#Benchmark
共 102 篇相关文章
科技前沿
每日AI新鲜事·06月07日早间播报
·1 分钟
每日AI新鲜事·06月07日早间播报
06月07日早间播报 AI领域热点新闻速递,10条精选资讯
阅读全文 →

·6 分钟
创始人被踢出自己公司:融资背后的权力博弈
从Uber创始人被逼退事件,深度解析创业融资中的股权稀释、董事会控制权与投资人选择策略,帮助创业者在融资中保护自身权益,避免失去公司控制权。
阅读全文 →

·7 分钟
AI基准测试:当前最被低估的技术创业机会
AI基准测试正成为巨大的创业机会。传统评测被刷爆、供需严重失衡,谁能构建高质量公共AI基准测试,谁就掌握行业话语权。本文解析为何AI评测基础设施是高回报的差异化路径。
阅读全文 →
科技前沿
前沿论文解读·当科学走到「不可证伪」的边界
·1 分钟
前沿论文解读·当科学走到「不可证伪」的边界
每周五解读本周最值得关注的AI研究论文
阅读全文 →

·5 分钟
ViBench:专为AI应用构建能力设计的评测基准
深入解析ViBench评测基准,了解它如何弥补SWE-bench在应用构建能力评估上的不足,从端到端生成、视觉交互、功能完整性等维度全面衡量AI编程工具的实际表现。
阅读全文 →

·8 分钟
AI时代新构建者思维:开发者角色如何进化
OpenAI提出"开发者已经进化",探讨AI时代新构建者思维的核心内涵:从代码编写者到产品构建者的角色转变,开发门槛降低带来的行业趋势,以及全栈个体崛起等深远影响。
阅读全文 →
 产品体验
产品体验·4 分钟
Claude Haiku 4.5实测:编程能力接近Sonnet 4,成本仅三分之一
实测Claude Haiku 4.5编程能力,对比Sonnet 4.5和Opus 4.1完成天气卡片、物理模拟、3D渲染三项任务,分析其性价比优势与适用场景。
