#vLLM
共 122 篇相关文章
 行业洞察
行业洞察·8 分钟
AI账号轮换工具的风险揭秘:灰产背后的安全隐患
深度解析AI额度破解工具的运作模式,揭示账号轮换灰产背后的法律合规风险、数据泄露隐患,并提供API付费、订阅升级等正当替代方案。
阅读全文 →
 教程攻略
教程攻略·7 分钟
pnpm Monorepo全栈AI工程化实战:搭建多模态对话系统
详解如何用pnpm Monorepo架构搭建全栈AI多模态对话系统,涵盖本地模型集成、图片理解、流式对话等核心功能,提供工程化最佳实践与落地方案。
阅读全文 →
 科技前沿
科技前沿·4 分钟
Windsurf接入Claude Opus 4.7快速模式,速度提升2.5倍
Windsurf正式接入Claude Opus 4.7快速模式,输出速度提升约2.5倍且保持完整智能水平。本文分析快速模式对开发者编程效率的实际影响,以及AI编程工具市场的竞争格局变化。
阅读全文 →
 行业洞察
行业洞察·5 分钟
SGLang进军金融业:AI推理基础设施如何重塑华尔街
SGLang联合Crusoe AI、Cloudflare等举办金融AI推理活动,探讨LLM推理框架在交易、风控、合规等场景的落地应用,解析AI推理基础设施垂直化趋势及金融行业部署前景。
阅读全文 →
 教程攻略
教程攻略·6 分钟
AMD GPU部署PD分离式SGLang多节点推理集群教程
详解如何在AMD GPU上部署PD分离式SGLang推理集群,通过单一配置文件实现Prefill-Decode解耦的多节点部署,提升大模型推理吞吐量与延迟表现,附架构原理与适用场景分析。
阅读全文 →
 科技前沿
科技前沿·6 分钟
SGLang v0.5.12.post1发布:DeepSeek V4稳定性修复与Blackwell适配
SGLang v0.5.12.post1稳定性补丁详解,包含12项关键修复,涵盖DeepSeek V4乱码与崩溃问题、NIXL PD分离式推理逻辑修复、Blackwell B300架构适配及冷启动性能优化。
阅读全文 →
 科技前沿
科技前沿·7 分钟
Step 3.7 Flash:198B稀疏MoE多模态模型深度解析
深度解析StepFun AI发布的Step 3.7 Flash,一款198B参数稀疏MoE视觉语言模型,支持256K上下文与三级推理,在多模态理解、AI编程和Agent工具编排方面表现顶尖,已获SGLang首日支持。
阅读全文 →
 科技前沿
科技前沿·5 分钟
Cloudflare向SGLang贡献KV Cache与Mooncake关键修复
Cloudflare向SGLang上游提交decode KV cache offload和Mooncake recovery两项关键修复,解决高并发场景下Kimi K2.6模型乱码输出问题,并实现分布式推理节点自动故障恢复,提升生产环境稳定性。
阅读全文 →
 科技前沿
科技前沿·5 分钟
SGLang举办Agent Loops主题Office Hour,聚焦智能体循环架构优化
SGLang团队举办Agent Loops主题Office Hour,深入探讨智能体循环调用的推理优化方案,涵盖KV Cache复用、低延迟多轮对话及工具调用等关键技术,助力AI Agent开发者提升推理性能。
阅读全文 →
 科技前沿
科技前沿·6 分钟
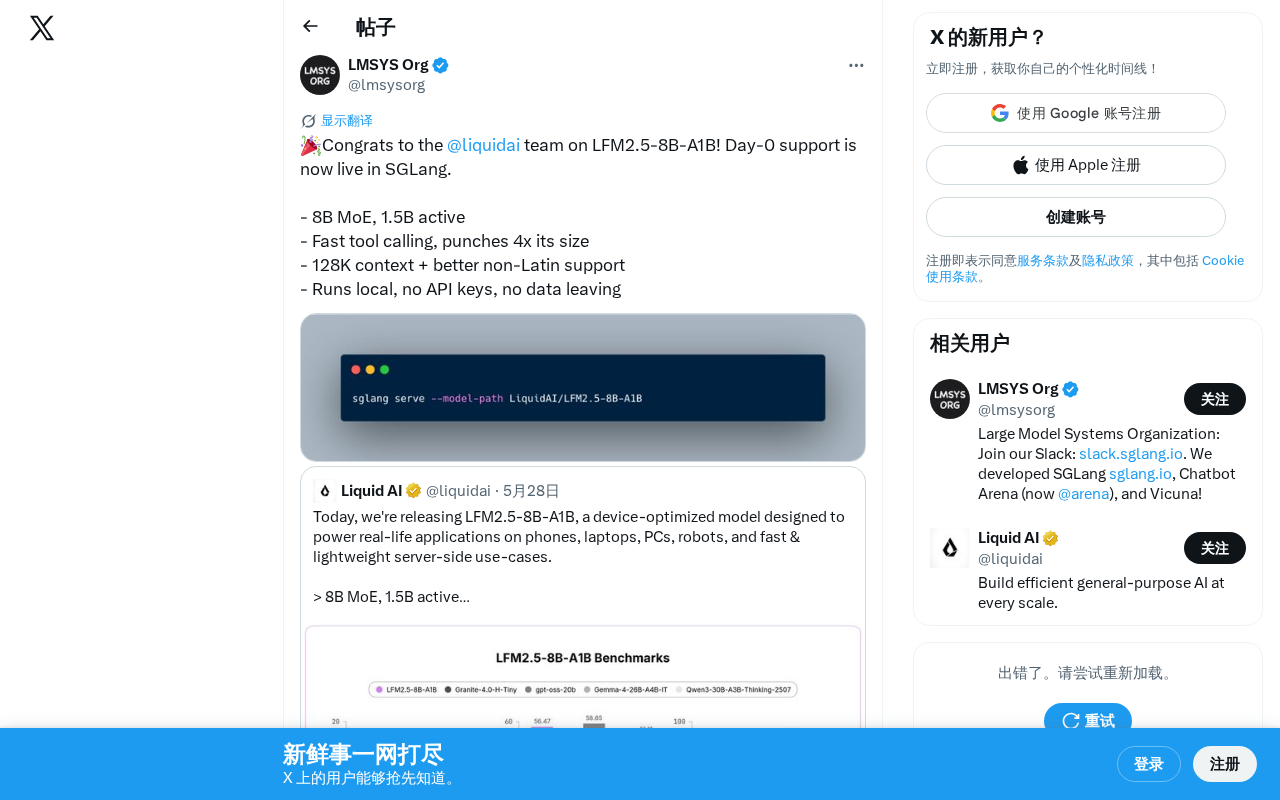
