#CUDA
46 related articles

·4 min
Cursor Composer2 Training Revealed: A Complete Guide to Distributed Reinforcement Learning Engineering
Deep dive into how Cursor trained Composer2: two-stage architecture, global distributed clusters, MOE numerical alignment, simulation anti-cheating, and more.
Read more →
Stable Diffusion Local Deployment Guid…
·2 min
Stable Diffusion Local Deployment Guide: Free Unlimited AI Image Generation
Complete guide to deploying Stable Diffusion locally for free unlimited AI image generation. Covers installation steps, model management, hardware requirements, and use cases.
Read more →
Stable Diffusion Local Deployment Guid…
·1 min
Stable Diffusion Local Deployment Guide: Build Your AI Art Environment at Zero Cost
Complete guide to deploying Stable Diffusion locally, covering hardware requirements, installation steps, model configuration, and usage tips. Run AI art for free on your own PC with full privacy.
Read more →
Stable Diffusion Poxian Edition Bundle…
·1 min
Stable Diffusion Poxian Edition Bundle: A Free Local AI Creation Tool with One-Click Installation
Stable Diffusion Poxian Edition bundle: install in 3 steps with 337 built-in workflows, Chinese-annotated models, GTX 1060+ support, and completely free local AI image/video generation.
Read more →
PyTorch Beginner's Guide: A Complete A…
·3 min
PyTorch Beginner's Guide: A Complete Analysis of Deep Learning Framework Selection and Evolution
A comprehensive analysis of why PyTorch became the most mainstream deep learning framework. Covers framework history, comparisons with TensorFlow and Keras, dynamic graphs, Tensors, installation guide, and cloud trends.
Read more →
Vibe Coding for Absolute Beginners: Le…
·3 min
Vibe Coding for Absolute Beginners: Let AI Be Your Personal Programmer
A beginner's guide to Vibe Coding: learn the core philosophy, set up Miniconda virtual environments, and use natural language to let AI write code for you — no programming experience required.
Read more →
Rebuilding a Complete GUI App with Dee…
·2 min
Rebuilding a Complete GUI App with DeepSeek for Just $2.50: A Real-World AI Programming Cost Breakdown
A Bilibili creator used DeepSeek V4 Pro via Cursor to rebuild a complete IndexTTS GUI app for just 18.63 RMB (~$2.50). Full breakdown of the AI coding workflow, features, and cost comparison.
Read more →
·3 min
vLLM Deep Dive: How PagedAttention Enables High-Throughput LLM Inference
Deep dive into vLLM's core technologies for high-throughput LLM inference, including PagedAttention memory management, continuous batching, distributed deployment, and comparisons with TensorRT-LLM.
Read more →
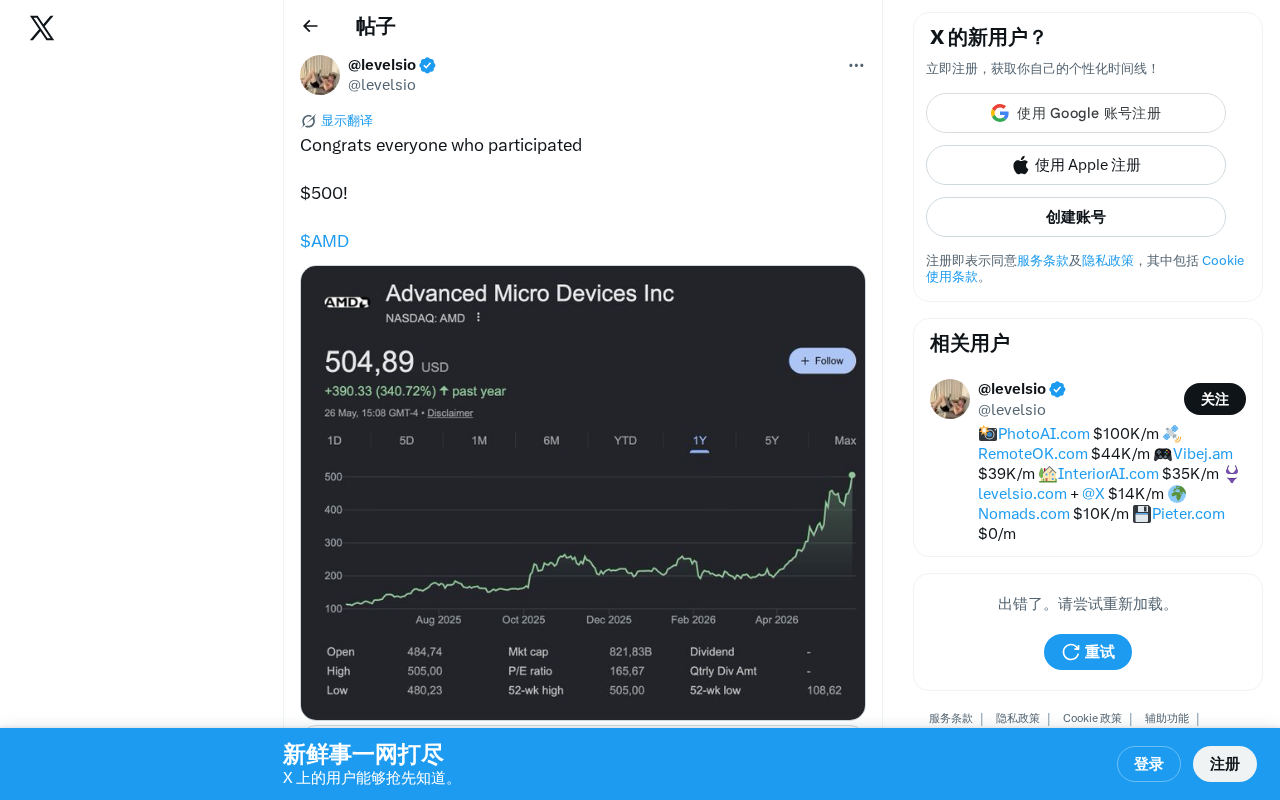
·2 min
AMD Stock Breaks $500: A Deep Dive into the AI Chip Competitive Landscape
AMD stock breaks $500, hitting a new all-time high. Deep analysis of AMD's AI chip strategy, competition with NVIDIA, MI300X advantages, and potential risks.