阅读全文 →
 科技前沿
科技前沿·5 分钟
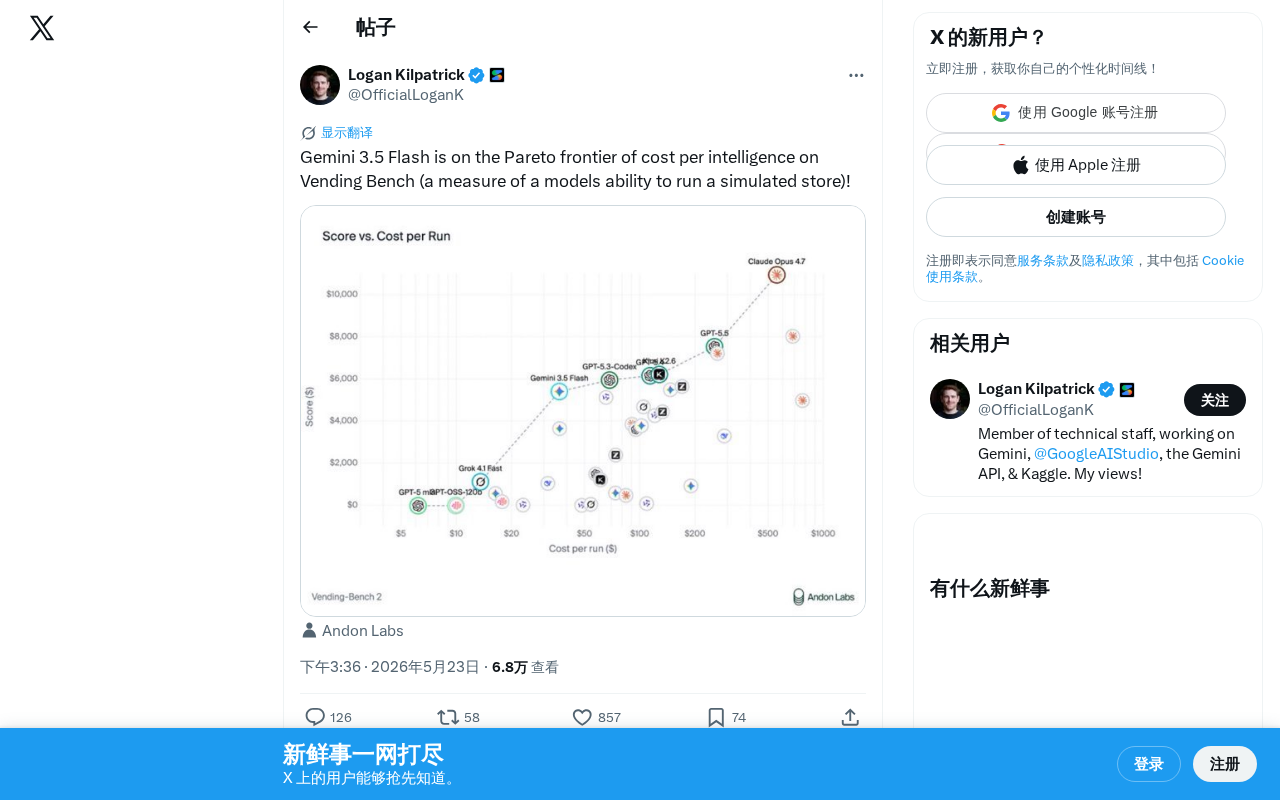
Gemini 3.5 Flash登顶Vending Bench性价比前沿
Google Gemini 3.5 Flash在Vending Bench基准测试中达到成本-智能帕累托最优,展现极强性价比。本文解析Vending Bench评测方法、帕累托前沿含义及对AI应用开发者的实际意义。
阅读全文 →
 行业洞察
行业洞察·5 分钟
Bun告别Zig:AI用6天完成96万行Rust重写全解析
Bun v1.3.14可能是Zig时代最后一版。AI Agent在6天内完成96万行代码从Zig到Rust的迁移,测试通过率达99.8%。深度解析迁移策略、性能数据及对软件开发模式的深远影响。
阅读全文 →
 产品体验
产品体验·8 分钟
WhichLLM:一键检测你的电脑最适合跑哪个本地大模型
WhichLLM 是一款开源工具,能自动检测电脑硬件配置,结合权威评测数据推荐最适合本地运行的大语言模型。支持模拟任意显卡配置、过滤虚假评测、一键下载开聊,帮你告别选模型的纠结。
阅读全文 →
 产品体验
产品体验·5 分钟
实测15款大模型开发B站首页:GPT登顶,国产模型差距明显
用同一套提示词让15款主流大模型一次性开发B站视频平台应用,实测ChatGPT、Claude、Gemini及国产模型的真实编程能力。详细对比前后端表现、指令遵循度与架构设计,附分层使用策略推荐。
阅读全文 →
 产品体验
产品体验·5 分钟
GPT-5.5实测3周:编程能力碾压Opus 4.7?