LFM2.5-8B-A1B:1.5B激活参数实现4倍体量效果的MoE模型
Liquid AI发布LFM2.5-8B-A1B模型,采用MoE架构,8B总参数仅激活1.5B,在工具调用场景中媲美6B级模型表现。支持128K上下文、本地部署、多语言,SGLang即时支持。
阅读全文 →
 行业洞察
行业洞察·9 分钟
大模型三大岗位深度解析:门槛、技术栈与职业前景
深度解析大模型应用工程师、研发工程师、算法工程师三大核心岗位的技术要求、薪资门槛与发展前景,涵盖RAG、模型微调、推理部署等关键技术栈,助你制定清晰的AI职业规划路径。
阅读全文 →
 教程攻略
教程攻略·9 分钟
Claude Agent SDK+LiteLLM+本地大模型:零成本搭建智能体平台
详解如何通过LiteLLM Proxy将Claude Agent SDK的API请求重定向到本地大模型,在保留完整Agent框架能力的同时将推理成本降为零。含架构设计、实战演示与企业级部署方案。
阅读全文 →
 产品体验
产品体验·7 分钟
4×3080Ti本地部署千问3.6 27B跑OpenCode编程实测
使用4张3080Ti 16G魔改显卡本地部署千问3.6 27B FP8模型,配合OpenCode完成系统管理工具开发的完整实测。涵盖硬件配置、推理速度、上下文管理经验及开发效率对比。
阅读全文 →
 教程攻略
教程攻略·9 分钟
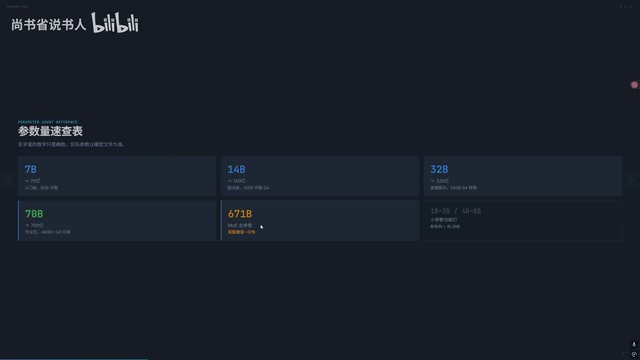
大模型命名规则解析:参数量、量化格式与显存需求速查
系统拆解大模型命名规则,解释32B参数量、AWQ/GGUF量化格式的含义,提供4-bit量化显存估算公式与速查表,涵盖MOE模型显存陷阱、IMatrix量化推荐及按显存档位的模型选择建议。
阅读全文 →
 产品体验
产品体验·5 分钟
GLM 5.1满血旗舰模型实测400 TPS,两分钟从草图到完整应用
实测智谱GLM 5.1 High Speed API,满血旗舰模型输出速度达400 Token/s。从草图还原页面到零基础生成完整解谜游戏,验证速度与能力兼得的AI编程新体验。
阅读全文 →
 教程攻略
教程攻略·4 分钟
Java+AI:程序员突破35岁危机的实战路径
深度解析Java程序员如何通过叠加AI技能突破35岁职业瓶颈。从AI学习四个层次定位、Java+AI技术栈协同、到不同背景的差异化转型建议,提供一套可落地的职业升级方案。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Docker Model Runner使用教程:一条命令本地运行AI模型
详解Docker Model Runner的安装配置与实战用法,通过Docker Compose集成本地AI模型,兼容OpenAI API接口,实现零配置本地部署LLM大模型,附完整聊天应用开发示例。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Hermes + Qwen3.6 本地部署教程:零成本搭建私有AI Agent
详细教程教你用Hermes Agent搭配Qwen3.6开源大模型,在本地零成本部署私有AI助手。涵盖WSL环境配置、模型下载启动、Telegram机器人对接及开机自启设置,实现无限Token、数据私有的AI Agent体验。
阅读全文 →

