#MoE model
17 related articles
·2 min
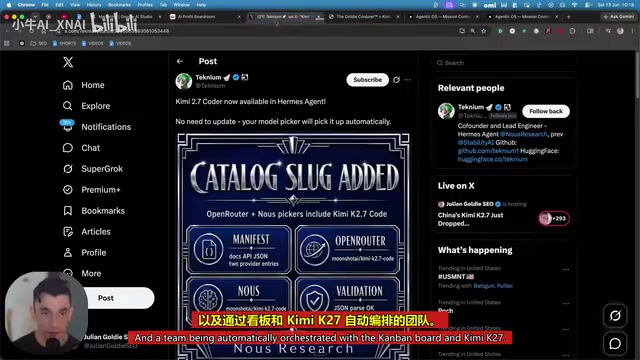
Kimi K2.7 + Hermes Agent Real-World Test: Generate Complete Applications with a Single Sentence
Hands-on test of Kimi K2.7 integrated with Hermes Agent: generate complete 3D games and web OS apps from a single sentence, with benchmark data vs Claude 3.5.
Read more →

·4 min
Cursor Composer2 Training Revealed: A Complete Guide to Distributed Reinforcement Learning Engineering
Deep dive into how Cursor trained Composer2: two-stage architecture, global distributed clusters, MOE numerical alignment, simulation anti-cheating, and more.
Read more →

·3 min
vLLM Deep Dive: How PagedAttention Enables High-Throughput LLM Inference
Deep dive into vLLM's core technologies for high-throughput LLM inference, including PagedAttention memory management, continuous batching, distributed deployment, and comparisons with TensorRT-LLM.
Read more →
 Product Reviews
Product Reviews·3 min
