#Function Call
共 485 篇相关文章
 教程攻略
教程攻略·6 分钟
Gemini多模态Agent开发实战:理解到生成的全链路架构解析
深入解析Google Gemini多模态Agent开发方案,涵盖100万token上下文的多模态理解、原生图像与语音生成、Live API实时交互,以及Notebook LM克隆应用的完整构建过程与架构设计。
阅读全文 →
 教程攻略
教程攻略·7 分钟
Python+LangChain构建AI科研助手:接入MCP消除学术幻觉
详解用Python、LangChain和Consensus MCP构建AI科研助手的完整流程。从Pydantic结构化输出到CLI原型,再到接入真实学术文献数据库,彻底解决大模型编造论文引用的幻觉问题,提升文献检索与趋势分析效率。
阅读全文 →
 教程攻略
教程攻略·7 分钟
OpenClaw部署教程:VPS搭建AI智能体+Telegram Bot实战
详细图文教程教你在VPS上从零部署OpenClaw AI智能体,配置Node.js环境、连接Telegram Bot实现远程对话,含安全建议与扩展方向。适合想搭建个人AI助手的开发者。
阅读全文 →
 教程攻略
教程攻略·7 分钟
LangChain v0.3 Agent教程:工具定义、构建与执行全流程
详解LangChain v0.3中AI Agent的完整构建流程,涵盖@tool装饰器创建工具、Agent Executor执行机制、并行工具调用、Google搜索集成等核心概念,附代码示例与最佳实践。
阅读全文 →
 教程攻略
教程攻略·9 分钟
LangChain Agent Executor构建原理:从零实现ReAct智能体
深入剖析LangChain Agent Executor的工作原理,详解ReAct模式的推理-行动-观察循环,手把手教你从零构建自定义Agent执行器,掌握Tool Choice策略、并行工具调用等核心技术。
阅读全文 →
 教程攻略
教程攻略·8 分钟
OpenAI Agents SDK消息类型与对话历史管理实战指南
深入解析OpenAI Agents SDK的五种消息类型、对话历史管理机制与常见陷阱。涵盖静态/动态指令配置、Function Call配对原则、事件流思维等核心概念,附完整代码示例。
阅读全文 →
 教程攻略
教程攻略·7 分钟
OpenAI Agents SDK追踪功能使用指南:零配置实现Agent可观测性
详解OpenAI Agents SDK内置追踪系统的配置与使用方法,包括零配置自动追踪、自定义trace上下文、工具调用追踪等,帮助开发者快速实现AI Agent的全链路可观测性与性能优化。
阅读全文 →
 深度解读
深度解读·5 分钟
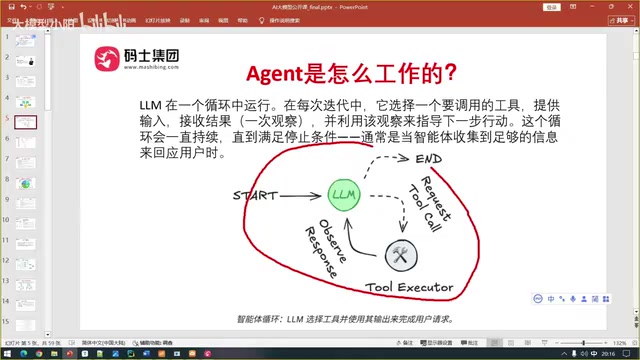
Agent智能体工作原理拆解:四要素与ReAct循环决策机制详解
深度解析AI Agent智能体的四大核心要素(大模型、工具集、提示词、执行器)与ReAct循环决策机制,通过天气查询实例拆解Agent推理-行动的完整工作流程,帮你真正理解智能体的动态决策本质。
阅读全文 →
 教程攻略
教程攻略·5 分钟
Cursor教程:用AI编程5分钟搭建Python学生管理系统
详细演示Cursor AI编程实战,从下载配置到使用Agent模式自动生成Python学生管理系统完整代码,涵盖三种对话模式、Claude模型选择、自动错误修复等核心技巧,零基础也能快速上手。
阅读全文 →
 科技前沿
科技前沿·6 分钟
Datasette Agent:用自然语言查询数据库的开源AI助手
Simon Willison 发布 Datasette Agent,将 LLM 与 Datasette 数据探索工具融合,支持自然语言查询 SQLite 数据库、插件扩展和本地模型运行,打造个人数据分析AI助手。
阅读全文 →
 科技前沿
科技前沿·5 分钟
datasette-agent-sprites:AI Agent沙箱执行插件详解
Simon Willison发布datasette-agent-sprites插件,基于Fly Sprites沙箱环境安全运行AI Agent命令。本文解析其技术原理、应用场景及在AI Agent安全执行领域的意义。
阅读全文 →
 教程攻略
教程攻略·6 分钟
提示工程实战指南:2026年Prompt优化核心技巧与避坑经验
基于2026年实战经验,系统讲解提示工程核心技巧:格式选择、系统消息优先级、角色设定、少样本学习、结构化输出等策略,帮助开发者写出高效Prompt,避免常见陷阱。
阅读全文 →
 观点碰撞
观点碰撞·5 分钟
AI编程终局:为什么可能回归汇编语言?