EVERY团队深度测试GPT-5.5三周,通过SABench高级工程师基准测试对比Claude Opus 4.7。GPT-5.5编程执行力得分62.5远超Opus的33分,但最佳实践是用Opus规划+GPT-5.5执行的组合工作流。
阅读全文 →
 教程攻略
教程攻略·8 分钟
用AI开发三消游戏并让Agent自己玩:全流程实战
前端程序员借助Godot+MCP插件让AI从零开发三消游戏,并设计前后端分离架构让Agent自主游玩。详解环境搭建、接口设计、Agent自我迭代策略,展示AI开发游戏+AI玩游戏的完整闭环。
阅读全文 →
 行业洞察
行业洞察·10 分钟
Google I/O 2026深度解读:从超级App到生态内核之争
深度解析Google I/O 2026发布会战略信号:Gemini 3.5 Flash、Omni视频工具、Spark个人Agent等核心产品拆解,以及谷歌与OpenAI、Anthropic三巨头的AI生态竞争格局。
阅读全文 →
 教程攻略
教程攻略·9 分钟
OpenRouter免费模型使用教程:28款免费AI模型接入与市场格局深度解析
详解OpenRouter平台28款免费AI模型的筛选、API接入配置方法,涵盖GPT-OSS 120B、DeepSeek V4 Flash等热门模型,并通过排行榜数据分析AI模型市场格局、Coding Agent竞争态势及免费与付费模型的效率差距。
阅读全文 →
 产品体验
产品体验·7 分钟
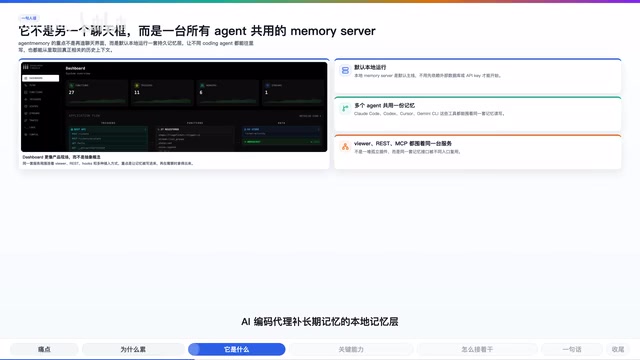
Agent Memory:让AI编码代理拥有跨会话持久记忆
Agent Memory 是一个开源本地记忆层,为 Claude Code、Cursor、Codex 等 AI 编码代理提供跨会话、跨工具的长期记忆能力,彻底告别每次新会话重讲项目背景的痛点。
阅读全文 →
 产品体验