Read more →
 Expert Opinions
Expert Opinions·3 min
Windsurf CEO Deep Dive Interview: Speed Is the Only Moat
Windsurf CEO Varun Mohan shares insights on AI coding IDE pivots, product methodology, async Agent challenges, and differentiation strategy vs Cursor. Speed is the only moat.
Read more →
 Deep Dives
Deep Dives·2 min
The "Worse is Better" Philosophy of Large Model Design: Why Simple and Brutal Beats Refined and Complex
Analyzing the "worse is better" philosophy in large model architecture: why DeepSeek V4 dropped N-gram, why Transformer dominates AI, and three iron laws of simple, efficient model design.
Read more →
 Tutorials
Tutorials·2 min
Ollama Getting Started Guide: The Best Tool for Locally Deploying Open-Source LLMs
A detailed guide to Ollama's core features: free open-source local LLM management with cross-platform support, intelligent GPU/CPU scheduling, and API integration for running DeepSeek and other open-source models locally at zero cost.
Read more →
 Tutorials
Tutorials·3 min
Optimizing ASR Startup Scripts with DeepSeek: Intelligent Detection Over Countdown Timers
Learn how to use DeepSeek to rewrite ASR local AI project startup scripts from countdown mode to intelligent output-based detection, with full steps and troubleshooting tips.
Read more →
 Tech Frontiers
Tech Frontiers·3 min
OpenAI Leadership Shakeup as Greg Brockman Returns, Cerebras IPO Hits $67B Valuation, Open-Source Agents Dominate GitHub
OpenAI co-founder Greg Brockman takes over product strategy, Cerebras IPO hits $67B market cap, and open-source agents OpenHuman and OpenClack dominate GitHub as AI shifts from capability to deployment.
Read more →
 Tech Frontiers
Tech Frontiers·3 min
GPT-5.6 Internal Testing Begins: A Complete Breakdown of the Week's Biggest AI Developments
GPT-5.6 internal testing launches UltraFast mode, Codex goal-driven mode revolutionizes AI programming, MiniMax cuts costs 360x, Anthropic vs OpenAI valuation war, Cerebras IPO raises $5.55B, Figure robot validates 8-hour autonomous ops, Google Vio 3.1 leads AI video.
Read more →
 Product Reviews
Product Reviews·3 min
Google Gemma 4 Hands-On Review: Offline on Smartphones + Ollama Deployment Tutorial
Hands-on testing of Google Gemma 4 open-source models running offline on three phones, with Dense vs MOE architecture explained and a complete Ollama + Claude Code deployment tutorial.
Read more →
 Product Reviews
Product Reviews·3 min
Moore Threads AI Coding Plan: A Fully Domestic AI Programming Service with 30-Day Free Trial
Moore Threads launches AI Coding Plan powered by its MTT S5000 GPU and GLM-4 code model, achieving full-stack domestic AI coding. Compatible with VS Code and Cursor, with a 30-day free trial.
Read more →
 Tutorials
Tutorials·3 min
Why Learning AI from Scratch Leaves You More Confused — A Clear, Systematic Roadmap for Beginners
Confused learning AI from scratch? This guide breaks down why fragmented learning fails and provides a complete path from Python to deep learning with practical tips.
Read more →
 Industry Insights
Industry Insights·4 min
In-Depth Analysis of the AI Large Model Job Market: Two Core Directions and Future Trends
In-depth analysis of the AI large model job market, breaking down the two core directions—algorithm research and engineering deployment—covering requirements, barriers, and career prospects.
Read more →
 Tutorials
Tutorials·3 min
llama.cpp MTP Acceleration Deployment Guide: Configuration Steps & Real-World Benchmarks
Guide to enabling MTP multi-Token prediction acceleration in llama.cpp, covering CUDA setup, desktop configuration, model selection, and benchmarks showing ~60 Token/s with Qwen3 27B.
Read more →