#Claude Sonnet 4
共 75 篇相关文章
 科技前沿
科技前沿·8 分钟
GPT-5.6曝光:Codex日志泄露内部测试,Anthropic企业采用率首超OpenAI
GPT-5.6在OpenAI内部Codex日志中现身调用记录,首批检查点已启动测试。Anthropic企业采用率达34.4%首超OpenAI的32.3%,Claude Code额度提升50%。一文看清AI行业最新竞争格局变化。
阅读全文 →
 产品体验
产品体验·10 分钟
GPT-5.2、Claude 4.5、Gemini 3 Pro实测对比:2025选购指南
2025年实测对比GPT-5.2、Claude Sonnet 4.5、Gemini 3 Pro、Grok 4.1四大AI模型,覆盖图像生成、深度研究、写作推理等核心场景,附各模型优劣势总结与低成本体验方案。
阅读全文 →
 教程攻略
教程攻略·11 分钟
Claude Opus 4.5使用教程:编程能力实测+国内免翻墙访问方法
详细实测Claude Opus 4.5编程、写作和数据可视化能力,对比上一代提升明显。提供两种国内使用方案,包括免翻墙直连方法,附Bug修复、数据大屏开发等真实案例演示。
阅读全文 →
 产品体验
产品体验·9 分钟
ChatGPT vs Gemini vs Claude:谁能从零做出马里奥64?
实测ChatGPT 5.2、Gemini 3 Pro、Claude 4.5用同一提示词从零开发超级马里奥64克隆游戏。从画面、帧率、可玩性全面对比,Gemini综合第一,ChatGPT画面最佳但仅1帧,Claude碰撞检测严重翻车。
阅读全文 →
 前沿研究
前沿研究·9 分钟
MEME基准测试揭示LLM记忆系统致命缺陷:依赖推理准确率不足50%
MEME基准首次全面评估LLM记忆系统的依赖推理能力,测试6大主流系统结果显示最佳准确率仅42%。本文深度解析级联推理、缺失推理等关键任务的失败根因,并探讨下一代AI Agent记忆架构的改进方向。
阅读全文 →
 产品体验
产品体验·9 分钟
全栈实测:GPT-5 vs Claude 4编码能力差距有多大?
通过医院物资柜监控系统实测GPT-5和Claude Sonnet 4的编码能力,覆盖Lint修复、全栈数据迁移、WebGL渲染Bug三大任务。GPT-5完成率仅33%,Claude Sonnet 4达到100%,深度对比全栈理解力差距。
阅读全文 →
 教程攻略
教程攻略·10 分钟
Claude 4.5 Haiku发布:7种AI副业变现方法实战指南
Claude 4.5 Haiku以三分之一成本实现Sonnet 4级编码性能,速度翻倍。本文深度解析7种利用AI模型变现的实战方法,涵盖文案写作、社交媒体运营、AI自动化服务等,附真实收入数据与操作流程。
阅读全文 →
 产品体验
产品体验·9 分钟
Kiro IDE完全指南:亚马逊免费AI编程工具深度评测
深度评测亚马逊推出的Kiro IDE,详解规范模式、代理钩子等核心功能,对比Cursor和Windsurf的差异。目前完全免费且无限调用Claude Sonnet 4.0,附安装教程与实战体验。
阅读全文 →
 科技前沿
科技前沿·9 分钟
Gemini CLI开源发布:每天1000次免费调用Gemini 2.5 Pro
谷歌正式开源Gemini CLI终端代理工具,每天1000次免费调用Gemini 2.5 Pro,支持100万Token上下文。同期Anthropic Claude模型全面接入GitHub Copilot,AI开发者工具竞争白热化。
阅读全文 →
 教程攻略
教程攻略·12 分钟
Claude Code Router:免费用Gemini 2.5 Pro驱动Claude Code的完整教程
Claude Code Router让你在Claude Code中免费使用Gemini 2.5 Pro、DeepSeek等任意AI模型。本文详解安装配置、四种模型角色分配、插件系统及实际编程测试效果,帮你零成本打造顶级AI编程环境。
阅读全文 →
 教程攻略
教程攻略·10 分钟
