#GPU推理
共 24 篇相关文章
Codex vs Claude Code深度对比:前端后端开发者如何选择
·9 分钟
Codex vs Claude Code深度对比:前端后端开发者如何选择
从价格、稳定性、能力侧重三个维度深度对比Codex和Claude Code,分析两者在前端UI开发与后端逻辑实现上的差异,附实际工作流选择建议。
阅读全文 →

·6 分钟
Aleph 2.0深度解析:编辑一帧即可改变整段视频
Aleph 2.0发布全新单帧编辑传播功能,只需修改视频中一帧画面即可自动应用到全片。深度解析其Edit Studio编辑工具、时序一致性技术突破及对AI视频编辑行业的影响。
阅读全文 →

·10 分钟
OpenAI Codex像素标识图:多代理协作的视觉识别方案
OpenAI为Codex背景代理推出像素标识图(Pixel Identicons)功能,通过稳定的视觉标识解决多代理协作中的识别难题,降低开发者在多任务管理中的认知负担,提升AI编程工作流效率。
阅读全文 →
 深度解读
深度解读·9 分钟
大模型训练全流程解析:预训练、SFT微调与偏好对齐通俗详解
详解大模型训练三大核心阶段:预训练、有监督微调(SFT)、偏好对齐(DPO/PPO),涵盖LoRA、模型蒸馏量化剪枝等关键技术,帮助开发者理解从Base Model到Chat Model的完整流程。
阅读全文 →
 教程攻略
教程攻略·7 分钟
Ollama入门指南:本地部署开源大模型的最佳工具
详解Ollama本地大模型管理工具的核心功能与特点,包括免费开源、跨平台支持、智能GPU/CPU调度、API集成等能力,帮助你零成本在本地运行DeepSeek等开源大模型。
阅读全文 →
 教程攻略
教程攻略·8 分钟
Mac本地批量AI生图实战:万张插画踩坑与最佳实践
分享Mac本地使用Draw Things批量AI生图的完整实战经验,涵盖提示词迭代策略、负向提示词陷阱、性能优化技巧,以及从本地方案转向Replicate云平台的决策过程,适合需要批量生成插画的开发者参考。
阅读全文 →
 产品体验
产品体验·7 分钟
Hertzman木马人:免费免安装的本地大模型部署工具评测
详细评测Hertzman木马人本地推理引擎,涵盖一键部署、智能硬件推荐、OpenAI兼容API接口等核心功能,并与LM Studio进行性能对比,帮你快速上手本地大模型。
阅读全文 →
 行业洞察
行业洞察·7 分钟
AMD MI355X击败B200:DeepSeek-R1推理TCO低5%的全栈优化解析
AMD Instinct MI355X通过SGLang+MoRI全栈优化,在DeepSeek-R1分离式推理中实现TCO比NVIDIA B200低5%,每GPU吞吐量高1.25倍。深度解析MoRI量化通信、KV Cache优化及推测解码等核心技术突破。
阅读全文 →
 行业洞察
行业洞察·6 分钟
NVIDIA Dynamo Snapshot:GPU推理冷启动问题的快照恢复方案
深入解析NVIDIA Dynamo Snapshot如何通过GPU状态快照与恢复机制,将大模型推理服务的冷启动时间从分钟级降至秒级,涵盖Kubernetes集成、技术实现挑战及弹性推理等实际应用场景。
阅读全文 →
 产品体验
产品体验·9 分钟
Mac本地跑Qwen3.6-27B:4种方案实测对比
实测对比Mac本地运行Qwen3.6-27B的4种方案,包括GGUF、MLX Diflash和MTP-LX。MTP-LX 4bit方案以43.6 tok/s速度领先,编码、写作、推理质量均可圈可点,附安装配置指南。
阅读全文 →
 产品体验
产品体验·5 分钟
AI编程做网站频繁崩溃?原因分析与实用解决方案
AI编程工具做网站时频繁崩溃、请求失败怎么办?本文从多窗口并发、API限流、网络不稳定等角度深入分析崩溃原因,并提供减少并发、切换国内模型、错峰使用等实用解决方案。
阅读全文 →
 教程攻略
教程攻略·5 分钟
Ollama本地部署大模型教程:安装配置到API调用全流程
详解Ollama本地部署开源大模型的完整流程,涵盖安装配置、模型选择与量化策略、Python代码调用API、性能优化等实战技巧,帮你快速在本地运行Qwen、Llama等大模型。
阅读全文 →
 教程攻略
教程攻略·5 分钟
vLLM与SGLang本地部署教程:性能提升3-8倍的实战指南
详解vLLM和SGLang本地部署全流程,对比LM Studio性能差距,通过Docker+AI助手三步完成部署。涵盖SGLang与vLLM选型建议、5090显存优化、Qwen3模型推荐及Cherry Studio接入方法。
阅读全文 →
 科技前沿
科技前沿·4 分钟
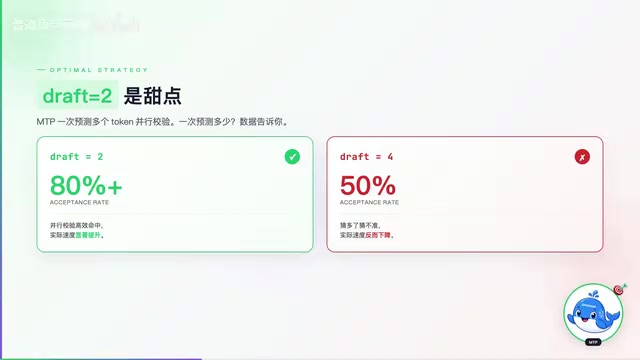
Qwen3.6 MTP加速实测:单GPU推理飙到220 token/s
Qwen3.6实验性MTP-GGUF版本实测,单GPU将35B-A3B模型推理速度提升至220 token/s,比原版快1.4倍且精度零损失。详解MTP原理、最优Draft Tokens策略及RTX 5090实测数据。
阅读全文 →
 教程攻略
教程攻略·12 分钟
Windsurf免费额度用完怎么办?一键切号插件无限续杯
Windsurf免费额度耗尽后如何继续使用?本文详解一款无感切号插件,支持一键自动切换账号,无需手动登出、输密码或复制Token,帮助开发者保持编码心流不被打断。
阅读全文 →
 深度解读
深度解读·11 分钟
Windsurf换号插件有多危险?技术原理与安全风险深度解析
深度剖析Windsurf无感换号插件的技术实现原理,揭示账号封禁、代码泄露、法律风险三大隐患。提供Windsurf免费额度不够用时的四种合规替代方案,帮助开发者安全高效地使用AI编程工具。
阅读全文 →
 深度解读
深度解读·8 分钟
NVIDIA Dynamo多轮智能体交互:流式Token与工具调用深度集成
深入解析NVIDIA Dynamo框架对多轮智能体交互的支持,涵盖流式Token输出、工具调用结构化处理、状态管理及与MoE架构协同,助力开发者构建生产级AI Agent系统。
阅读全文 →
 教程攻略
教程攻略·10 分钟
Codex+Ollama本地部署教程:零成本搭建AI编程助手
手把手教你用Codex搭配Ollama在本地部署免费AI编程助手,涵盖硬件检测、Ollama安装、Gemma/Qwen模型下载与接入配置全流程,轻松实现隐私安全的本地AI编程工作流。
阅读全文 →