#MOE架构
共 94 篇相关文章
 教程攻略
教程攻略·6 分钟
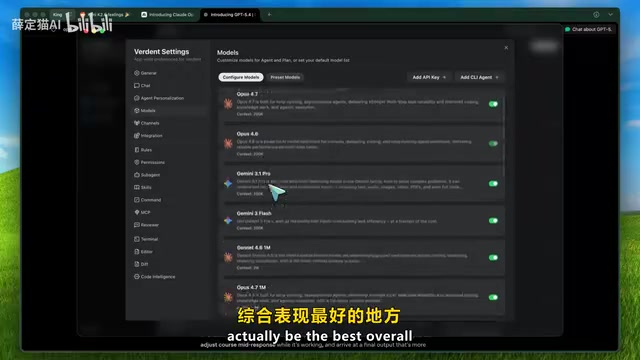
Claude Code接入DeepSeek V4:省99%成本的完整配置教程
详细教程:通过CC Switch工具将Claude Code接入DeepSeek V4,实现1%成本的AI编程方案。包含安装配置步骤、多模型协作实操演示、模型选择框架及OpenRouter免费方案。
阅读全文 →
 产品体验
产品体验·5 分钟
GPT 5.4 vs Opus 4.7 vs Kimi K2.6 Code编程实测对比
实测对比GPT 5.4、Claude Opus 4.7和Kimi K2.6 Code三大AI编程模型,从后端开发、前端UI、性价比和工具生态四个维度深度评测,帮助开发者选出最适合的AI编程助手。
阅读全文 →
 行业洞察
行业洞察·3 分钟
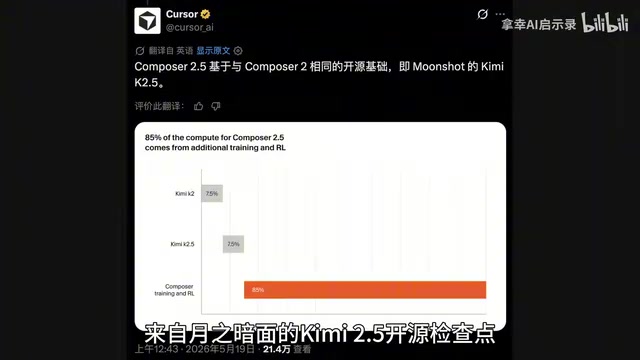
Cursor Composer 2.5深度解析:1/10成本比肩Claude Opus 4.7的编码能力
Cursor自研Composer 2.5模型通过大规模强化学习后训练,以1/10成本实现与Claude Opus 4.7、GPT 5.5比肩的编码能力。本文深度解析其文本反馈强化学习、合成数据生成等核心技术创新及Benchmark实测数据。
阅读全文 →
 行业洞察
行业洞察·3 分钟
Cursor Composer 2.5深度解析:开源模型1/10成本叫板Claude 4.7
Cursor发布Composer 2.5,基于开源模型Kimi K2.5实现与Claude 4.7 Opus持平的编程能力,成本仅为十分之一。深度解析三大技术突破、AI自主学会逆向工程的安全隐患,以及与SpaceX AI百万H100算力合作的战略布局。
阅读全文 →
 产品体验
产品体验·1 分钟
MiniMax M2.5实测:10B参数如何跑出旗舰级编程能力
实测MiniMax M2.5在Claude Code中的编程表现,包括3D游戏开发、AI翻译平台搭建等场景,对比Claude Opus和GPT-5.2,解析10B参数模型如何实现高性价比编程能力。
阅读全文 →
 教程攻略
教程攻略·5 分钟
MiniMax M2.7免费使用教程:NVIDIA端点+Kilo CLI零成本AI编程
MiniMax M2.7模型已上线NVIDIA免费端点,230亿参数MoE架构支持204.8K上下文窗口。本文详解如何通过Kilo CLI快速接入,打造零成本AI编程智能体工作流,涵盖配置步骤、基准测试和最佳使用场景。
阅读全文 →
 科技前沿
科技前沿·3 分钟
Qwen3.5-Omni发布:215项任务SOTA,阿里全模态大模型硬刚Gemini
