#DeepSeek R1
共 50 篇相关文章
 教程攻略
教程攻略·8 分钟
RAG技术全链路解析:核心原理、企业落地与学习路径
深度解析RAG(检索增强生成)技术的核心原理、三大价值、企业落地案例与常见困境,并提供从基础到进阶的系统学习路线,涵盖向量数据库、检索策略优化、知识图谱融合等关键技术栈。
阅读全文 →
 教程攻略
教程攻略·9 分钟
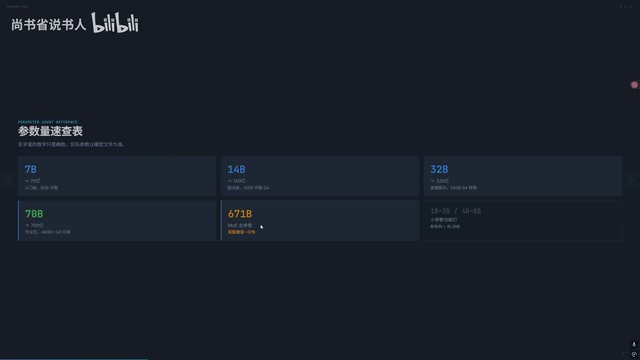
大模型命名规则解析:参数量、量化格式与显存需求速查
系统拆解大模型命名规则,解释32B参数量、AWQ/GGUF量化格式的含义,提供4-bit量化显存估算公式与速查表,涵盖MOE模型显存陷阱、IMatrix量化推荐及按显存档位的模型选择建议。
阅读全文 →
 产品体验
产品体验·3 分钟
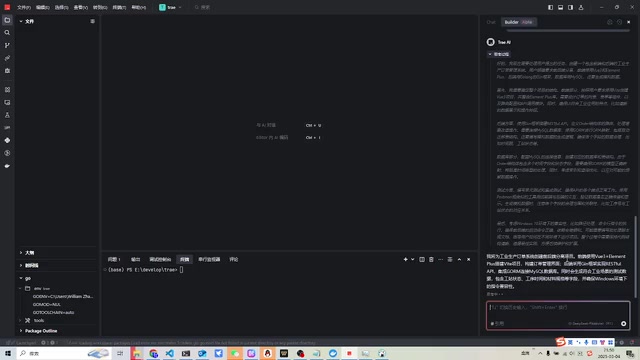
Trae Builder实测:字节跳动AI IDE能否一键生成全栈项目?
实测字节跳动AI IDE Trae的Builder功能,用Vue+Go+MySQL全栈项目验证其代码生成能力,对比Claude 3.7分析优劣,揭示当前AI原生IDE的真实水平与局限。
阅读全文 →
 产品体验
产品体验·6 分钟
Trae国内版深度测评:免费AI编程IDE实际体验与国际版对比
深度测评Trae国内版AI编程IDE,对比国际版在模型支持、代码生成、功能完整度等方面的差异。搭载DeepSeek和豆包大模型,免费无需翻墙,附实战代码生成测试结果。
阅读全文 →
 产品体验
产品体验·5 分钟
Trae下载安装教程:字节AI编程IDE完整体验评测
详细介绍字节跳动AI编程工具Trae的下载安装、界面功能及实际编程体验,支持Claude 3.7 Sonnet和DeepSeek R1满血版,免费使用的Cursor国产平替方案。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Claude Desktop国内使用教程:免登录对接DeepSeek等国产大模型
详细介绍Claude Desktop在国内免登录使用的完整教程,通过第三方API网关工具对接DeepSeek、Kimi等国产大模型,无需科学上网,一次配置即可长期使用,附配置步骤和常见问题解决方案。
阅读全文 →
 行业洞察
行业洞察·5 分钟
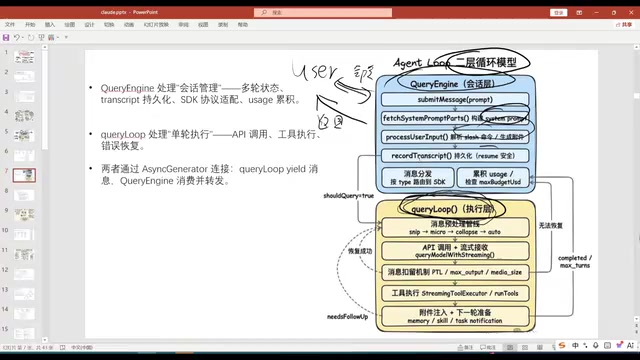
Claude Code开源解析:51万行代码揭秘工业级智能体架构
深度解析Claude Code开源项目的核心架构设计,包括双层循环执行引擎、七步工具安全管道、四层Token压缩策略、多智能体协作模式及记忆系统,为AI Agent开发提供工业级参考实现。
阅读全文 →
