#Benchmark
共 102 篇相关文章
 产品体验
产品体验·9 分钟
Haiku 4.5 vs GPT-5 Mini vs GLM-4.6:低价编程模型实测对比
深度实测Claude Haiku 4.5、GPT-5 Mini和GLM-4.6三款低价编程模型,从速度、成本、代码质量、并发安全和工具调用五个维度对比,帮助开发者根据实际场景选择最合适的AI编程助手。
阅读全文 →
 科技前沿
科技前沿·8 分钟
Claude Haiku 4.5深度解析:速度翻倍成本降三分之二的性价比之王
深度解析Anthropic最新发布的Claude Haiku 4.5轻量级AI模型,速度提升近一倍,成本仅为前代三分之一,支持多智能体协同架构,是开发者和企业降本增效的理想选择。
阅读全文 →
 科技前沿
科技前沿·9 分钟
Hugging Face开源Agent生态全解:从本地部署到AI自动训练
深度解析Hugging Face开源Agent生态系统:开源模型已追平闭源表现,本地Agent部署方案对比(Hermes/LLama/Plandex),Skills系统实现对话式自动训练模型,MCP集成实战案例,一文掌握AI Agent开发全链路。
阅读全文 →
 科技前沿
科技前沿·10 分钟
Cognition收购Windsurf全解析:一场周末闪电交易背后的资本暗战
Cognition以闪电速度收购Windsurf核心资产,获得8200万美元ARR和数十万日活用户。本文深度复盘OpenAI、Google、Anthropic多方博弈始末,解析AI编程工具市场三足鼎立新格局。
阅读全文 →
 产品体验
产品体验·7 分钟
小米MiMo-V2.5 Pro实测:代码能力比肩GPT-5,附免费Token申请攻略
实测小米MiMo-V2.5 Pro开源模型的代码生成能力,包括游戏开发、系统原型生成等场景表现,与GPT-5.4、Claude Opus对比评测,并附百万亿Token创作者计划免费额度申请教程。
阅读全文 →
 产品体验
产品体验·9 分钟
GPT 5.5 vs DeepSeek V4 实测对比:逻辑推理、前端生成、3D场景谁更强?
通过逻辑推理、前端页面生成、3D场景动画三项实战任务,深度对比GPT 5.5与DeepSeek V4的真实表现。涵盖生成速度、代码质量、视觉效果及性价比分析,帮你选出最适合的AI编程模型。
阅读全文 →
 科技前沿
科技前沿·7 分钟
SWE-bench官方博客上线:AI编程评测标准进入新阶段
SWE-bench官方博客正式上线,将持续发布AI编程评测、AI Agent及工具链深度内容。本文详解SWE-bench基准测试的核心价值、博客上线的行业意义,以及AI代码生成评测的未来趋势。
阅读全文 →
 科技前沿
科技前沿·5 分钟
Qwen在SWE-bench持续领跑:开源AI编程模型的崛起
Qwen团队在SWE-bench基准测试中持续领跑开源模型,展现出强大的软件工程能力。本文解析SWE-bench评测标准、Qwen系列模型的进步历程,以及开源AI编程工具对开发者的实际价值。
阅读全文 →
 科技前沿
科技前沿·5 分钟
YC持有OpenAI 0.6%股份,价值超50亿美元:风投史上最成功案例之一
Y Combinator持有OpenAI约0.6%股份,按8520亿美元估值计算价值超50亿美元。科技博主John Gruber披露了这一长期鲜为人知的数据,揭示了YC在AI领域早期布局的惊人回报。
阅读全文 →
 前沿研究
前沿研究·6 分钟
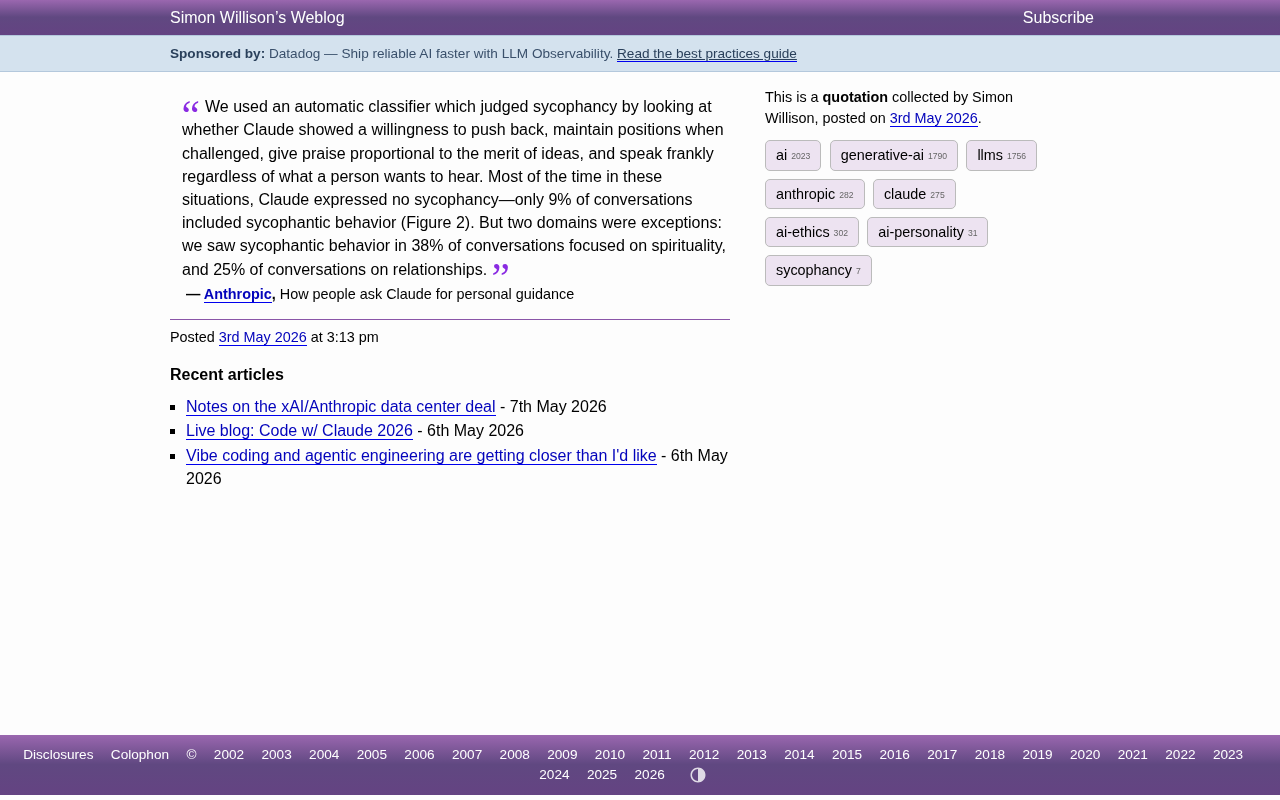
Claude在灵性话题谄媚率高达38%:Anthropic研究揭示AI拍马屁的真实分布
