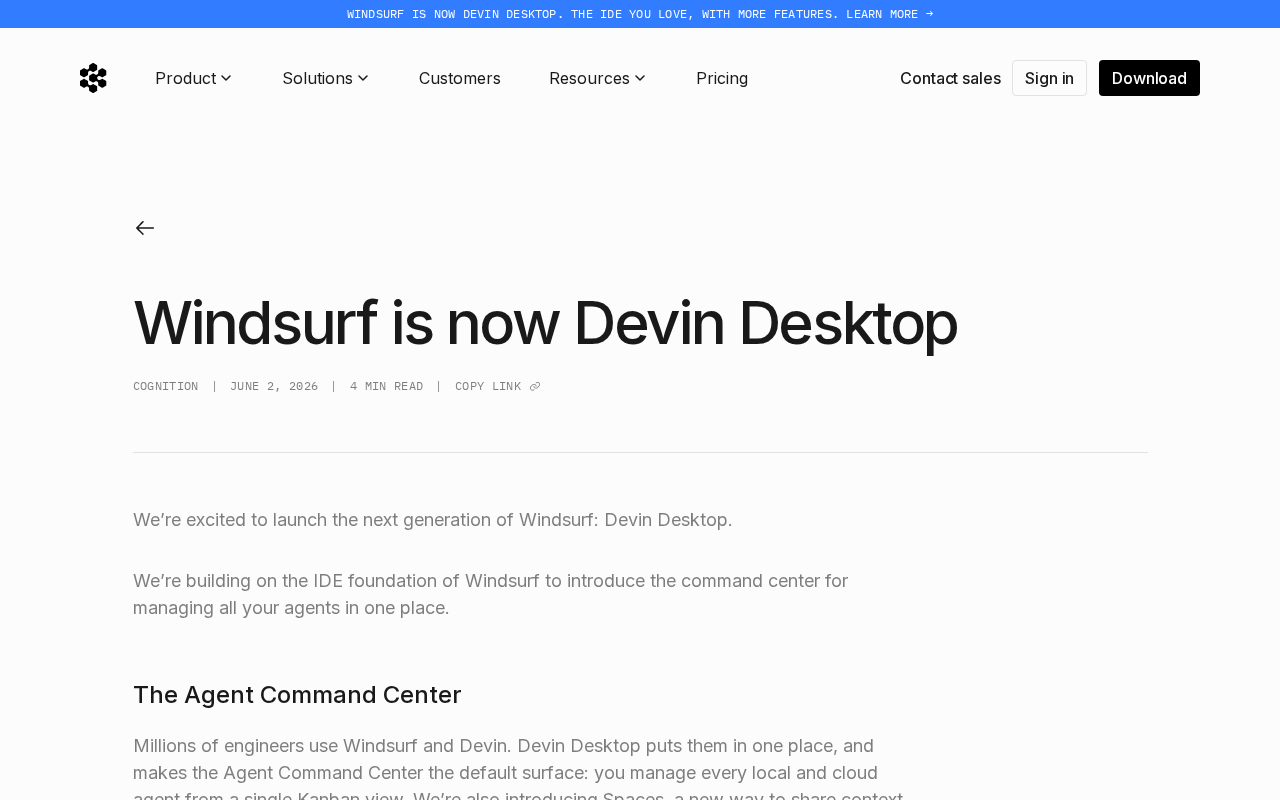
Windsurf更名Devin Desktop:多智能体协作IDE平台全解析
Windsurf正式更名为Devin Desktop,引入Agent Command Center多智能体管理架构、开源ACP协议和Rust重写的本地Agent。详解产品升级要点、企业合作案例及AI编程工具平台化趋势。
阅读全文 →
 产品体验
产品体验·11 分钟
OpenHuman深度解析:上下文优先的开源私人AI Agent
深度解析OpenHuman开源私人AI Agent,详解其上下文优先架构、Rust+React混合方案、内存树记忆系统、Token Juice压缩引擎及多模型动态路由,全面评估其安全设计与竞品优势。
阅读全文 →
 行业洞察
行业洞察·7 分钟
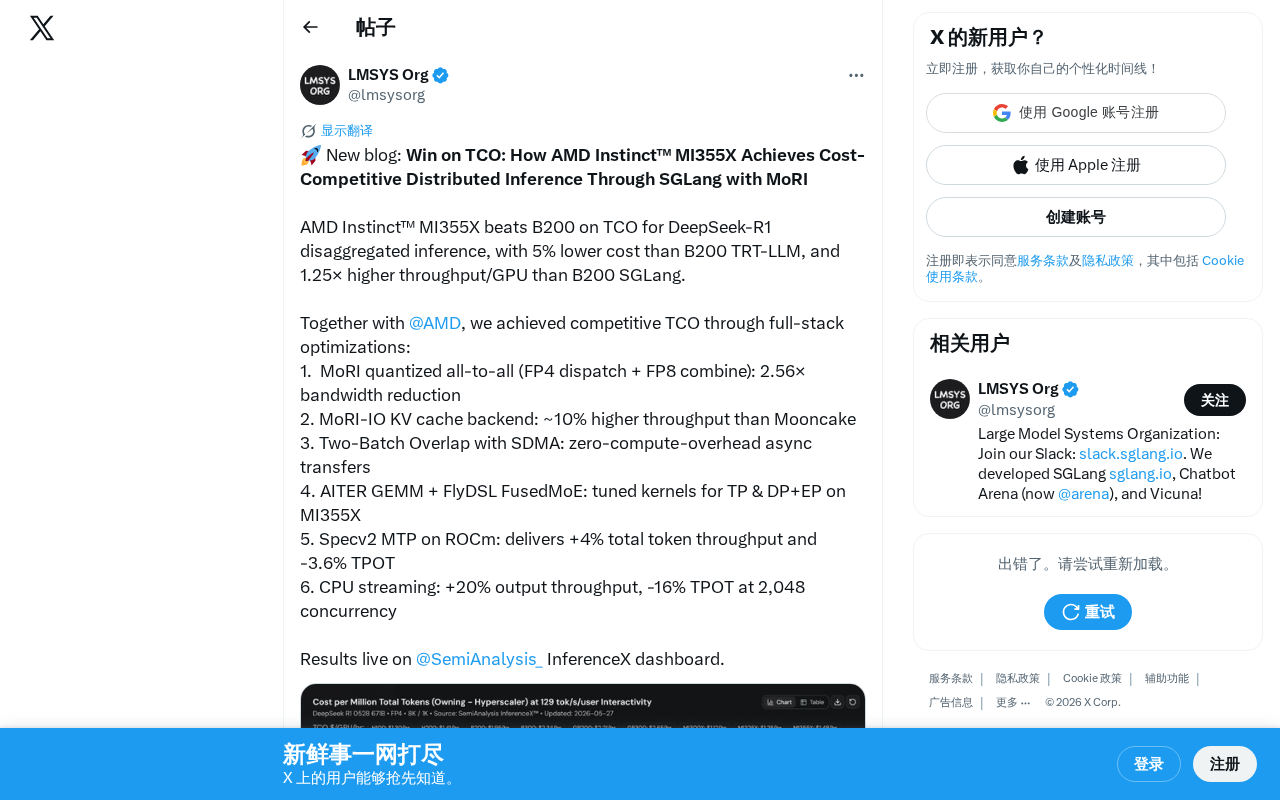
AMD MI355X击败B200:DeepSeek-R1推理TCO低5%的全栈优化解析
AMD Instinct MI355X通过SGLang+MoRI全栈优化,在DeepSeek-R1分离式推理中实现TCO比NVIDIA B200低5%,每GPU吞吐量高1.25倍。深度解析MoRI量化通信、KV Cache优化及推测解码等核心技术突破。
阅读全文 →
 行业洞察
行业洞察·9 分钟
大模型三大岗位深度解析:门槛、技术栈与职业前景
深度解析大模型应用工程师、研发工程师、算法工程师三大核心岗位的技术要求、薪资门槛与发展前景,涵盖RAG、模型微调、推理部署等关键技术栈,助你制定清晰的AI职业规划路径。
阅读全文 →
 教程攻略
教程攻略·7 分钟
Qwen3为何是MCP智能体开发的最佳开源模型