Google Gemma 4 Hands-On Review: Offline on Smartphones + Ollama Deployment Tutorial
Hands-on testing of Google Gemma 4 open-source models running offline on three phones, with Dense vs MOE architecture explained and a complete Ollama + Claude Code deployment tutorial.
Read more →
 Tutorials
Tutorials·3 min
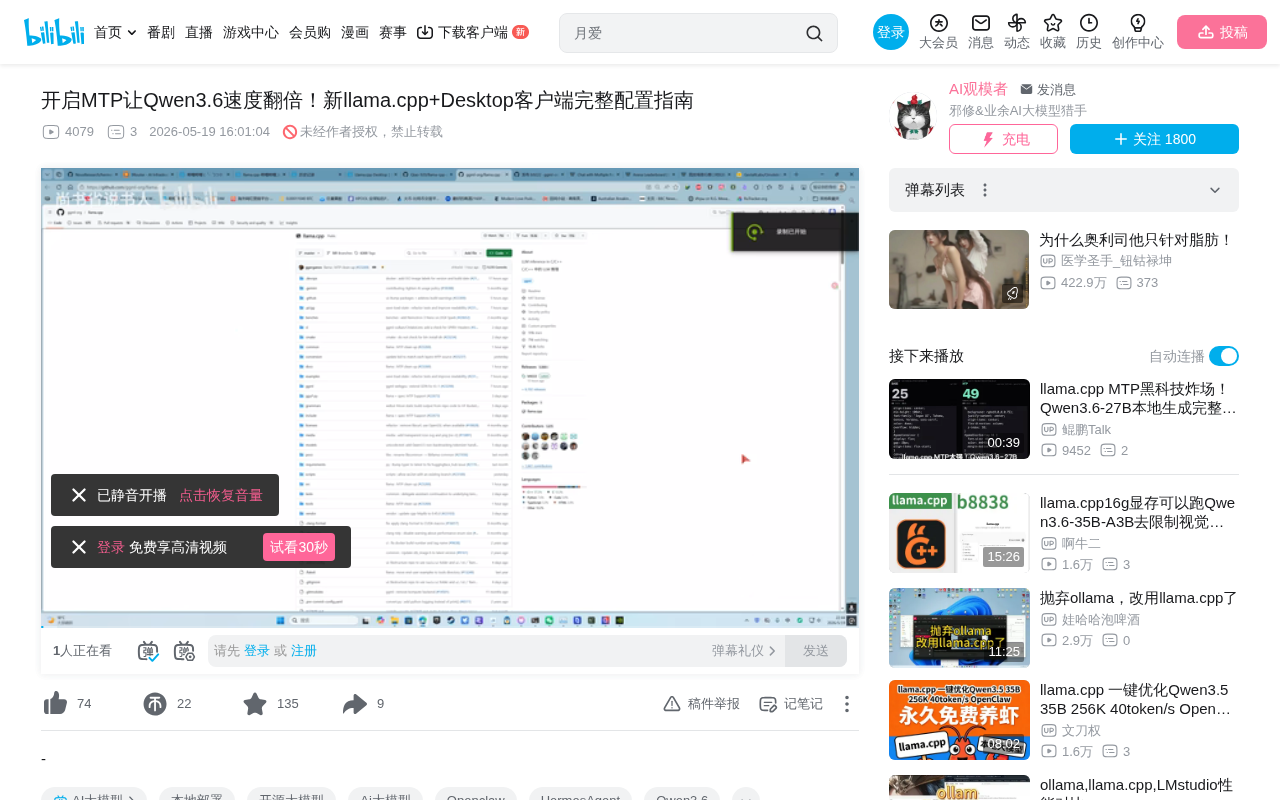
llama.cpp MTP Acceleration Deployment Guide: Configuration Steps & Real-World Benchmarks
Guide to enabling MTP multi-Token prediction acceleration in llama.cpp, covering CUDA setup, desktop configuration, model selection, and benchmarks showing ~60 Token/s with Qwen3 27B.
Read more →
 Tutorials
Tutorials·2 min
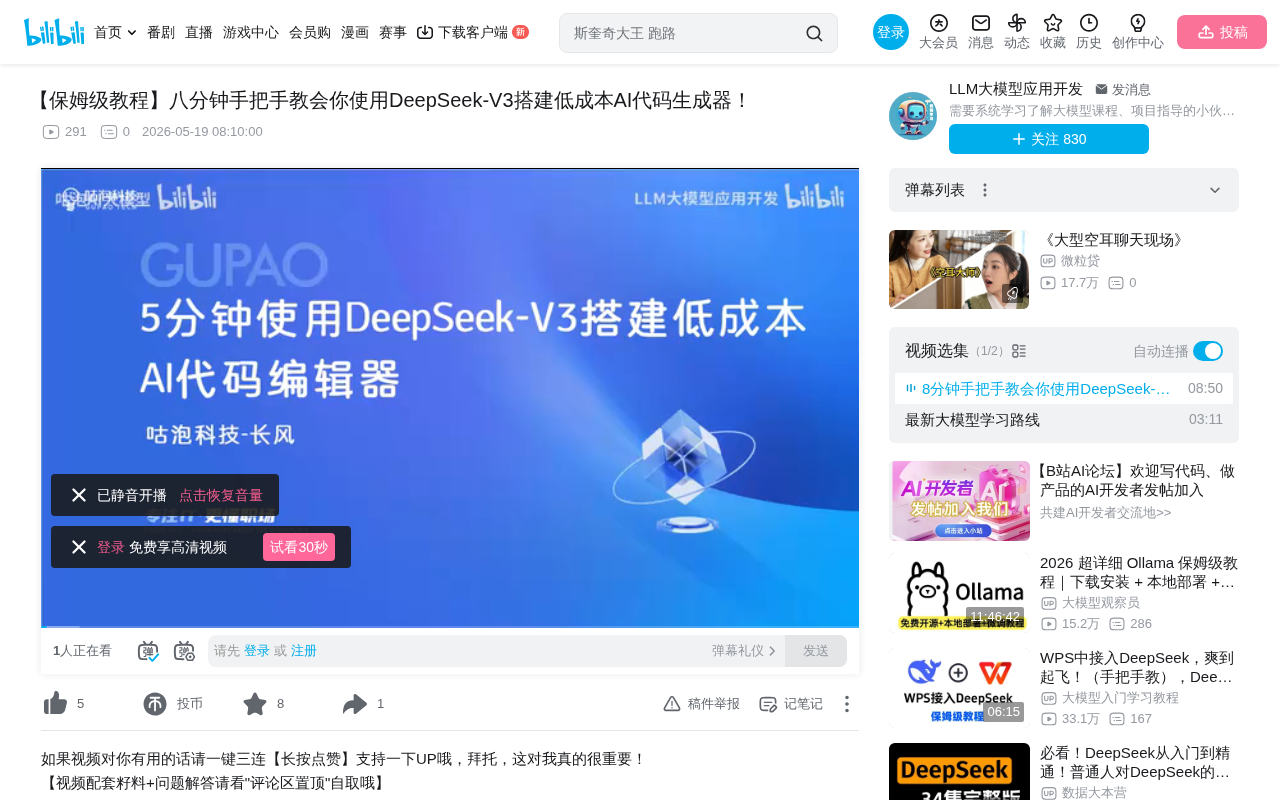
Tutorial: Building a Low-Cost AI Code Editor with DeepSeek-V3 + VSCode
Step-by-step tutorial: Build a low-cost AI programming assistant using DeepSeek-V3 API with VSCode's Continue plugin. Covers setup, API Key configuration, code completion demo, and Ollama local deployment.
