#NVIDIA
107 related articles
 Tutorials
Tutorials·2 min
Tutorial: Deploying a PD-Disaggregated SGLang Multi-Node Inference Cluster on AMD GPUs
Learn how to deploy a PD-disaggregated SGLang inference cluster on AMD GPUs using a single config file, boosting LLM throughput and latency performance.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
SGLang v0.5.12.post1 Released: DeepSeek V4 Stability Fixes and Blackwell Adaptation
SGLang v0.5.12.post1 stability patch details: 12 critical fixes covering DeepSeek V4 garbled text and crashes, NIXL PD disaggregated inference logic, Blackwell B300 adaptation, and cold start optimization.
Read more →
 Industry Insights
Industry Insights·2 min
AMD MI355X Beats B200: Full-Stack Optimization Breakdown for 5% Lower TCO on DeepSeek-R1 Inference
AMD Instinct MI355X achieves 5% lower TCO than NVIDIA B200 on DeepSeek-R1 disaggregated inference via SGLang+MoRI full-stack optimization with 1.25x per-GPU throughput.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
SGLang Hosts Agent Loops Office Hour, Focusing on Agentic Loop Architecture Optimization
SGLang team hosts an Agent Loops Office Hour exploring inference optimization for agentic loops, covering KV Cache reuse, low-latency multi-turn dialogue, and tool calling techniques.
Read more →
Tutorials
AI Agent Practical Development: A Comp…
·3 min
AI Agent Practical Development: A Complete Guide from Concept to Building Production-Grade Intelligent Agents
A deep dive into AI Agent core principles and practical development paths, covering perception-decision-execution capabilities, MCP protocol tool integration, and analysis of Manus and AutoGLM.
Read more →
Tutorials
