#低显存
共 36 篇相关文章

·9 分钟
vLLM深度解析:PagedAttention如何实现高吞吐量LLM推理
深入解析vLLM高吞吐量LLM推理引擎的核心技术,包括PagedAttention内存管理、连续批处理机制、分布式部署方案,以及与TensorRT-LLM等方案的对比和适用场景建议。
阅读全文 →
 教程攻略
教程攻略·8 分钟
Agent Tuning:训练具备Agent能力的大模型完整指南
深入解析Agent Tuning的原理与实践,包括为什么需要Agent训练、从Prompt到RAG到Agent的技术演进、研发流程与成本评估,帮助中小模型获得顶级Agent能力实现私有化部署。
阅读全文 →
 科技前沿
科技前沿·7 分钟
DeepSeek-V3.2发布:编程与数学能力跻身全球第一梯队
DeepSeek-V3.2版本发布,编程、数学和Agent开发能力追平Gemini 3.0 Pro,刷新开源模型SOTA记录。本文详解V3.2性能提升亮点、适用场景及部署建议。
阅读全文 →
 教程攻略
教程攻略·5 分钟
Gemma 4全面解析:Apache 2.0开源的Agent圣体
深度解析Google Gemma 4开源模型系列,涵盖31B、26B MOE、14B/12B三档模型红黑榜评测,提供Windows/Linux/Mac部署方案及MS-Swift微调实战教程,助你精准选型构建本地Agent工作流。
阅读全文 →
 教程攻略
教程攻略·9 分钟
一人管三机:本地Agent部署与多机协同运维实战
通过部署Cloud Code和Hermes等多个AI Agent,实现一人管理三台物理主机的高效运维。详解Ventoy单文件部署方案、BTRFS+RAW Image技术选型、Agent分工策略与风险控制,打造最小代价最大产出的个人运维体系。
阅读全文 →
 教程攻略
教程攻略·4 分钟
AI大模型学习路线:从零到工程师的六个阶段
系统梳理AI大模型工程师学习路线,涵盖Transformer基础、提示词工程、RAG检索增强生成、Agent智能体开发、API调用、微调部署到项目实战六大阶段,帮助开发者高效掌握大模型核心技能。
阅读全文 →
 深度解读
深度解读·9 分钟
DeepSeek V4技术深度拆解:百万Token与极致性价比
深入解析DeepSeek V4核心技术架构,包括混合压缩注意力机制、流形约束超链接和MUON优化器三大创新,详解其如何将推理成本降低10倍,实现百万Token长上下文处理,以及MIT开源协议带来的生态价值。
阅读全文 →
 深度解读
深度解读·10 分钟
Transformer架构核心原理:自注意力机制与工程优化深度解析
深度解析Transformer架构核心原理,涵盖自注意力机制QKV本质、Encoder-Decoder结构、Flash Attention显存优化、RoPE位置编码、GQA推理加速等工程落地方案,助你从面试到实战全面掌握大模型底层架构。
阅读全文 →
 教程攻略
教程攻略·8 分钟
Stable Diffusion本地部署教程:8GB内存免费运行AI绘画
详解Stable Diffusion本地部署完整流程,包括硬件要求、一键安装步骤、模型配置方法。8GB内存即可零成本运行AI图像生成,附优势局限分析与配置建议。
阅读全文 →
 教程攻略
教程攻略·7 分钟
PyCharm配置本地DeepSeek模型实现AI辅助编程完整教程
详细介绍如何通过Ollama在PyCharm中配置本地DeepSeek模型,实现免费、隐私安全的AI辅助编程。包含安装步骤、插件配置、使用技巧及硬件建议。
阅读全文 →
 教程攻略
教程攻略·9 分钟
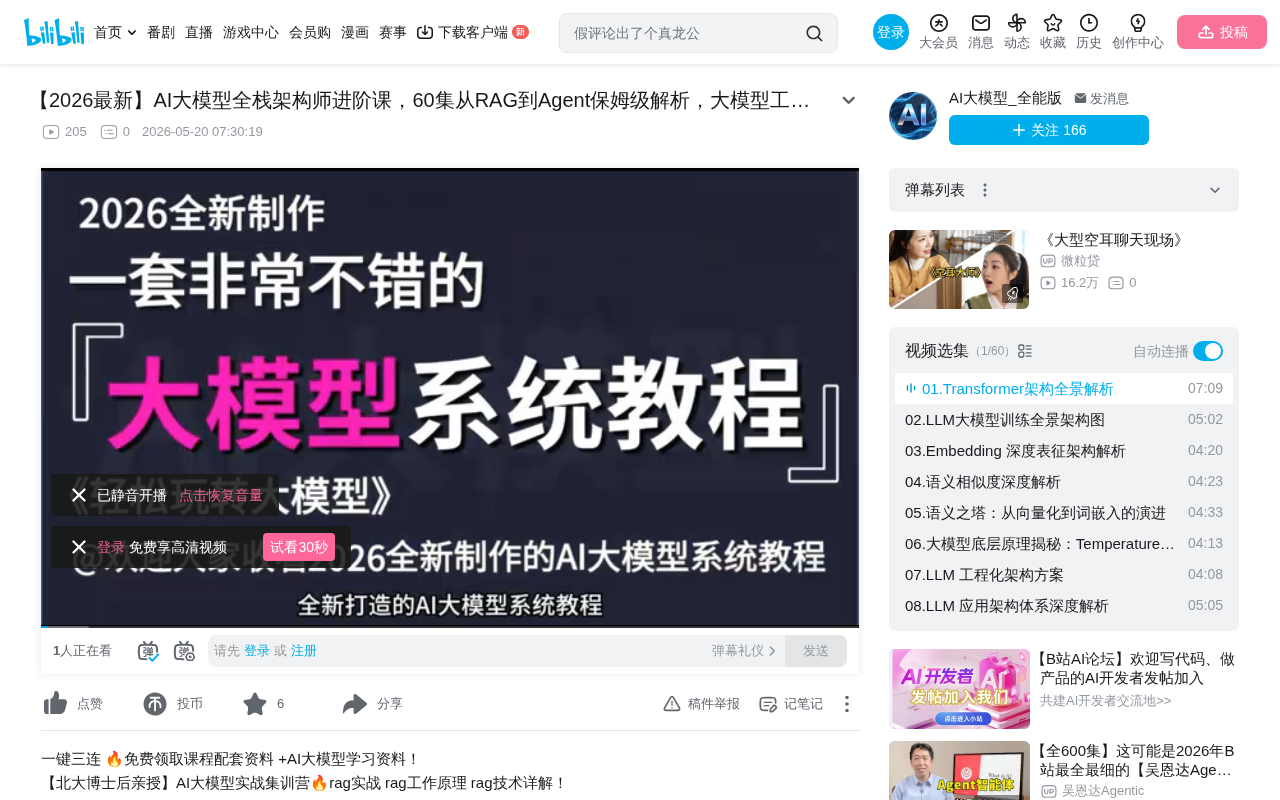
