#参数
共 1677 篇相关文章
 教程攻略
教程攻略·6 分钟
本地部署大模型怎么判断显存爆了?一文看懂显存监控方法
本地部署大模型时如何判断显存是否爆满?本文详解专用显存与共享GPU内存的区别,教你通过任务管理器快速判断显存溢出,并提供模型量化、上下文长度控制等避免爆显存的实用建议。
阅读全文 →
 观点碰撞
观点碰撞·5 分钟
AI代码生成越快项目死越快:信任工程才是真正瓶颈
AI编程让代码生成成本归零,但验证代码正确性才是终极瓶颈。GitClear数据显示AI编程导致复制粘贴率暴增10倍,Vibe Coding正在制造技术债。开发者需要从写代码转向验证代码,掌握TDD、防御性架构和形式化验证,才能真正驾驭AI生产力。
阅读全文 →
 观点碰撞
观点碰撞·4 分钟
一人公司如何用AI集群实现算力跃迁?从执行者到决策者的实操指南
独立开发者如何利用AI集群打造一人公司?本文从自动化代理构建、信息降维套利、生物节律优化三大模块,拆解AI时代个体从执行者跃迁为决策者的完整方法论与实操路径。
阅读全文 →
 教程攻略
教程攻略·5 分钟
AI大模型辅助逆向工程实战:抖音加密参数分析与环境补全
探讨如何用DeepSeek等AI大模型辅助逆向工程,实战分析抖音X-Bogus加密参数,自动生成600多行环境补全代码,涵盖原型链检测、属性描述符、函数保护等关键绕过方案,附实际验证效果与协作技巧。
阅读全文 →
 产品体验
产品体验·7 分钟
Codex vs Kiro vs Coder实测对比:2025年AI编程工具怎么选
通过统一的HTML小游戏生成测试,实测对比OpenAI Codex、亚马逊Kiro和国产Coder三款主流AI编程工具的代码质量、游戏完整度和实际表现,附详细评分与选择建议。
阅读全文 →
 产品体验
产品体验·5 分钟
XREAL Project Aura深度解析:Android XR眼镜的最佳形态?
XREAL Project Aura是Google I/O 2025上最受关注的Android XR眼镜,配备70度视场角、电致变色镜片和外置计算模块。本文深度解析其硬件设计、开发者生态与市场前景,探讨这款轻量级XR眼镜能否成为通往大众市场的最优解。
阅读全文 →
 深度解读
深度解读·4 分钟
Gemini 3.5 Flash深度解析:Google打造的AI Agent执行引擎
Google I/O 2025发布Gemini 3.5 Flash,速度比前沿模型快4倍,编码与Agent基准超越自家旗舰。本文深度解析其子Agent协作、高频迭代循环等核心能力,以及对AI Agent行业格局的影响。
阅读全文 →
 科技前沿
科技前沿·3 分钟
Gemini 3.5 Flash发布:Google如何平衡AI模型速度与能力
Google发布Gemini 3.5 Flash模型,主打速度与能力的最佳平衡。本文解析Flash系列定位演进、与GPT-4o mini等竞品对比,以及对开发者和企业用户的实际应用价值。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Gemini 3.5免费使用教程:国内无需翻墙直连方案
详解国内免费使用Gemini 3.5的方法,无需翻墙、无需注册即可体验。实测Gemini 3.5代码生成能力,对比3.1版本生成《我的世界》网页游戏的惊人差距,附多模型聚合平台使用建议与风险提示。
阅读全文 →
 产品体验
产品体验·4 分钟
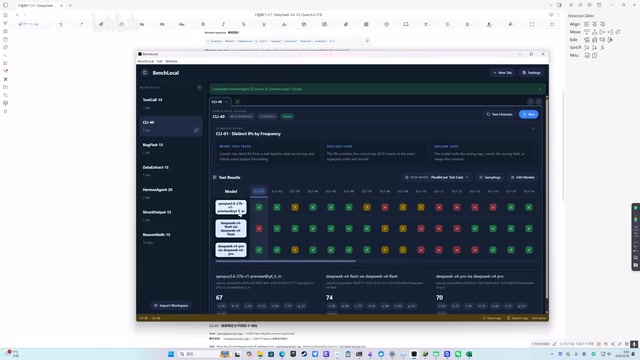
DeepSeek V4 vs Qwen3.6实测:8大类150场景深度对比评测
使用BenchLocal工具对DeepSeek V4 Pro、V4 Flash与Qwen3.6 27B进行8大类85场景实测对比,涵盖工具调用、代码调试、推理数学等维度,V4 Pro总分领先6%但数学推理意外翻车,Qwen3.6 Q6在智能体场景媲美V4 Pro。
阅读全文 →
 产品体验
产品体验·4 分钟
Qwen3.6-27B开源模型评测:27B参数实现旗舰级代码与多模态能力
