#本地部署
共 334 篇相关文章
 科技前沿
科技前沿·5 分钟
Open Design实测:免费开源的Claude Design替代方案效果如何
实测对比Open Design与Claude Design在外卖APP、背单词APP、Web仪表盘、PPT生成等场景的设计效果。Open Design完全免费开源,支持16种AI Coding CLI,本文详细评估其优劣势与适用场景。
阅读全文 →
 教程攻略
教程攻略·5 分钟
OpenClaw Agent架构实战:Skills系统部署与LangChain复现指南
深入解析OpenClaw工业级Agent架构的三层设计、Skills可插拔系统与长短期记忆管理机制,手把手演示如何用LangChain复现Skills体系,并以企业HR助理为例展示从部署到商业化落地的完整路径。
阅读全文 →
 教程攻略
教程攻略·6 分钟
免费使用Claude Code:CC Switch+Ollama本地模型驱动AI编程Agent教程
详细教程教你通过CC Switch将本地Ollama模型伪装成Claude API,零成本驱动Claude Code桌面版进行AI编程。涵盖安装配置、模型选择、实测效果,支持千问、Gemma等开源模型。
阅读全文 →
 教程攻略
教程攻略·6 分钟
硅基流动免费Token领取教程:接入Claude Code调用国产大模型
硅基流动注册即送16元代金券,支持DeepSeek、Qwen、Kimi等国产大模型API调用。本文详解从注册领券到通过CitySwitch接入Claude Code的完整配置流程,附模型选择建议。
阅读全文 →
 观点碰撞
观点碰撞·4 分钟
闲鱼副业赚钱攻略:为什么2025年普通人应该选闲鱼而非AI项目
深度解析闲鱼副业赚钱的底层逻辑:零成本启动、平台流量红利期、新版闲鱼功能实测。对比AI项目高门槛高风险,闲鱼才是普通人低成本创业的最佳选择。附实操案例与平台窗口期分析。
阅读全文 →
 教程攻略
教程攻略·2 分钟
多Agent协同医疗问诊系统:RAG+本地部署实战指南
详解多Agent协同医疗问诊系统的开发全流程,涵盖RAG知识库检索、多智能体协同架构设计、本地大模型部署与医疗知识库构建,附完整落地步骤与技术要点分析。
阅读全文 →
 科技前沿
科技前沿·5 分钟
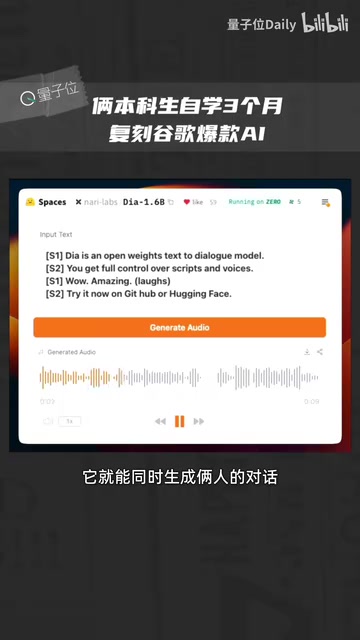
Dia开源项目一天5000星:两本科生3个月复刻NotebookLM播客功能
开源AI语音生成项目Dia上线一天GitHub星标破5000,由两名本科生自学3个月打造。1.6B参数实现近乎实时的双人对话生成,效果媲美谷歌NotebookLM,支持笑声、咳嗽等非语言细节模拟。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Docker Model Runner使用教程:一条命令本地运行AI模型
详解Docker Model Runner的安装配置与实战用法,通过Docker Compose集成本地AI模型,兼容OpenAI API接口,实现零配置本地部署LLM大模型,附完整聊天应用开发示例。
阅读全文 →
 产品体验
产品体验·5 分钟
QwenCoder本地部署实测:能否替代付费AI编程助手?
实测QwenCoder 80B本地部署效果,对比Gemini、Claude等付费AI编程工具。详解硬件配置、LM Studio部署方案及实际编程能力测试结果,帮你判断本地模型能否省下AI订阅费。
阅读全文 →
 教程攻略
教程攻略·5 分钟
Spring AI 2.0实战:一小时搭建RAG知识库问答系统
基于Spring AI 2.0和Cursor AI编程工具,从零搭建RAG企业知识库问答系统。涵盖Ollama本地大模型部署、Redis向量数据库、文档解析与向量化、智能检索问答等完整技术方案,附详细开发流程与代码实现。
阅读全文 →
 教程攻略
教程攻略·7 分钟
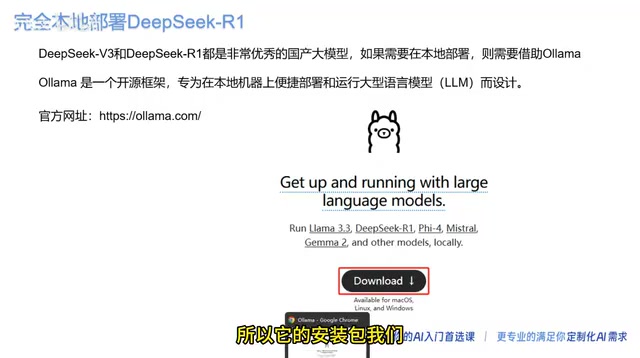
DeepSeek本地部署教程:Ollama一键安装运行指南