阿里发布Qwen3.5-Omni全模态大模型,基于1亿小时音视频数据原生多模态预训练,215项任务拿下SOTA,多项指标超越Gemini 3.1 Pro。支持音视频Web Coding、长音频分析、113种语言语音识别等能力。
阅读全文 →
 产品体验
产品体验·4 分钟
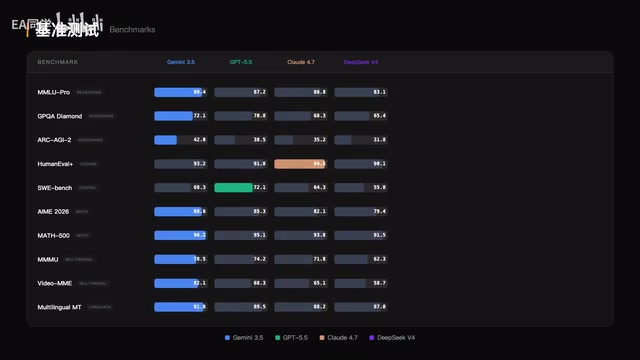
Gemini 3.5 Pro深度评测:多模态断层领先,9.2分旗舰实力全解析
深度评测Google DeepMind旗舰模型Gemini 3.5 Pro,涵盖MMLU Pro 89.4分、Video ModeM 82.1分等基准数据,横向对比GPT 5.5、Claude 4.7,解析DeepThink推理、200万上下文窗口、多模态能力等核心优势与不足。
阅读全文 →
 产品体验
产品体验·6 分钟
DeepSeek V4编码实测:榜单第一Kimi翻车,Claude稳居最强
用同一个全栈小游戏任务实测DeepSeek V4、Claude Opus、GPT和Kimi K2.6四大AI编程模型。榜单排名第一的Kimi K2.6全部失败,Claude Opus一次通过。深度解读DeepSeek V4论文核心技术创新与真实编码选型建议。
阅读全文 →
 产品体验
产品体验·5 分钟
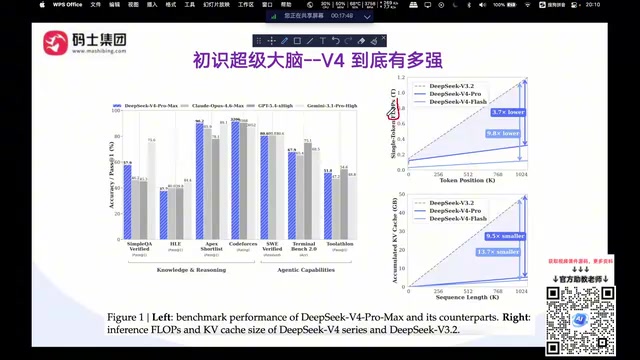
DeepSeek V4深度解析:混合注意力+流形约束+MOM优化器三大创新全解读
深度解析DeepSeek V4三大底层技术创新:混合注意力架构实现百万Token上下文、流形约束超连接稳定极深网络训练、MOM优化器加速收敛。V4 Pro性能对标Claude Opus 4.6,成本仅为其七分之一,附编程实测与部署方案。
阅读全文 →
 产品体验
产品体验·4 分钟
DeepSeek V4深度解析:万亿参数开源模型碾压闭源对手
深度解析DeepSeek V4万亿参数开源模型,从性能Benchmark、百万级上下文技术架构、API成本对比到MIT开源协议,全面拆解V4如何在编程、推理等维度超越GPT和Claude等闭源模型。
阅读全文 →
 产品体验
产品体验·4 分钟
Qwen3.6本地部署实战:35B模型逆向LTE调制解调器击败Claude
Qwen 3.6 35B MoE模型在MacBook本地运行,成功逆向工程LTE调制解调器Web门户,从混淆JS代码中提取登录逻辑和信号数据,代码质量超越Claude Sonnet,Gemma 4同一任务失败。详解三级测试体系与近4小时推理全过程。
阅读全文 →
 产品体验
产品体验·5 分钟
QwenCoder本地部署实测:能否替代付费AI编程助手?
实测QwenCoder 80B本地部署效果,对比Gemini、Claude等付费AI编程工具。详解硬件配置、LM Studio部署方案及实际编程能力测试结果,帮你判断本地模型能否省下AI订阅费。