产品体验·8 分钟
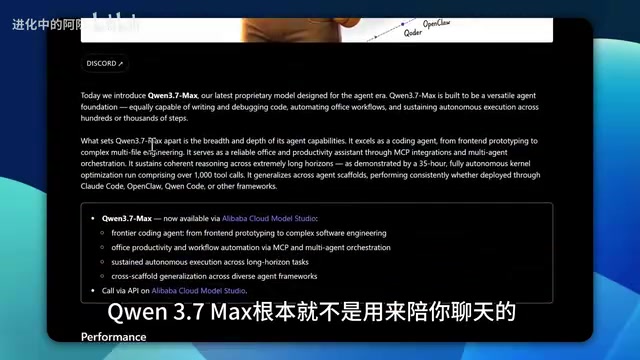
Qwen3.7 Max深度解析:成本仅GPT十分之一,专为智能体而生
阿里千问Qwen3.7 Max定位智能体赛道,编程任务成本仅1.3美元(GPT-5的十分之一),支持35小时连续执行。本文深度解析其性价比优势、前端开发能力及三大短板,帮你判断是否值得接入工作流。
阅读全文 →
 行业洞察
行业洞察·6 分钟
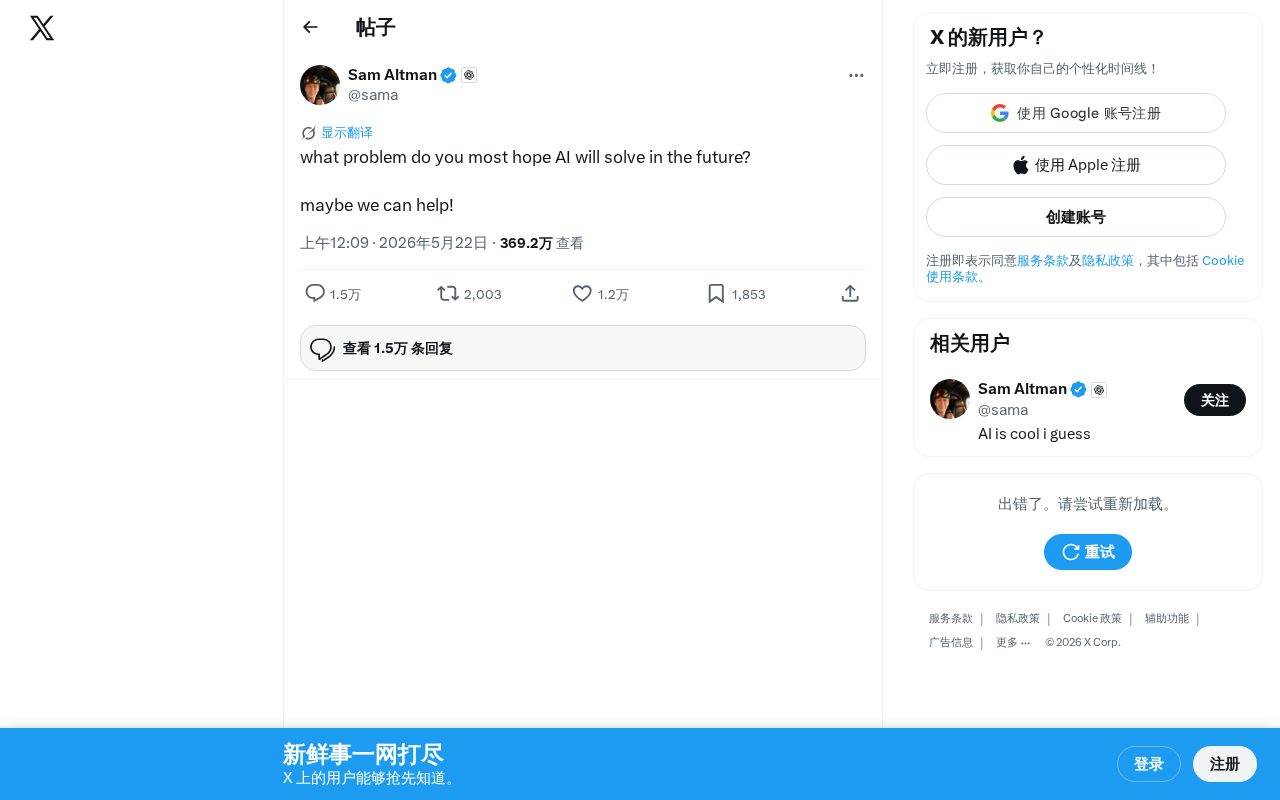
你最希望AI解决什么问题?一场关于AI未来方向的深度思考
一条简单的推文引发广泛讨论:你最希望AI解决什么问题?从医疗健康、教育公平到科学研究,梳理人们对AI最迫切的期待,探讨AI从技术驱动转向需求驱动的范式转变。
阅读全文 →
 产品体验
产品体验·8 分钟
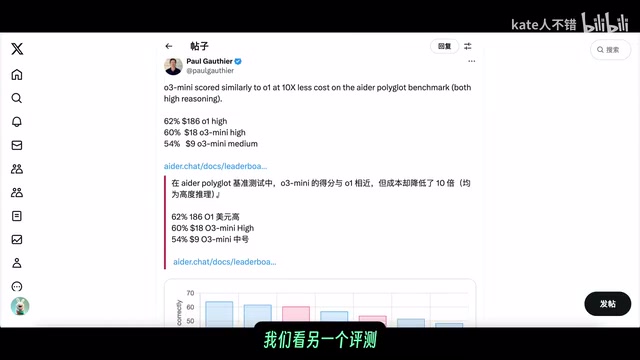
o1、o1 pro与o3-mini-high编程能力深度对比:Deep Research实测分析
通过Deep Research功能系统对比OpenAI o1、o1 pro和o3-mini-high三个模型的编程能力,涵盖代码生成质量、优化能力、错误率与调试表现,附官方基准数据与实际案例分析,帮助开发者选择最适合的AI编程模型。
阅读全文 →
 前沿研究
前沿研究·7 分钟
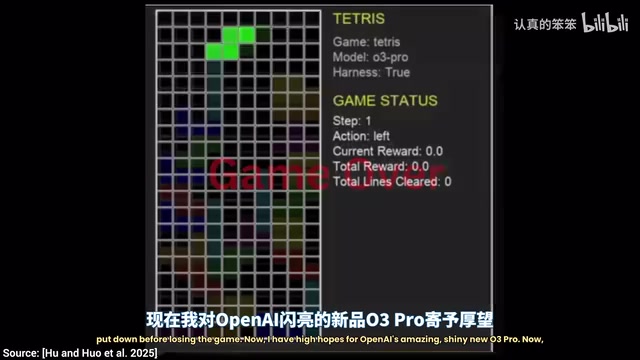
AI玩游戏实力大比拼:O3 Pro展现惊人规划能力
研究者用俄罗斯方块、超级马里奥、推箱子等经典游戏测试各大AI模型,O3 Pro展现出前所未有的规划能力,成为唯一通关全部关卡的模型。游戏测试揭示AI正从模式匹配向真正的战略思维演进。
阅读全文 →