探讨AI编程发展的终极形态:当AI完全接管编程,高级语言是否会失去存在意义?从核心逻辑、性能优化、跨平台能力等角度分析AI直接编写汇编语言的可能性与挑战。
阅读全文 →
 教程攻略
教程攻略·5 分钟
Spring AI 2.0实战:一小时搭建RAG知识库问答系统
基于Spring AI 2.0和Cursor AI编程工具,从零搭建RAG企业知识库问答系统。涵盖Ollama本地大模型部署、Redis向量数据库、文档解析与向量化、智能检索问答等完整技术方案,附详细开发流程与代码实现。
阅读全文 →
 行业洞察
行业洞察·5 分钟
3500个企业AI案例揭示:AI投资到底赚不赚钱?
基于1000多家企业、3500个真实AI用例的调研数据,深度解读企业AI应用的ROI回报。44%企业获得适度回报,37%获得高回报,AI Agent采用率从11%飙升至42%,编程和风控类用例ROI最高。
阅读全文 →
 深度解读
深度解读·6 分钟
AI编程工具三段进化:从Copilot到Cursor再到Claude Code
深度解析AI编程工具的三段进化历程:GitHub Copilot作为加强版输入法、Cursor成为结对编程伙伴、Claude Code升级为系统级代理。揭秘最强AI编程工具为何回归命令行,以及开发者角色如何随之转变。
阅读全文 →
 深度解读
深度解读·3 分钟
Qwen3.7 Max深度解读:1T参数MOE架构如何打造智能体全能底座
深度解析阿里Qwen3.7 Max模型:1T参数规模、MOE架构、256K上下文,在智能体编程、高难度推理、多语言等四大维度全面领先,兼容LangChain、CrewAI等主流框架,重新定义智能体底座标准。
阅读全文 →
 科技前沿
科技前沿·5 分钟
Qwen3.7 Max深度解读:1T参数MoE架构与智能体全框架兼容
深度解析阿里Qwen3.7 Max大模型:1T参数MoE架构、256K上下文窗口、智能体编程能力全面领先。详解其全框架兼容策略、多语言Token经济布局,以及模型能力与Harness依赖的行业争论。
阅读全文 →
 产品体验
产品体验·5 分钟
Antigravity 2.0更新:反重力三件套全面解析
反重力Antigravity 2.0发布重大更新,产品线扩展为对话式编程工具、经典IDE和CLI命令行三件套。本文详细解析三款工具的定位、功能差异及产品策略,帮助开发者选择最适合的AI编程工具。
阅读全文 →
 产品体验
产品体验·4 分钟
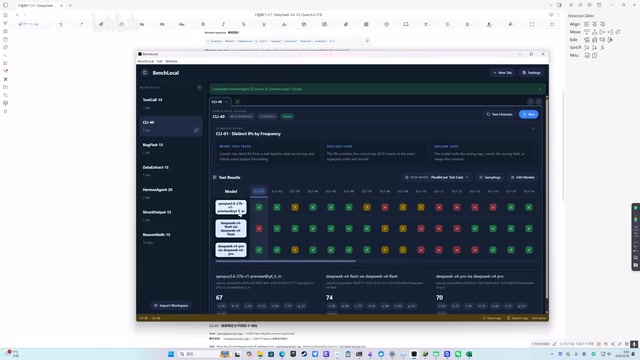
DeepSeek V4 vs Qwen3.6实测:8大类150场景深度对比评测
使用BenchLocal工具对DeepSeek V4 Pro、V4 Flash与Qwen3.6 27B进行8大类85场景实测对比,涵盖工具调用、代码调试、推理数学等维度,V4 Pro总分领先6%但数学推理意外翻车,Qwen3.6 Q6在智能体场景媲美V4 Pro。
阅读全文 →