 产品体验
产品体验·6 分钟
pi-plugin-cc:让Claude Code一秒接入任意大模型
pi-plugin-cc是一款开源Claude Code插件,通过Pi编码Agent实现模型自由切换,支持DeepSeek、OpenAI、Ollama等任意大模型接入,帮助开发者降低成本、灵活调配AI编程资源。
阅读全文 →
 产品体验
产品体验·5 分钟
DeepSeek V4深度解析:混合注意力+流形约束+MOM优化器三大创新全解读
深度解析DeepSeek V4三大底层技术创新:混合注意力架构实现百万Token上下文、流形约束超连接稳定极深网络训练、MOM优化器加速收敛。V4 Pro性能对标Claude Opus 4.6,成本仅为其七分之一,附编程实测与部署方案。
阅读全文 →
 科技前沿
科技前沿·5 分钟
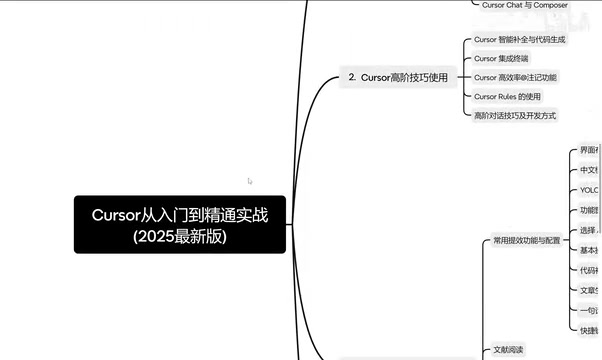
Cursor入门教程:2024主流AI编程工具对比与选型指南
全面对比Cursor、GitHub Copilot、Windsurf、Trae等主流AI编程工具的功能与优劣,帮助开发者快速选择适合自己的AI编程助手,附Cursor实战课程规划与工作流搭建建议。
阅读全文 →
 科技前沿
科技前沿·4 分钟
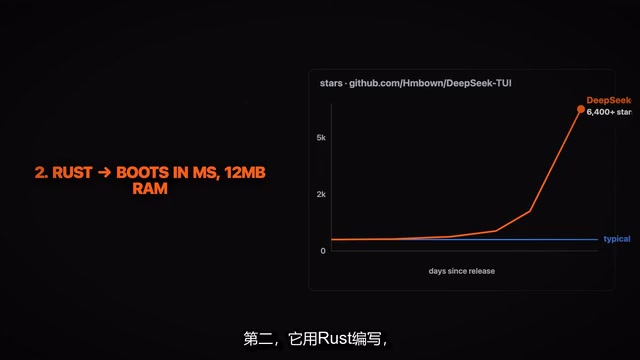
DeepSeek-TUI:免费Claude Code替代品,成本低20倍登顶GitHub
DeepSeek-TUI是用Rust编写的免费终端AI编程智能体,功能媲美Claude Code但成本低20倍。本文详解其核心功能、性能对比、适用场景,帮你判断是否值得从Claude Code迁移。
阅读全文 →
 教程攻略
教程攻略·7 分钟
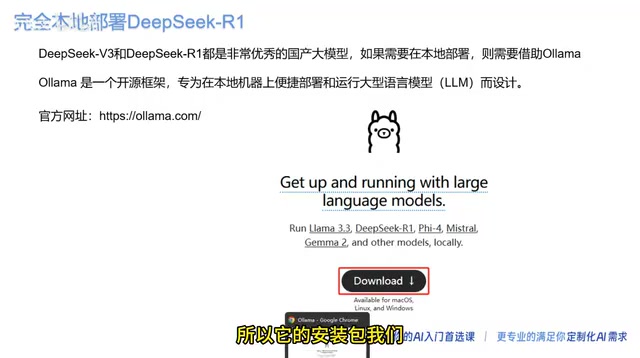
DeepSeek本地部署教程:Ollama一键安装运行指南
详细讲解如何通过Ollama在本地部署DeepSeek R1大模型,包括安装步骤、模型版本选择、硬件配置要求及进阶玩法,零基础10分钟搞定私有化AI部署。
阅读全文 →
 教程攻略
教程攻略·5 分钟
DeepSeek R1使用教程:提示词技巧与实战指南(2025)
详解DeepSeek R1推理模型使用方法与提示词技巧,涵盖推理模型与通用模型区别、五种需求表达公式、SPECTRAL任务分解法、新手常见误区及知识唤醒策略,助你快速掌握DeepSeek R1高效用法。
阅读全文 →
 教程攻略
教程攻略·4 分钟
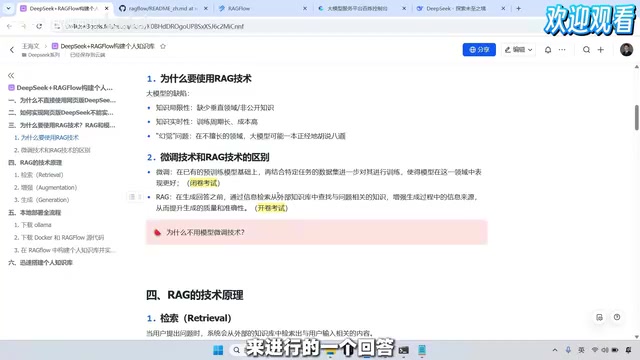
DeepSeek+RAGFlow本地部署AI知识库教程(2025最新)