大模型命名规则解析:参数量、量化格式与显存需求速查
系统拆解大模型命名规则,解释32B参数量、AWQ/GGUF量化格式的含义,提供4-bit量化显存估算公式与速查表,涵盖MOE模型显存陷阱、IMatrix量化推荐及按显存档位的模型选择建议。
阅读全文 →
 行业洞察
行业洞察·6 分钟
NVIDIA Blackwell创下金融LLM推理STAC-AI新纪录
NVIDIA Blackwell架构GPU在金融行业权威基准STAC-AI中刷新LLM推理性能纪录。深入解析Blackwell架构优势、TensorRT-LLM软硬件协同优化策略,以及大语言模型在金融交易情绪分析、风控合规等场景的应用前景。
阅读全文 →
 教程攻略
教程攻略·7 分钟
Ollama本地部署大模型完全指南:断网也能用的AI
详解Ollama本地部署开源大模型的完整流程,涵盖安装配置、模型选择、显存要求及实际效果对比。支持Llama 3、通义千问等主流模型,零成本、断网可用,轻松打造私有AI工作站。
阅读全文 →
 教程攻略
教程攻略·6 分钟
免费使用Claude Code:CC Switch+Ollama本地模型驱动AI编程Agent教程
详细教程教你通过CC Switch将本地Ollama模型伪装成Claude API,零成本驱动Claude Code桌面版进行AI编程。涵盖安装配置、模型选择、实测效果,支持千问、Gemma等开源模型。
阅读全文 →
 教程攻略
教程攻略·6 分钟
本地部署大模型怎么判断显存爆了?一文看懂显存监控方法
本地部署大模型时如何判断显存是否爆满?本文详解专用显存与共享GPU内存的区别,教你通过任务管理器快速判断显存溢出,并提供模型量化、上下文长度控制等避免爆显存的实用建议。
阅读全文 →
 行业洞察
行业洞察·5 分钟
企业大模型选型指南:Llama3.1、Qwen2.5、DeepSeek深度对比
企业如何选择开源大模型?本文从模型能力、硬件需求、业务场景三个维度,深度对比Llama 3.1、Qwen 2.5、DeepSeek、Mistral等主流开源模型,提供选型决策框架与实践建议。
阅读全文 →
 产品体验
产品体验·8 分钟
Pixal3D实测对比Tripl3/Trellis/Hunyuan:像素级对齐优劣全解析
深度实测腾讯开源3D生成模型Pixal3D,解析像素级对齐技术原理,与Trellis 2、Hunyuan、Tripl3多组对比评测。涵盖本地部署教程、24GB显存需求、优劣势分析及商业许可争议解读。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Anima二次元大模型:6G显存本地部署与工作流配置教程
详解Anima二次元动漫AI绘图大模型的本地部署方法,仅需6G显存即可流畅运行。涵盖ComfyUI工作流配置、文生图参数设置、高清放大技巧及低显存优化建议,适合中低端显卡用户。
阅读全文 →
 教程攻略
教程攻略·11 分钟
NCCL Inspector详解:GPU集群通信实时监控与Prometheus集成实践
深入解析NVIDIA NCCL Inspector工具,介绍其与Prometheus深度集成实现GPU集群通信实时监控的方案,涵盖慢节点定位、告警配置、Grafana可视化等实际应用场景,助力大规模分布式训练性能优化。
阅读全文 →
 教程攻略
教程攻略·11 分钟
NVIDIA Model Optimizer训练后量化(PTQ)实战指南
深入解析NVIDIA Model Optimizer训练后量化(PTQ)工作流,涵盖INT8/INT4量化原理、校准方法、RTX GPU优化策略及大语言模型量化部署最佳实践,助你在消费级显卡上高效运行大模型。
阅读全文 →