Read more →
 Tutorials
Tutorials·3 min
oMLX + MTP + Qwen3.6: Local AI Coding Speed Breaks New Records
Using oMLX with MTP and Qwen3.6 35B on Apple Silicon Mac to achieve 86.7 tokens/s local coding speed, building a full-stack app in under 5 minutes.
Read more →
Tech Frontiers
AI Weekly: Claude Code Review, Gemma 4…
·3 min
AI Weekly: Claude Code Review, Gemma 4 Leak & DeepSeek V4 Delayed
Weekly AI roundup: Anthropic launches Claude Code review, Google Gemma 4 leaks with MoE architecture, DeepSeek V4 delayed again, Microsoft Copilot Cowork reshapes collaboration, and OpenAI acquires PromptFool.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
SGLang v0.5.12.post1 Released: DeepSeek V4 Stability Fixes and Blackwell Adaptation
SGLang v0.5.12.post1 stability patch details: 12 critical fixes covering DeepSeek V4 garbled text and crashes, NIXL PD disaggregated inference logic, Blackwell B300 adaptation, and cold start optimization.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
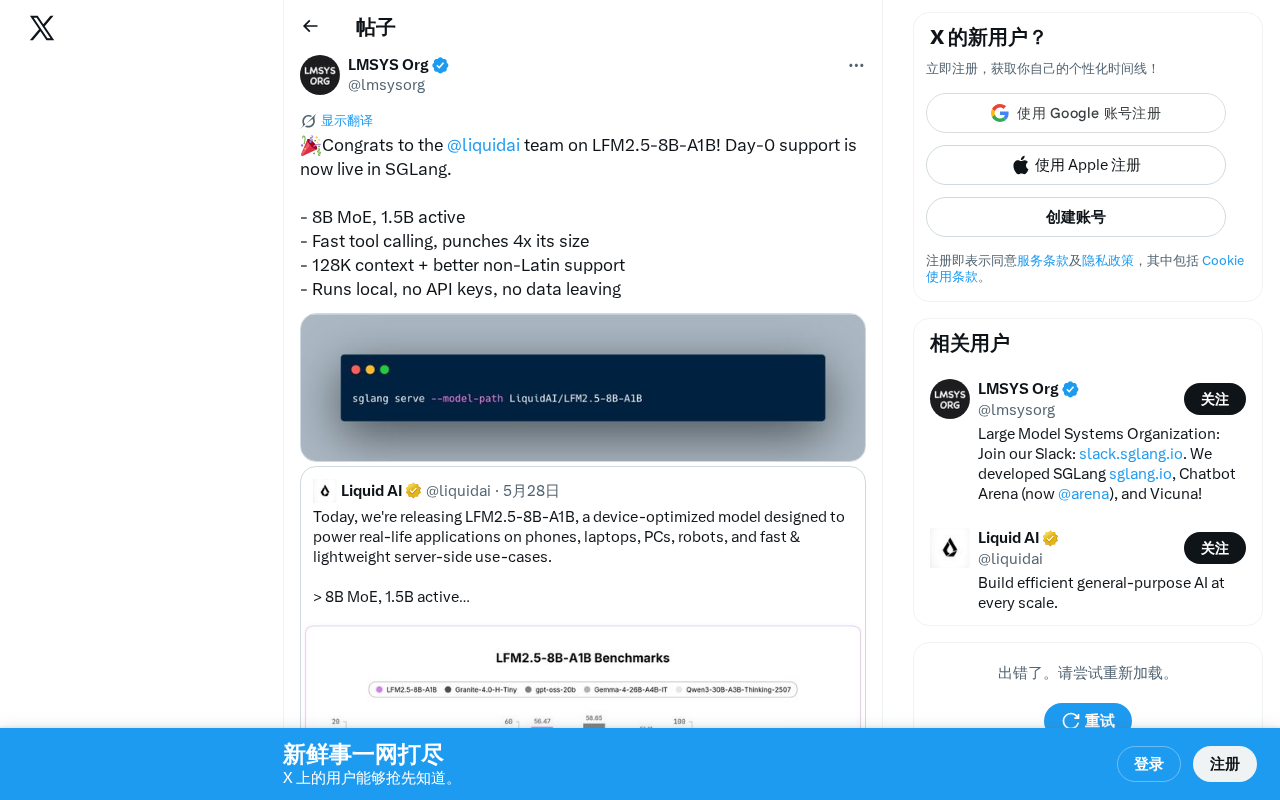
LFM2.5-8B-A1B: A MoE Model with 1.5B Active Parameters Delivering 4x Its Weight Class Performance
Liquid AI releases LFM2.5-8B-A1B, a MoE model with 8B total params but only 1.5B active, matching 6B-class models in tool calling. Supports 128K context, local deployment, multilingual, with SGLang Day-0 support.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
Cloudflare Contributes Critical KV Cache and Mooncake Fixes to SGLang
Cloudflare contributes decode KV cache offload and Mooncake recovery fixes to SGLang, resolving garbled output under high concurrency for Kimi K2.6 and enabling automatic fault recovery in distributed inference.
Read more →
Industry Insights
Deep Dive into Three Major LLM Career …
·3 min
Deep Dive into Three Major LLM Career Paths: Requirements, Tech Stacks, and Career Prospects