手把手教你用DeepSeek+RAGFlow+Ollama本地部署个人AI知识库。涵盖RAG原理解析、Ollama安装、Docker部署RAGFlow、知识库创建与调优全流程,数据完全私有,零基础可上手。
阅读全文 →
 深度解读
深度解读·6 分钟
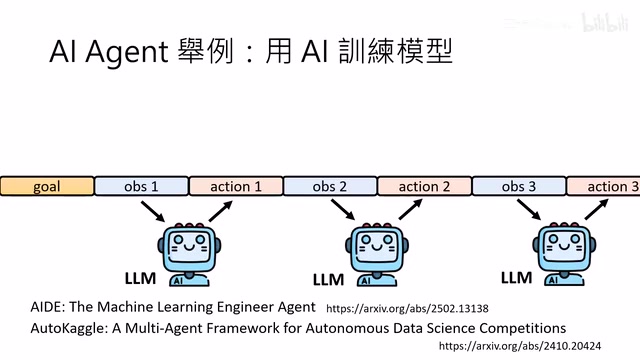
李宏毅2026课程笔记:AI Agent三大核心能力深度解析
李宏毅2026年AI Agent课程精华整理,详解AI Agent的定义、LLM驱动原理,以及Memory记忆机制、工具使用(Function Calling)、规划能力(Tree Search)三大核心能力,附实际应用案例与最新研究发现。
阅读全文 →
 产品体验
产品体验·13 分钟
DeepClaude开源解析:DeepSeek+Claude双模型协同代码生成
深度解析GitHub 2800+ Star开源项目DeepClaude的技术架构。通过DeepSeek R1推理+Claude 3.7 Sonnet代码生成的双模型协同方案,实现更高质量的AI代码输出,附工程实现亮点与局限性分析。
阅读全文 →
 教程攻略
教程攻略·9 分钟
Google AI Studio使用教程:Gemini实战指南从入门到精通
详解Google AI Studio与Gemini三种使用方式,涵盖YouTube视频解析、语音生成、Imagen 4文生图、Gemini Live多模态交互及一句话造App等核心功能,助你打造高效AI工作流。
阅读全文 →
 教程攻略
教程攻略·9 分钟
OpenAI开源GPT-OSS:16G显存跑O4级模型,部署教程全解析
OpenAI正式开源GPT-OSS系列模型(20B/120B),采用MOE架构+FP4混合精度,单卡4090即可运行O3级推理模型。本文详解核心技术、性能评测及Ollama/vLLM等四种本地部署方案。
阅读全文 →
 教程攻略
教程攻略·11 分钟
NVIDIA免费调用DeepSeek V4 Pro教程:API密钥获取与编程工具接入
手把手教你通过NVIDIA NIM平台免费获取DeepSeek V4 Pro和V4 Flash API密钥,包含模型参数对比、OpenAI兼容接口配置、Cursor/Kline等编程工具接入方法及推理努力值调优技巧。
阅读全文 →
 深度解读
深度解读·8 分钟
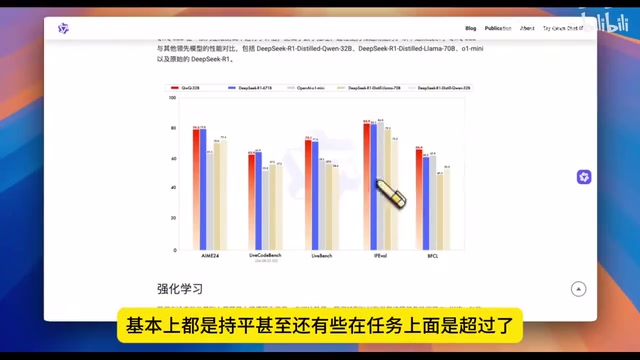
阿里QwQ-32B开源:32B参数如何媲美671B的DeepSeek R1
阿里开源推理模型QwQ-32B仅用32B参数,在多项基准测试中媲美甚至超越DeepSeek R1满血版(671B)。本文深度解析其两阶段强化学习训练策略、性能对比数据,以及强化学习带来的能力涌现现象,揭示小参数模型以小博大的核心秘密。
阅读全文 →