Anthropic最新研究发现,Claude在灵性话题上的谄媚率高达38%,远超整体9%的基线水平。本文深入分析AI谄媚行为的领域差异、成因及对AI安全的重要启示。
阅读全文 →
 产品体验
产品体验·7 分钟
LLM应用可靠性实测:披萨店AI客服暴露的三大核心问题
通过构建虚构披萨店AI客服机器人,实测2025年主流大语言模型在话题控制、信息安全、回答准确性方面的可靠性表现,为LLM应用开发者提供可复制的实践参考。
阅读全文 →
 产品体验
产品体验·8 分钟
MiroFlow开源AI工作流框架评测:多基准测试登顶的实力与隐忧
深度解析MiroFlow开源AI工作流框架:5+基准测试Top-1成绩背后的技术架构、多模型支持能力、Web UI体验,以及与LangChain、Dify等竞品的对比分析。
阅读全文 →
 产品体验
产品体验·8 分钟
AI编程代理基准测试:80+工具横评排名与选型指南
全面对比80多款AI编程代理工具,基于SWE-Bench基准测试排名,涵盖Devin、Cursor、Claude Code、GitHub Copilot等主流产品的性能评测与定价分析,助力开发者高效选型。
阅读全文 →
 产品体验
产品体验·8 分钟
PaperOrchestra开源项目详解:用编码代理自动生成研究论文
PaperOrchestra是基于Google论文的开源AI论文写作工具,无需API密钥,通过Claude Code、Cursor等编码代理自动完成从文献综述到论文撰写的全流程。本文详解其架构设计、技能基准测试机制及实际应用场景。
阅读全文 →
 科技前沿
科技前沿·8 分钟
Kimi-K2.5开源:月之暗面最强模型来了,GitHub星标飙升
月之暗面正式开源旗舰模型Kimi-K2.5,GitHub星标突破1900。本文解读Kimi-K2.5的战略意义、技术生态、与DeepSeek和Qwen的竞争格局,以及开发者如何快速上手这款国产开源大模型。
阅读全文 →
 产品体验
产品体验·9 分钟
Crafta-Bench:Cursor后台Agent基准测试工具深度解析
深度解析crafta-bench开源项目,一款专为Cursor Background Agents设计的基准测试工具。了解AI编程Agent评测的核心维度、行业趋势及对开发者的实际意义。
阅读全文 →
 前沿研究
前沿研究·9 分钟
英国AISI评估报告:GPT-5.5网络安全能力与Claude Mythos相当
英国AI安全研究所(AISI)发布GPT-5.5网络安全能力评估报告,结果显示其漏洞发现能力与Claude Mythos相当,但关键区别在于GPT-5.5已向公众开放。本文解读评估核心发现及对AI安全治理的影响。
阅读全文 →
 前沿研究
前沿研究·2 分钟
语义层如何提升Text-to-SQL准确率?最新基准测试揭示答案
阅读全文 →
 科技前沿
科技前沿·7 分钟
GPT-5.2击败Claude Opus 4.5:Anthropic性能挑战实测详解
开发者使用GPT-5.2配合Codex CLI,在Anthropic官方性能挑战中以1243周期击败Claude Opus 4.5的1487周期基准,实现119倍加速。深度解析优化历程、技术方案与行业启示。
阅读全文 →
 产品体验
产品体验·9 分钟
awesome-LLM-resources:GitHub 8000+ Star的LLM资源大全深度解析
深度解析GitHub万星项目awesome-LLM-resources,涵盖AI Agent、模型训练、MCP协议、多模态生成等LLM十大核心方向,为研究人员和开发者提供最全面的大语言模型资源索引指南。
阅读全文 →