Codex + Claude Code + Cursor: A Practi…
·3 min
Codex + Claude Code + Cursor: A Practical Breakdown of a Three-Tool AI Coding Workflow
A deep breakdown of Codex, Claude Code, and Cursor — their positioning, collaboration methods, and a complete practical workflow with pricing and role-based pairing recommendations.
Read more →
 Tutorials
Tutorials·2 min
Learning AI Large Language Models from Scratch: A Guide to Learning Paths, Hardware, and Programming Languages
A beginner's guide to learning AI large language models — covering learning paths, hardware requirements, Python essentials, and cloud services for learners at every level.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
Anthropic Closes $65 Billion Series H, Valuation Approaches $1 Trillion
Anthropic closes a $65B Series H round at a $965B valuation, co-led by Sequoia and others. Funds target frontier AI research and Claude compute scaling, setting a new tech private funding record.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
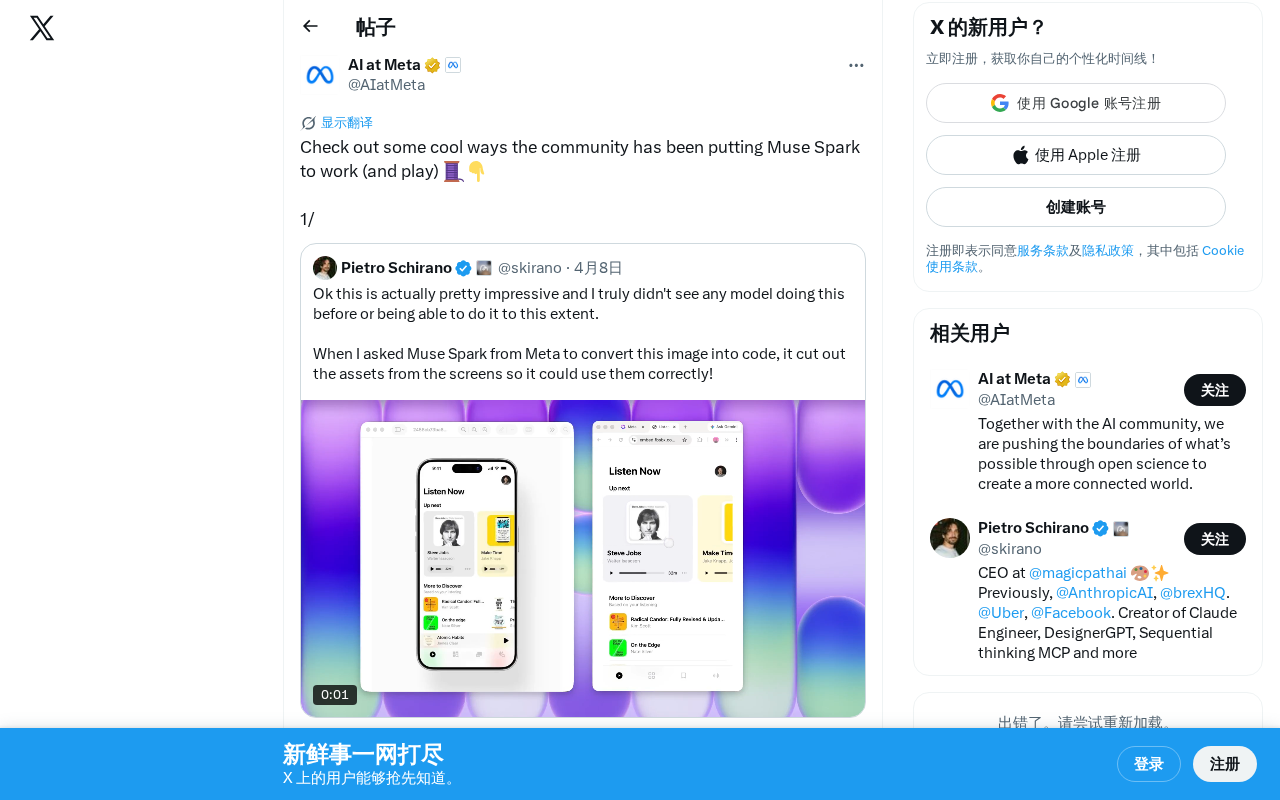
What is NVIDIA Muse Spark? A Complete Guide to Community Creative Uses and Application Scenarios
Explore NVIDIA Muse Spark's features as an AI creative tool, discover community users' creative applications in work and entertainment, and analyze AI creative tool ecosystem trends.
Read more →
 Industry Insights
Industry Insights·2 min
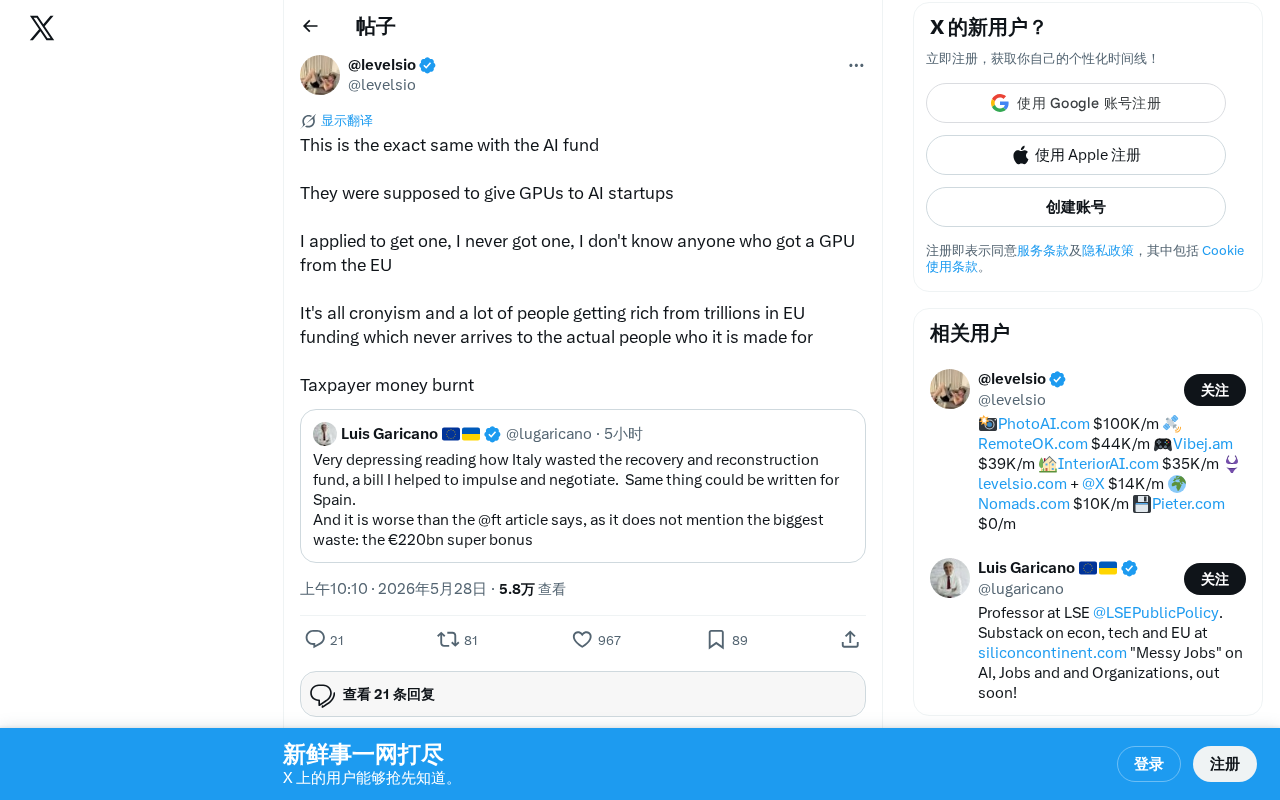
The EU AI Fund Controversy: Why GPU Subsidies Fail to Reach Real Entrepreneurs
The EU AI Fund aims to provide GPU compute for startups, but entrepreneurs question resource allocation citing cronyism. Analysis of EU AI subsidy challenges vs. US market-driven models.