免费调用Gemini 3 Pro API教程:Claude Code/Cherry Studio实战接入指南
详解通过Anti-Graffiti Tools免费调用Gemini 3 Pro API的完整教程,涵盖Claude Code、Gemini CLI、Cherry Studio三种实战接入方式,零成本使用对话、编码和图片生成功能。
阅读全文 →
 产品体验
产品体验·8 分钟
Cursor 1.0深度评测:MCP集成、BugBot、后台代理实测体验
Cursor 1.0正式版实测评测,深度解析一键MCP集成、BugBot代码审查、Background Agent后台代理三大核心功能,附定价分析与真实使用限制,帮助开发者判断是否值得升级。
阅读全文 →
 产品体验
产品体验·10 分钟
GLM-4.7深度实测:编程能力全面对标Claude Sonnet 4.5
深度实测智谱AI开源大模型GLM-4.7的编程能力,涵盖SVG动画、3D游戏开发、iOS原生APP开发、浏览器自动化等多维度测试,对比Claude Sonnet 4.5和DeepSeek V3.2,验证这款358B参数MOE模型的真实编程实力。
阅读全文 →
 产品体验
产品体验·9 分钟
Claude Haiku 4.5实测:速度虽快,性价比不敌GPT-5 Mini
实测对比Claude Haiku 4.5与GPT-5 Mini、GLM 4.6的速度、代码质量和价格。Haiku 4.5速度领先Sonnet 4一分钟,但输入价格是GPT-5 Mini的4倍,第三方评测编码得分落后9个点,性价比优势不明显。
阅读全文 →
 产品体验
产品体验·10 分钟
Claude Sonnet 4.5文档生成实测:一条提示词搞定Excel、Word与PPT
实测Claude Sonnet 4.5的代码执行与文件创建功能,详解如何用一条提示词自动生成Excel表格、Word报告和PPT演示文稿,附四大优化策略和三个完整实战案例。
阅读全文 →
 产品体验
产品体验·11 分钟
Claude 4.5 Sonnet实测:一条指令构建完整AI视觉应用
实测Anthropic最新Claude Sonnet 4.5编码能力,通过构建YOLO目标检测和Streamlit Web应用,验证其智能体编码实力。附基准测试对比、Claude Code工具链解析及开发者工作流建议。
阅读全文 →
 产品体验
产品体验·9 分钟
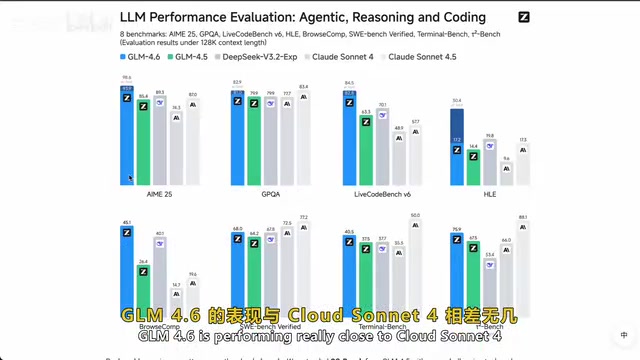
GLM-4.6深度实测:性能、价格与编程能力全面评估
深度实测智谱AI开源模型GLM-4.6,从MoE架构、编程实战、价格对比到适用场景全面解析。输入价格仅$0.06/百万Token,比Claude便宜7-20倍,一次生成代码无需调试,帮你判断是否值得纳入技术栈。
阅读全文 →
 产品体验
产品体验·9 分钟
Kimi K2 Thinking实测:Claude Code中能否平替Sonnet 4.5?
在Claude Code中实测Kimi K2 Thinking模型,从文本创作、编程开发、智能体构建到全栈应用多维度评测,对比Claude Sonnet 4.5和DeepSeek,分析其作为高性价比AI编程替代方案的真实表现。
阅读全文 →
 产品体验
产品体验·8 分钟
Claude 4.5 Haiku实测翻车:编码能力全面溃败,性价比被竞品碾压
独立测试者对Claude 4.5 Haiku进行全面实测,发现其在SVG生成、3D渲染、代理编码等任务中表现远低于预期。与GPT-5 Mini、GLM 4.6对比,性价比严重不足。深度分析Anthropic产品线困境与基准测试刷分隐忧。
阅读全文 →
 产品体验
产品体验·9 分钟
Claude Haiku 4.5评测:三分之一价格实现旗舰级AI性能
深度评测Anthropic Claude Haiku 4.5:SWE-bench编码得分73.3%碾压GPT-5和Gemini 2.5 Pro,智能体工具使用接近人类水平,价格仅为Sonnet 4.5的三分之一。附5项实战测试结果与企业应用场景分析。
阅读全文 →