阅读全文 →
 教程攻略
教程攻略·4 分钟
DeepSeek+Cursor+DevBox:零基础也能完成项目开发部署
详解DeepSeek+Cursor+DevBox零代码开发流程,从项目设计、数据库建模、前后端代码生成到一键部署上线,零基础小白也能独立完成完整项目交付,附适用人群与实操步骤。
阅读全文 →
 深度解读
深度解读·3 分钟
Qwen3.7 Max深度解读:1T参数MOE架构如何打造智能体全能底座
深度解析阿里Qwen3.7 Max模型:1T参数规模、MOE架构、256K上下文,在智能体编程、高难度推理、多语言等四大维度全面领先,兼容LangChain、CrewAI等主流框架,重新定义智能体底座标准。
阅读全文 →
 科技前沿
科技前沿·5 分钟
Qwen3.7 Max深度解读:1T参数MoE架构与智能体全框架兼容
深度解析阿里Qwen3.7 Max大模型:1T参数MoE架构、256K上下文窗口、智能体编程能力全面领先。详解其全框架兼容策略、多语言Token经济布局,以及模型能力与Harness依赖的行业争论。
阅读全文 →
 科技前沿
科技前沿·3 分钟
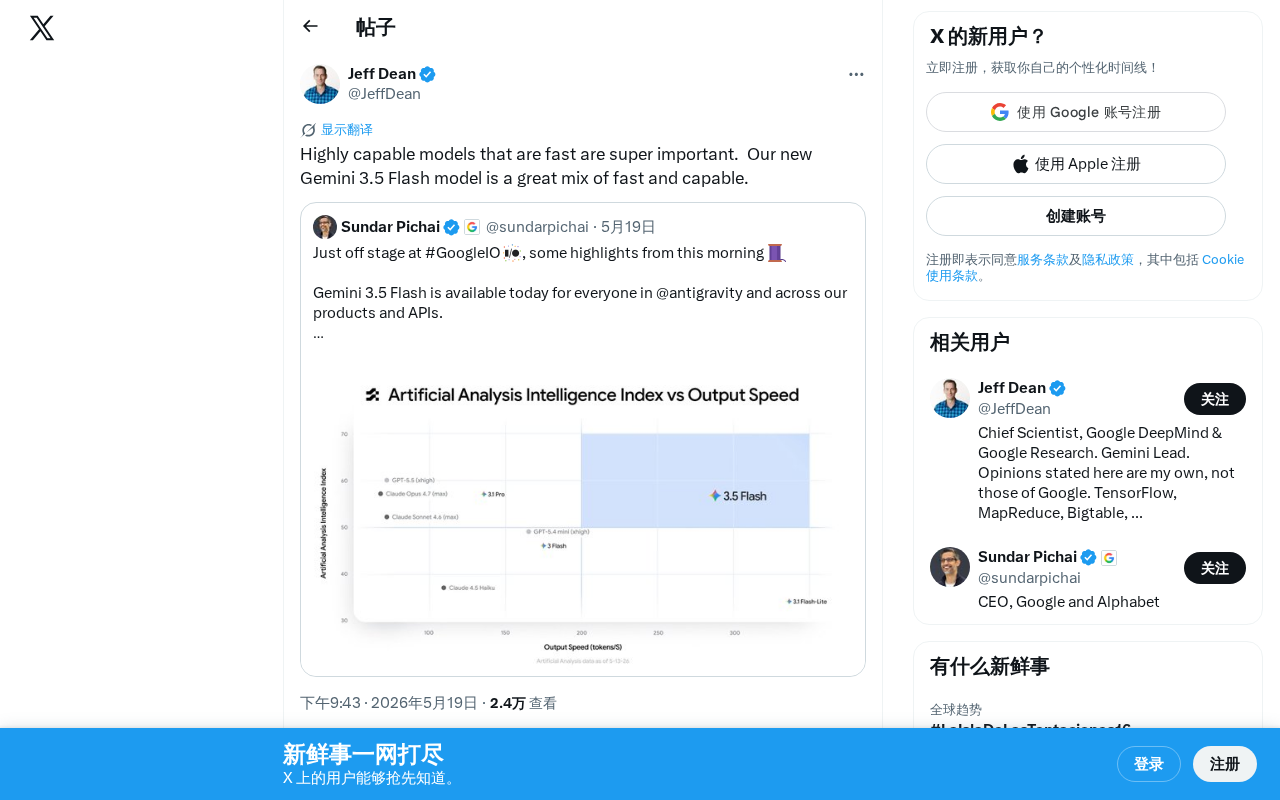
Gemini 3.5 Flash发布:Google如何平衡AI模型速度与能力
Google发布Gemini 3.5 Flash模型,主打速度与能力的最佳平衡。本文解析Flash系列定位演进、与GPT-4o mini等竞品对比,以及对开发者和企业用户的实际应用价值。
阅读全文 →
 科技前沿
科技前沿·3 分钟
Qwen3.6 35B开源实测逼近Claude,xAI语音克隆API正式上线
阿里开源Qwen3.6 35B模型,256专家MoE架构仅需3B激活参数,SWE Bench成绩逼近Claude Opus。xAI发布Voice Cloning API支持28种语言,NVIDIA开源OpenShell安全沙箱,Sam Altman表态模型智力优先。
阅读全文 →
 科技前沿
科技前沿·2 分钟
悟空2.2P开源:35B MOE模型性能超越Qwen3.6-27B,速度快3-5倍
悟空2.2P 35B MOE模型正式开源,采用对抗式杂交蒸馏技术,综合性能超越Qwen3.6-27B。4090显卡Q5量化达158 tokens/s,仅需8.9G显存即可运行,支持256K上下文。详解核心技术、硬件配置与实测数据。
阅读全文 →
 行业洞察
行业洞察·5 分钟
企业大模型选型指南:Llama3.1、Qwen2.5、DeepSeek深度对比
企业如何选择开源大模型?本文从模型能力、硬件需求、业务场景三个维度,深度对比Llama 3.1、Qwen 2.5、DeepSeek、Mistral等主流开源模型,提供选型决策框架与实践建议。
阅读全文 →