#LLaMA
共 570 篇相关文章
 教程攻略
教程攻略·6 分钟
Docker Model Runner使用教程:一条命令本地运行AI模型
详解Docker Model Runner的安装配置与实战用法,通过Docker Compose集成本地AI模型,兼容OpenAI API接口,实现零配置本地部署LLM大模型,附完整聊天应用开发示例。
阅读全文 →
 产品体验
产品体验·5 分钟
QwenCoder本地部署实测:能否替代付费AI编程助手?
实测QwenCoder 80B本地部署效果,对比Gemini、Claude等付费AI编程工具。详解硬件配置、LM Studio部署方案及实际编程能力测试结果,帮你判断本地模型能否省下AI订阅费。
阅读全文 →
 产品体验
产品体验·6 分钟
2026版Python全套教程648集深度评测:零基础自学真能7天精通吗?
深度评析B站2026版Python全套教程648集,从课程结构、学习路径到实战项目逐一分析,揭示7天精通的真相,并为零基础Python自学者提供高效学习建议。
阅读全文 →
 教程攻略
教程攻略·5 分钟
Spring AI 2.0实战:一小时搭建RAG知识库问答系统
基于Spring AI 2.0和Cursor AI编程工具,从零搭建RAG企业知识库问答系统。涵盖Ollama本地大模型部署、Redis向量数据库、文档解析与向量化、智能检索问答等完整技术方案,附详细开发流程与代码实现。
阅读全文 →
 教程攻略
教程攻略·7 分钟
DeepSeek本地部署教程:Ollama一键安装运行指南
详细讲解如何通过Ollama在本地部署DeepSeek R1大模型,包括安装步骤、模型版本选择、硬件配置要求及进阶玩法,零基础10分钟搞定私有化AI部署。
阅读全文 →
 教程攻略
教程攻略·5 分钟
LangGraph多智能体架构实战:从单Agent到企业级应用完整指南
深入解析LangGraph多智能体架构的核心原理与实战路径,涵盖Graph图结构、MCP协议接入、单Agent构建到企业级多智能体协作的完整学习指南,帮助AI开发者掌握复杂应用设计能力。
阅读全文 →
 教程攻略
教程攻略·5 分钟
HuggingFace Transformers入门教程:模型下载、Pipeline推理到训练保存
详解HuggingFace Transformers核心用法,涵盖预训练模型下载配置、Pipeline API情感分析实战、Tokenizer分词器原理、模型推理Softmax处理及保存复用完整流程,附Python代码示例。
阅读全文 →
 产品体验
产品体验·4 分钟
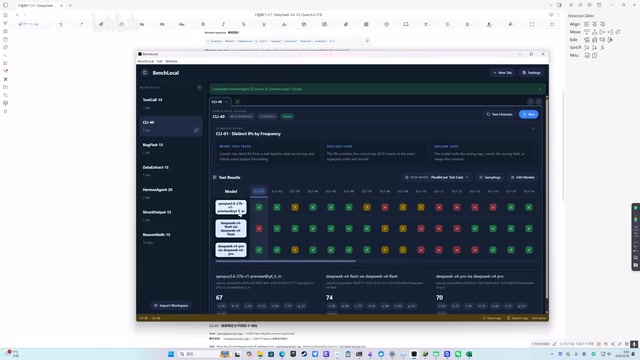
DeepSeek V4 vs Qwen3.6实测:8大类150场景深度对比评测
使用BenchLocal工具对DeepSeek V4 Pro、V4 Flash与Qwen3.6 27B进行8大类85场景实测对比,涵盖工具调用、代码调试、推理数学等维度,V4 Pro总分领先6%但数学推理意外翻车,Qwen3.6 Q6在智能体场景媲美V4 Pro。
阅读全文 →
 产品体验
产品体验·4 分钟
Qwen3.6-27B开源模型评测:27B参数实现旗舰级代码与多模态能力
阿里Qwen3.6-27B开源模型深度解析:270亿参数稠密架构,单卡即可部署,代码生成能力超越前代旗舰。本文详解其技术优势、基准测试成绩、硬件配置方案及实际部署建议,助你低成本获得旗舰级AI编程与多模态理解能力。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Hermes + Qwen3.6 本地部署教程:零成本搭建私有AI Agent