Read more →
 Industry Insights
Industry Insights·2 min
Meta Partners with AWS: Bringing in Tens of Millions of Graviton Cores to Expand AI Infrastructure
Meta partners with AWS to add tens of millions of Graviton cores for AI inference, diversifying its infrastructure to support Meta AI and Agentic experiences for billions of users.
Read more →
Product Reviews
Context Mode: How One MCP Plugin Cured…
·3 min
Context Mode: How One MCP Plugin Cured AI Coding Assistants' Amnesia
Context Mode solves AI coding assistants' context amnesia via sandbox isolation, session continuity tracking, and code-thinking philosophy—compressing context consumption by 99% and earning 9,700 Stars in two months.
Read more →
 Tech Frontiers
Tech Frontiers·3 min
Google Introduces AI Assistant in Job Interviews, OpenAI Launches Cybersecurity-Specific Model GPT-5.5 Cyber
Google introduces Gemini AI assistant in hiring to assess AI proficiency, OpenAI launches GPT-5.5 Cyber for critical infrastructure defense, Anthropic nears trillion-dollar valuation, Mozilla fixes 271 Firefox bugs with AI in two months.
Read more →
 Product Reviews
Product Reviews·2 min
GPT Image 1.5 Deep Dive: Multi-Turn Editing Stability and a Fundamental Shift in Image Generation
Deep dive into GPT Image 1.5's core upgrades: multi-turn editing stability, 4x speed boost, creative editing capabilities, and API access for commercial applications.
Read more →
 Industry Insights
Industry Insights·2 min
NVIDIA Dynamo Snapshot: A Snapshot Recovery Solution for GPU Inference Cold Start Problems
Deep dive into how NVIDIA Dynamo Snapshot reduces LLM inference cold start time from minutes to seconds via GPU state snapshot and recovery, covering Kubernetes integration and elastic inference.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
AI Weekly: Kimi K2.6 Tops Open-Source Rankings, Qwen 3.6 and Google TTS Launch Together
Weekly AI roundup: Kimi K2.6 tops open-source rankings, Anthropic launches Opus 4.7 and Claude Design, Alibaba rolls out Qwen 3.6 series, Google releases emotion-controllable TTS model.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
DeepSeek OCR2, Kimi K2.5, and Microsoft Maia 200 All Launched on the Same Day
DeepSeek releases OCR2 replacing CLIP with an LLM as visual encoder; Moonshot AI launches Kimi K2.5 with 100+ sub-agent cluster mode; Microsoft deploys 3nm Maia 200 chip; Alibaba releases Qwen3 Max Thinking.
Read more →
Product Reviews
Silicon Valley Engineer Quits Big Tech…
·2 min
Silicon Valley Engineer Quits Big Tech to Build an AI Companion Robot: Bringing Machines to Life with a Theater Director's Mindset
Ex-NVIDIA GTC award winner Sparky: an AI researcher quit big tech and used 10+ years of theater experience to design an AI personality system with dynamic interests, long-term memory, and proactive social skills.
Read more →
Tutorials
Decoding LLM Naming Conventions: Param…
·3 min
Decoding LLM Naming Conventions: Parameter Counts, Quantization Formats & VRAM Requirements Quick Reference
Decode LLM naming conventions, understand 32B parameters & AWQ/GGUF quantization formats, with 4-bit VRAM estimation formulas, MOE model pitfalls, and model selection by GPU tier.
Read more →
Product Reviews
AI Coding Appliance vs Cloud LLMs: Can…
·2 min
AI Coding Appliance vs Cloud LLMs: Can ¥480K in Annual Fees Buy 4 Local Deployment Solutions?
A deep cost comparison between AI coding appliances and cloud LLM APIs. A 20-person team spending ¥480K/year on tokens can deploy 4 local OnePanel units at ¥99K each, breaking even in 2.5 months.
Read more →