#Benchmark
共 102 篇相关文章
 科技前沿
科技前沿·6 分钟
Google Anti-Gravity 2.0详解:替代Gemini CLI的多智能体开发平台
Google Anti-Gravity 2.0正式取代Gemini CLI,带来桌面应用、CLI终端和SDK三种形态。基于Gemini 3.5 Flash模型,支持多Agent并行协作和Managed Agents一键部署,6月18日前需完成迁移。
阅读全文 →
 产品体验
产品体验·6 分钟
Codex vs Claude Code实测对比:$20档位真实差距有多大
基于一个月双线并行实测,从定价、上手难度、代码质量、上下文窗口、杀手锏功能等维度全面对比OpenAI Codex和Claude Code,帮你搞清楚20美元档位该选谁、什么场景用什么工具最高效。
阅读全文 →
 教程攻略
教程攻略·4 分钟
SourceCheck:用引用替代拷贝,构建可验证的LLM可信输出
SourceCheck 是一款开源工具,通过元数据引用协议替代大段拷贝,结合确定性校验与自我修正循环,解决LLM幻觉问题。支持Fact Check与RAG可追溯性,为构建可信LLM输出提供可落地的技术方案。
阅读全文 →
 观点碰撞
观点碰撞·4 分钟
验证驱动开发:释放AI编程真正潜力的关键
AI编程工具的瓶颈不在模型能力,而在验证体系。本文解析验证驱动开发范式,涵盖八大验证支柱、正向飞轮效应及实操路径,帮助工程团队实现5-7倍效率提升。
阅读全文 →
 行业洞察
行业洞察·6 分钟
AI静默发布现象解析:为什么顶尖技术选择低调面世
探析AI领域兴起的"静默发布"策略:从Meta Llama到DeepSeek,为什么越来越多顶尖AI产品选择低调发布?解读开源社区推动下的谦逊文化如何重塑行业竞争格局。
阅读全文 →
 行业洞察
行业洞察·5 分钟
AI预测中的"方向性准确":为什么比精确预测更有价值
什么是方向性准确(directionally accurate)?本文解析AI领域中方向性判断的核心价值,结合深度学习崛起、大模型涌现能力等经典案例,探讨如何做出方向正确的技术趋势预测与战略决策。
阅读全文 →
 产品体验
产品体验·5 分钟
GLM5.1编程能力实测:从零构建全栈AI画布应用全过程
实测智谱GLM5.1在全栈开发中的真实表现,通过从零构建AI画布应用,验证其在问题理解、代码调试和多智能体协作方面的能力提升,附完整开发流程与迭代经验。
阅读全文 →
 教程攻略
教程攻略·4 分钟
OpenClaw企业部署指南:Sonnet 4.6+VPS打造团队AI智能体
详解OpenClaw企业级部署全流程:用Sonnet 4.6配置AI智能体,VPS低成本部署,Slack集成实现团队协作,活文件理论构建企业知识库,三步配置打造自动化运行的智能体架构。
阅读全文 →
产品体验
Benchmark:AI自动分析金融科技报价,巴西定价透明化利器
·6 分钟
Benchmark:AI自动分析金融科技报价,巴西定价透明化利器
Benchmark是巴西金融科技领域的AI定价分析工具,用户上传PDF报价单即可自动比对660+数据点,用颜色编码直观展示费用是否合理。完全免费无需注册,帮助企业在BaaS和支付服务谈判中掌握主动权。
阅读全文 →
 产品体验
产品体验·3 分钟
Gemini 3.1 Pro编程实测:跑分第一实战第三,与Claude和GPT真实对比
实测对比Gemini 3.1 Pro、Claude Opus 4.6和GPT 5.3 Codex的真实编程能力。通过跨项目迁移和CLI转Web UI两道实战题,揭示Benchmark第一的Gemini在复杂任务中翻车的真实表现。
阅读全文 →
 产品体验
产品体验·4 分钟
Cursor Composer 2.5深度实测:200 Token/秒的氛围编程到底好不好用
实测Cursor Composer 2.5的Bug修复、视频生成等场景表现。200 Token/秒极速响应,成本仅55美分/任务,对比Opus 4.7和GPT 5.5的优劣势分析,以及调试模式的隐藏用法。
阅读全文 →
 产品体验
产品体验·5 分钟
DeepSeek V4 Pro深度评测:对比8款旗舰模型谁更值得用
DeepSeek V4 Pro全方位横评,对比GPT 5.5、Claude Opus 4.7、GLM 5.1等8款旗舰模型,覆盖价格、编程、推理、Agent、角色扮演等维度,附场景化选购建议。
阅读全文 →
 教程攻略
教程攻略·6 分钟
NVIDIA开源AI-Q:让编程Agent具备深度研究能力的技能包
NVIDIA开源AI-Q技能包,为Claude Code、Codex等编程Agent提供四阶段深度研究流水线,支持MCP协议数据安全接入和本地部署,Benchmark准确率达94%。本文详解AI-Q架构、接入方式与企业级落地方案。
阅读全文 →
 行业洞察
行业洞察·3 分钟
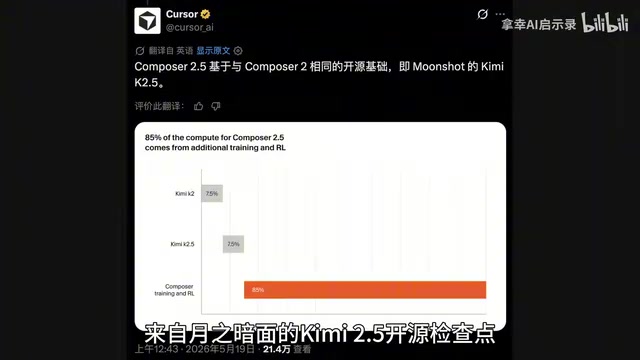
Cursor Composer 2.5深度解析:开源模型1/10成本叫板Claude 4.7
Cursor发布Composer 2.5,基于开源模型Kimi K2.5实现与Claude 4.7 Opus持平的编程能力,成本仅为十分之一。深度解析三大技术突破、AI自主学会逆向工程的安全隐患,以及与SpaceX AI百万H100算力合作的战略布局。
阅读全文 →
 产品体验
产品体验·6 分钟
Gemini 3.5 Flash实测对比Qwen3.6:排行榜高分与真实体验差多远?