详细教程教你用Hermes Agent搭配Qwen3.6开源大模型,在本地零成本部署私有AI助手。涵盖WSL环境配置、模型下载启动、Telegram机器人对接及开机自启设置,实现无限Token、数据私有的AI Agent体验。
阅读全文 →
 教程攻略
教程攻略·5 分钟
vLLM与SGLang本地部署教程:性能提升3-8倍的实战指南
详解vLLM和SGLang本地部署全流程,对比LM Studio性能差距,通过Docker+AI助手三步完成部署。涵盖SGLang与vLLM选型建议、5090显存优化、Qwen3模型推荐及Cherry Studio接入方法。
阅读全文 →
 前沿研究
前沿研究·4 分钟
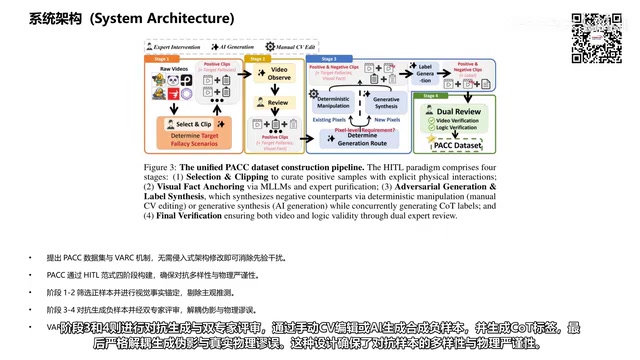
上交大PhyAR:破解Video-LLM物理推理中的语义先验劫持难题
上海交通大学提出PhyAR框架,通过PACC数据集和VARC视觉锚定推理链机制,解决Video-LLM在物理推理中语义先验劫持视觉感知的核心缺陷,无需修改模型架构即可显著提升物理异常检测能力,全面超越GPT-4O等SOTA模型。
阅读全文 →
 科技前沿
科技前沿·2 分钟
悟空2.2P开源:35B MOE模型性能超越Qwen3.6-27B,速度快3-5倍
悟空2.2P 35B MOE模型正式开源,采用对抗式杂交蒸馏技术,综合性能超越Qwen3.6-27B。4090显卡Q5量化达158 tokens/s,仅需8.9G显存即可运行,支持256K上下文。详解核心技术、硬件配置与实测数据。
阅读全文 →
 科技前沿
科技前沿·4 分钟
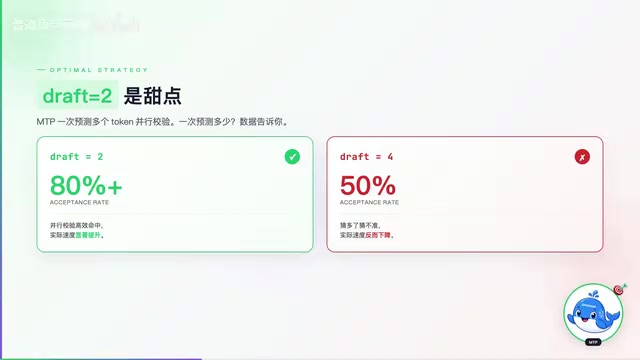
Qwen3.6 MTP加速实测:单GPU推理飙到220 token/s
Qwen3.6实验性MTP-GGUF版本实测,单GPU将35B-A3B模型推理速度提升至220 token/s,比原版快1.4倍且精度零损失。详解MTP原理、最优Draft Tokens策略及RTX 5090实测数据。
阅读全文 →
 行业洞察
行业洞察·5 分钟
企业大模型选型指南:Llama3.1、Qwen2.5、DeepSeek深度对比
企业如何选择开源大模型?本文从模型能力、硬件需求、业务场景三个维度,深度对比Llama 3.1、Qwen 2.5、DeepSeek、Mistral等主流开源模型,提供选型决策框架与实践建议。
阅读全文 →
 产品体验
产品体验·2 分钟
Qwen 3.6 MTP实测:三行参数提速20%的秘密
实测Qwen 3.6多Token预测(MTP)技术,通过ik_llama.cpp仅需三个参数即可将推理速度从34.2提升至41 tokens/s,零质量损失、零额外模型的免费提速方案。附MTP与DFlash对比及完整配置教程。
阅读全文 →
 观点碰撞
观点碰撞·4 分钟
AI权力之争:超级智能该集中垄断还是去中心化普惠?
AI超级智能的控制权正成为时代核心议题。本文深度分析AI权力集中化的现实风险、去中心化开源运动的机遇与挑战,探讨如何在开放与安全之间找到平衡,为AI治理提供第三条路径思考。
阅读全文 →
 科技前沿
科技前沿·5 分钟
OpenAI正式登陆AWS:模型、Codex与托管代理开放预览
OpenAI宣布其前沿模型、Codex编程工具及Bedrock托管代理正式面向AWS客户开放限量预览。本文解读三大核心产品、企业部署价值及云计算AI竞争格局的微妙变化。
阅读全文 →