详细讲解如何通过Ollama在本地部署DeepSeek R1大模型,包括安装步骤、模型版本选择、硬件配置要求及进阶玩法,零基础10分钟搞定私有化AI部署。
阅读全文 →
 教程攻略
教程攻略·6 分钟
本地部署大模型怎么判断显存爆了?一文看懂显存监控方法
本地部署大模型时如何判断显存是否爆满?本文详解专用显存与共享GPU内存的区别,教你通过任务管理器快速判断显存溢出,并提供模型量化、上下文长度控制等避免爆显存的实用建议。
阅读全文 →
 产品体验
产品体验·4 分钟
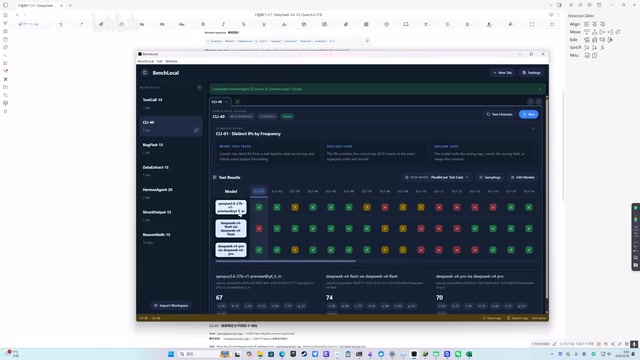
DeepSeek V4 vs Qwen3.6实测:8大类150场景深度对比评测
使用BenchLocal工具对DeepSeek V4 Pro、V4 Flash与Qwen3.6 27B进行8大类85场景实测对比,涵盖工具调用、代码调试、推理数学等维度,V4 Pro总分领先6%但数学推理意外翻车,Qwen3.6 Q6在智能体场景媲美V4 Pro。
阅读全文 →
 产品体验
产品体验·4 分钟
Qwen3.6-27B开源模型评测:27B参数实现旗舰级代码与多模态能力
阿里Qwen3.6-27B开源模型深度解析:270亿参数稠密架构,单卡即可部署,代码生成能力超越前代旗舰。本文详解其技术优势、基准测试成绩、硬件配置方案及实际部署建议,助你低成本获得旗舰级AI编程与多模态理解能力。
阅读全文 →
 产品体验
产品体验·4 分钟
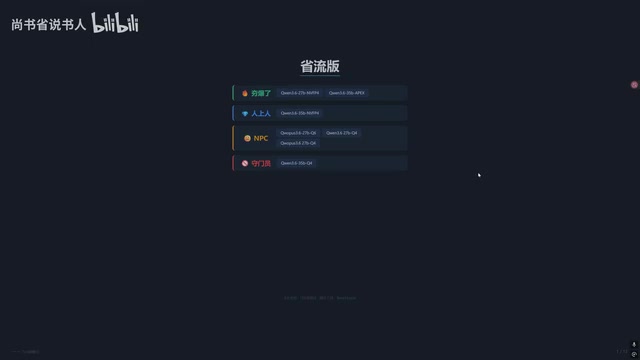
Qwen3.6量化版本地部署实测:NVFP4、APEX、Q4、Q6哪个最值得选
实测Qwen3.6系列7-8个量化模型在工具调用、命令行操作、Bug修复、数学推理等8大维度的表现,对比NVFP4、APEX、Q4、Q6量化方案,附总分排名与选购建议,帮你找到最适合本地部署的量化版本。
阅读全文 →
 科技前沿
科技前沿·3 分钟
Qwen3.6 35B开源实测逼近Claude,xAI语音克隆API正式上线
阿里开源Qwen3.6 35B模型,256专家MoE架构仅需3B激活参数,SWE Bench成绩逼近Claude Opus。xAI发布Voice Cloning API支持28种语言,NVIDIA开源OpenShell安全沙箱,Sam Altman表态模型智力优先。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Hermes + Qwen3.6 本地部署教程:零成本搭建私有AI Agent
详细教程教你用Hermes Agent搭配Qwen3.6开源大模型,在本地零成本部署私有AI助手。涵盖WSL环境配置、模型下载启动、Telegram机器人对接及开机自启设置,实现无限Token、数据私有的AI Agent体验。
阅读全文 →
 教程攻略
教程攻略·5 分钟
vLLM与SGLang本地部署教程:性能提升3-8倍的实战指南
详解vLLM和SGLang本地部署全流程,对比LM Studio性能差距,通过Docker+AI助手三步完成部署。涵盖SGLang与vLLM选型建议、5090显存优化、Qwen3模型推荐及Cherry Studio接入方法。
阅读全文 →
 科技前沿
科技前沿·2 分钟
悟空2.2P开源:35B MOE模型性能超越Qwen3.6-27B,速度快3-5倍
悟空2.2P 35B MOE模型正式开源,采用对抗式杂交蒸馏技术,综合性能超越Qwen3.6-27B。4090显卡Q5量化达158 tokens/s,仅需8.9G显存即可运行,支持256K上下文。详解核心技术、硬件配置与实测数据。
阅读全文 →
 科技前沿
科技前沿·4 分钟
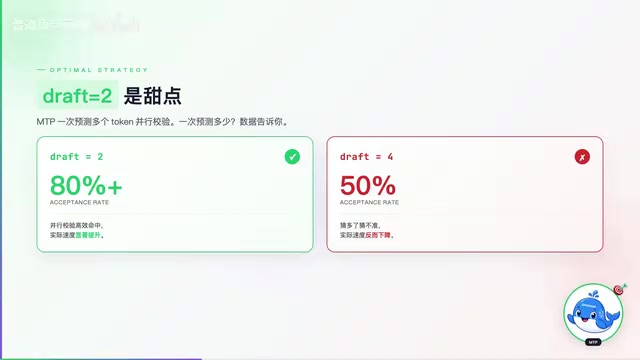
Qwen3.6 MTP加速实测:单GPU推理飙到220 token/s
Qwen3.6实验性MTP-GGUF版本实测,单GPU将35B-A3B模型推理速度提升至220 token/s,比原版快1.4倍且精度零损失。详解MTP原理、最优Draft Tokens策略及RTX 5090实测数据。
阅读全文 →