阿里Qwen3.6-27B开源模型深度解析:270亿参数稠密架构,单卡即可部署,代码生成能力超越前代旗舰。本文详解其技术优势、基准测试成绩、硬件配置方案及实际部署建议,助你低成本获得旗舰级AI编程与多模态理解能力。
阅读全文 →
 产品体验
产品体验·4 分钟
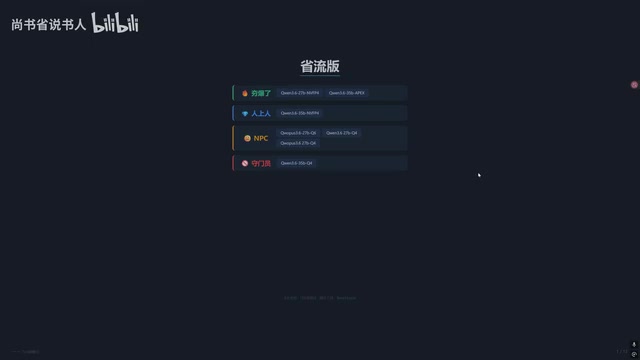
Qwen3.6量化版本地部署实测:NVFP4、APEX、Q4、Q6哪个最值得选
实测Qwen3.6系列7-8个量化模型在工具调用、命令行操作、Bug修复、数学推理等8大维度的表现,对比NVFP4、APEX、Q4、Q6量化方案,附总分排名与选购建议,帮你找到最适合本地部署的量化版本。
阅读全文 →
 产品体验
产品体验·3 分钟
开源AI桌宠小猫:Qwen 3.5 Omni+ESP32打造全模态智能伙伴
基于Qwen 3.5 Omni全模态模型和ESP32-S3的开源AI桌宠小猫项目,支持情感语音交互、视觉感知、手势互动和一日记录复盘功能。附完整复刻教程,含硬件清单、3D打印模型和代码烧录指南。
阅读全文 →
 科技前沿
科技前沿·3 分钟
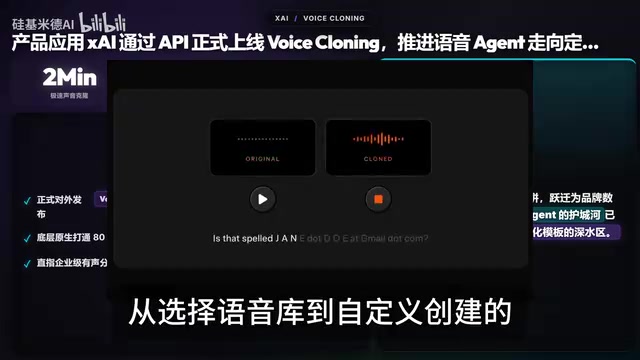
Qwen3.6 35B开源实测逼近Claude,xAI语音克隆API正式上线
阿里开源Qwen3.6 35B模型,256专家MoE架构仅需3B激活参数,SWE Bench成绩逼近Claude Opus。xAI发布Voice Cloning API支持28种语言,NVIDIA开源OpenShell安全沙箱,Sam Altman表态模型智力优先。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Hermes + Qwen3.6 本地部署教程:零成本搭建私有AI Agent
详细教程教你用Hermes Agent搭配Qwen3.6开源大模型,在本地零成本部署私有AI助手。涵盖WSL环境配置、模型下载启动、Telegram机器人对接及开机自启设置,实现无限Token、数据私有的AI Agent体验。
阅读全文 →
 产品体验
产品体验·4 分钟
Qwen3.6 27B三大邪修量化模型实测:代码暴增15.8PP、40B蒸馏、16GB适配
实测对比三款基于Qwen3.6 27B的社区邪修量化模型:OmniMerge V4代码能力提升15.8个百分点,40B OPUS蒸馏版支持角色扮演与创意写作,16GB特化版让小显存也能跑稠密模型。附显存要求、参数设置与选型建议。
阅读全文 →
 科技前沿
科技前沿·2 分钟
悟空2.2P开源:35B MOE模型性能超越Qwen3.6-27B,速度快3-5倍
悟空2.2P 35B MOE模型正式开源,采用对抗式杂交蒸馏技术,综合性能超越Qwen3.6-27B。4090显卡Q5量化达158 tokens/s,仅需8.9G显存即可运行,支持256K上下文。详解核心技术、硬件配置与实测数据。
阅读全文 →
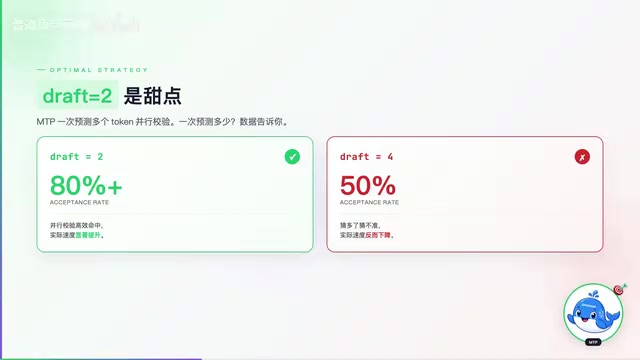 科技前沿
科技前沿·4 分钟
Qwen3.6 MTP加速实测:单GPU推理飙到220 token/s
Qwen3.6实验性MTP-GGUF版本实测,单GPU将35B-A3B模型推理速度提升至220 token/s,比原版快1.4倍且精度零损失。详解MTP原理、最优Draft Tokens策略及RTX 5090实测数据。
阅读全文 →
 行业洞察
行业洞察·5 分钟
企业大模型选型指南:Llama3.1、Qwen2.5、DeepSeek深度对比
企业如何选择开源大模型?本文从模型能力、硬件需求、业务场景三个维度,深度对比Llama 3.1、Qwen 2.5、DeepSeek、Mistral等主流开源模型,提供选型决策框架与实践建议。
阅读全文 →
 深度解读
深度解读·4 分钟
Qwen3.5深度解析:混合注意力架构实现19倍长上下文加速
深入解析阿里开源Qwen3.5模型的混合注意力架构创新,详解Gated Delta Net如何实现256K上下文19倍加速,多模态视觉反超Gemini 3 Pro和GPT-5.2的评测数据,以及RL后训练策略与实际应用Demo。
阅读全文 →