深入分析Qwen3在MCP智能体开发中的核心优势,对比DeepSeek R1不支持Function Calling的致命短板,解读Qwen3的MoE架构、思维模式切换等特性,为开发者提供大模型技术选型的实用建议。
阅读全文 →
 科技前沿
科技前沿·6 分钟
AI周报:Kimi K2.6登顶开源榜,Qwen 3.6与谷歌TTS齐发
本周AI重磅发布汇总:Kimi K2.6登顶开源模型排行榜,Anthropic推出Opus 4.7与Claude Design,阿里Qwen 3.6系列全面铺开,谷歌发布情感可控TTS模型。深度解读开源与闭源模型竞争新格局。
阅读全文 →
 产品体验
产品体验·8 分钟
Qwen 3.6 vs Gemma 4:本地AI编程模型实战开发深度对比
通过Tauri框架开发Markdown编辑器,实测对比Qwen 3.6与Gemma 4两款本地大模型在规划能力、代码生成、开发效率等方面的表现差异,帮助开发者选择最适合的本地AI编程模型。
阅读全文 →
 产品体验
产品体验·9 分钟
Mac本地跑Qwen3.6-27B:4种方案实测对比
实测对比Mac本地运行Qwen3.6-27B的4种方案,包括GGUF、MLX Diflash和MTP-LX。MTP-LX 4bit方案以43.6 tok/s速度领先,编码、写作、推理质量均可圈可点,附安装配置指南。
阅读全文 →
 前沿研究
前沿研究·7 分钟
Cursor Composer 2训练揭秘:分布式强化学习架构全解析
深度解析Cursor如何在Fireworks上训练Composer 2模型,涵盖异步流水线架构、MoE模型数值精度挑战、Router Replay技术、全球分布式GPU集群协同等核心技术方案,揭示AI编程工具从应用公司迈向基础模型公司的关键路径。
阅读全文 →
 前沿研究
前沿研究·5 分钟
Cursor Composer 2分布式RL训练技术解析