Deep analysis of three core LLM roles—Application Engineer, Development Engineer, and Algorithm Engineer—covering technical requirements, salary thresholds, and career prospects including RAG, fine-tuning, and inference deployment.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
AI Weekly: Kimi K2.6 Tops Open-Source Rankings, Qwen 3.6 and Google TTS Launch Together
Weekly AI roundup: Kimi K2.6 tops open-source rankings, Anthropic launches Opus 4.7 and Claude Design, Alibaba rolls out Qwen 3.6 series, Google releases emotion-controllable TTS model.
Read more →
Product Reviews
Qwen 3.6 vs Gemma 4: In-Depth Comparis…
·3 min
Qwen 3.6 vs Gemma 4: In-Depth Comparison of Local AI Coding Models Through Real-World Development
Real-world comparison of Qwen 3.6 and Gemma 4 local AI models building a Markdown editor with Tauri, testing planning ability, code generation, and development efficiency.
Read more →
Product Reviews
Running Qwen3.6-27B Locally on Mac: 4 …
·3 min
Running Qwen3.6-27B Locally on Mac: 4 Solutions Benchmarked
Benchmarking 4 solutions for running Qwen3.6-27B locally on Mac: GGUF, MLX Diflash, and MTP-LX. MTP-LX 4bit leads at 43.6 tok/s with solid coding, writing, and reasoning quality.
Read more →
Tutorials
Decoding LLM Naming Conventions: Param…
·3 min
Decoding LLM Naming Conventions: Parameter Counts, Quantization Formats & VRAM Requirements Quick Reference
Decode LLM naming conventions, understand 32B parameters & AWQ/GGUF quantization formats, with 4-bit VRAM estimation formulas, MOE model pitfalls, and model selection by GPU tier.
Read more →
 Product Reviews
Product Reviews·1 min
MiniMax M2.5 Hands-On Review: How 10B Parameters Deliver Flagship-Level Coding Performance
Hands-on review of MiniMax M2.5's coding performance in Claude Code, including 3D game dev and AI translation platforms, compared to Claude Opus and GPT-5.2.
Read more →