深度实测Gemini 3.5 Flash在UI生成、编程、Agent能力等维度的真实表现,与Qwen3.6-27B横向对比,揭示大模型排行榜分数与实际体验之间的落差,帮你理性选择AI模型。
阅读全文 →
 产品体验
产品体验·6 分钟
7个AI修同一个Bug实测:GLM 5.1反超Claude Sonnet详细对比
从OpenClaw 35万Star项目中选取3个真实PR,让GLM、DeepSeek、Kimi等7个AI模型独立修Bug。GLM 5.1以89.3分反超Sonnet 4.6的87.2分,测试覆盖碾压全场,国产开源AI编程能力已追上Claude Sonnet基准线。
阅读全文 →
 教程攻略
教程攻略·5 分钟
MiniMax M2.7免费使用教程:NVIDIA端点+Kilo CLI零成本AI编程
MiniMax M2.7模型已上线NVIDIA免费端点,230亿参数MoE架构支持204.8K上下文窗口。本文详解如何通过Kilo CLI快速接入,打造零成本AI编程智能体工作流,涵盖配置步骤、基准测试和最佳使用场景。
阅读全文 →
 产品体验
产品体验·4 分钟
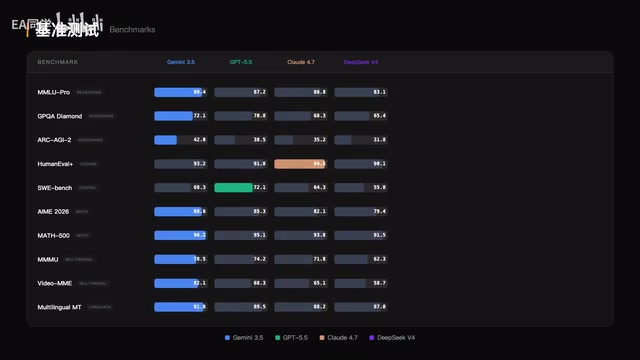
Gemini 3.5 Pro深度评测:多模态断层领先,9.2分旗舰实力全解析
深度评测Google DeepMind旗舰模型Gemini 3.5 Pro,涵盖MMLU Pro 89.4分、Video ModeM 82.1分等基准数据,横向对比GPT 5.5、Claude 4.7,解析DeepThink推理、200万上下文窗口、多模态能力等核心优势与不足。
阅读全文 →
 科技前沿
科技前沿·5 分钟
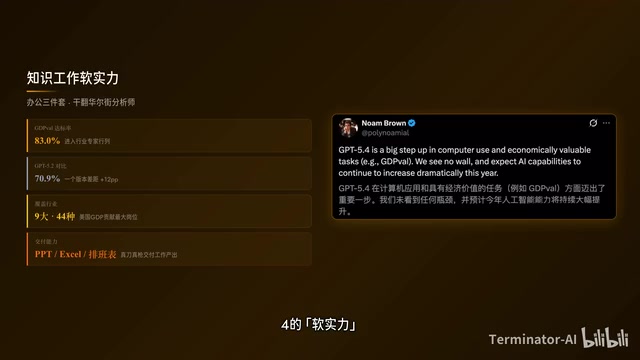
GPT-5.4深度评测:原生计算机使用、推理编程合体,OpenAI重回王座
GPT-5.4全面评测:OSWorld超越Claude Opus 4.6,原生计算机使用能力炸裂,推理编程合体Token效率提升50%,幻觉率暴降33%,搜索能力刷新纪录。OpenAI首个全能通用模型深度解析。
阅读全文 →
 产品体验
产品体验·3 分钟
Claude Opus 4.7深度实测:编码能力飙升,最强模型Mythos仍被封印
Claude Opus 4.7实测评测:SWE Bench编码基准全面领先GPT 5.4和Gemini,视觉处理能力提升3倍,开发者工具大幅更新。Anthropic承认最强模型Mythos因安全风险被封印,揭示AI竞争格局深层变化。
阅读全文 →