深度解析Cursor如何通过分布式强化学习训练Composer 2模型,涵盖异步流水线设计、MoE数值对齐、全球权重同步、在线离线RL协同等核心技术细节,揭示AI编程工具从应用到基础模型的转型路径。
阅读全文 →
 产品体验
产品体验·4 分钟
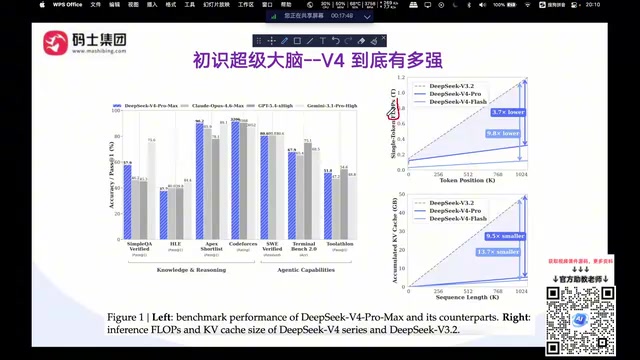
DeepSeek V4深度解析:万亿参数开源模型碾压闭源对手
深度解析DeepSeek V4万亿参数开源模型,从性能Benchmark、百万级上下文技术架构、API成本对比到MIT开源协议,全面拆解V4如何在编程、推理等维度超越GPT和Claude等闭源模型。
阅读全文 →
 教程攻略
教程攻略·8 分钟
LangChain LCEL表达式语言详解:管道操作符、RunnableLambda与并行执行实战
深入解析LangChain LCEL表达式语言的核心概念,涵盖管道操作符底层原理、RunnableLambda函数包装、RunnableParallel并行检索及RunnablePassThrough透传机制,附完整代码示例与RAG多源检索实战。
阅读全文 →
 科技前沿
科技前沿·2 分钟
悟空2.2P开源:35B MOE模型性能超越Qwen3.6-27B,速度快3-5倍
悟空2.2P 35B MOE模型正式开源,采用对抗式杂交蒸馏技术,综合性能超越Qwen3.6-27B。4090显卡Q5量化达158 tokens/s,仅需8.9G显存即可运行,支持256K上下文。详解核心技术、硬件配置与实测数据。
阅读全文 →
 深度解读
深度解读·4 分钟
Qwen3.5深度解析:混合注意力架构实现19倍长上下文加速
深入解析阿里开源Qwen3.5模型的混合注意力架构创新,详解Gated Delta Net如何实现256K上下文19倍加速,多模态视觉反超Gemini 3 Pro和GPT-5.2的评测数据,以及RL后训练策略与实际应用Demo。
阅读全文 →