#Claude Opus
81 related articles
 Product Reviews
Product Reviews·2 min
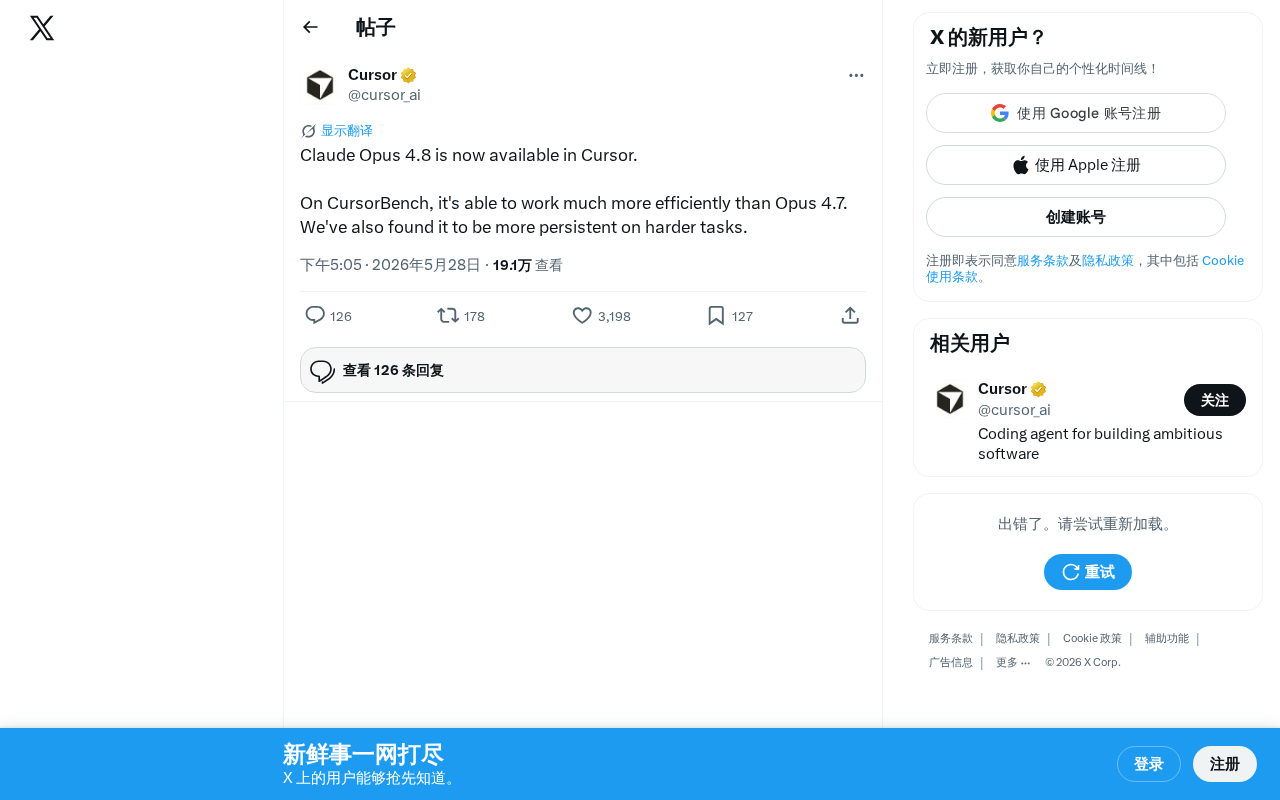
Claude Opus 4.8 Launches on Cursor: Dual Improvements in Efficiency and Persistence
Cursor announces Claude Opus 4.8 is live. CursorBench shows significant gains in coding efficiency and task persistence. Analysis of key improvements and market impact.
Read more →
Product Reviews
Claude Opus 4.8 Deep Dive: A Comprehen…
·2 min
Claude Opus 4.8 Deep Dive: A Comprehensive Review of Judgment, Honesty, and Cost-Effectiveness
Deep dive into Claude Opus 4.8's core upgrades: improved judgment, optimized honest feedback, and Fast Mode costs cut to one-third. Compared with DeepSeek and GPT-5.5 for AI coding and long-context reasoning.
Read more →
Tech Frontiers
June AI Showdown: Mythos, Sonnet 4.8, …
·3 min
June AI Showdown: Mythos, Sonnet 4.8, and GPT-5.6 All Revealed
June 2025 becomes AI's densest release month: Anthropic Mythos nears launch, Claude Sonnet/Opus 4.8 skip-level upgrades, GPT-5.6 rapid iteration, DeepSeek V4 Pro permanent 75% price cut.
Read more →
Tech Frontiers
Claude Opus 4.8 Deep Dive: Honesty Mat…
·2 min
Claude Opus 4.8 Deep Dive: Honesty Matters More Than Benchmarks
Claude Opus 4.8 core upgrade: code bug oversight rate reduced 4x, model becomes more honest. Covers Dynamic Workflows parallel orchestration, Claude Code quota reset, effort control, and upcoming Miscells model.
Read more →
Tutorials
Complete Tutorial: Using GPT to Automa…
·2 min
Complete Tutorial: Using GPT to Automatically Configure Claude Opus 4
Learn how to use GPT's high-intensity thinking mode to automatically configure Claude Opus 4.6/4.7 Max thinking mode in OpenCode, including proxy channel setup, API Key creation, and environment configuration.
Read more →
Product Reviews
How to Use Claude in China: Stable Acc…
·2 min
How to Use Claude in China: Stable Access Solutions & Full Risk Analysis
Users in China face bans, registration hurdles, and payment limits when using Claude. This guide covers third-party mirror sites, model comparisons, and risks.
Read more →
Product Reviews
Amazon Kiro In-Depth Review: How Spec …
·3 min
Amazon Kiro In-Depth Review: How Spec Mode Redefines AI Programming
In-depth review of Amazon's AI programming tool Kiro, detailing Spec Mode's three-phase structured workflow (Requirements → Design → Implementation), comparing it with Cursor, plus a full hands-on build of an expense tracking system.
Read more →
Product Reviews
How to Choose an AI Coding Tool? Stop …
·2 min
How to Choose an AI Coding Tool? Stop Chasing the Latest — Stable and Sufficient Is the Way to Go
How should developers rationally choose AI coding tools amid constant model updates? This article analyzes the pitfalls of chasing the latest, compares tools like Cursor and Kiro, and offers a cost-effective, stable AI-assisted coding strategy.
Read more →
Deep Dives
Claude Opus vs. Sonnet vs. Haiku: How …
·2 min
Claude Opus vs. Sonnet vs. Haiku: How to Choose the Right Model
Compare Anthropic's Claude Opus, Sonnet, and Haiku models across intelligence, speed, and cost. Practical selection guide with multi-model routing strategies.
Read more →
 Product Reviews
Product Reviews·3 min
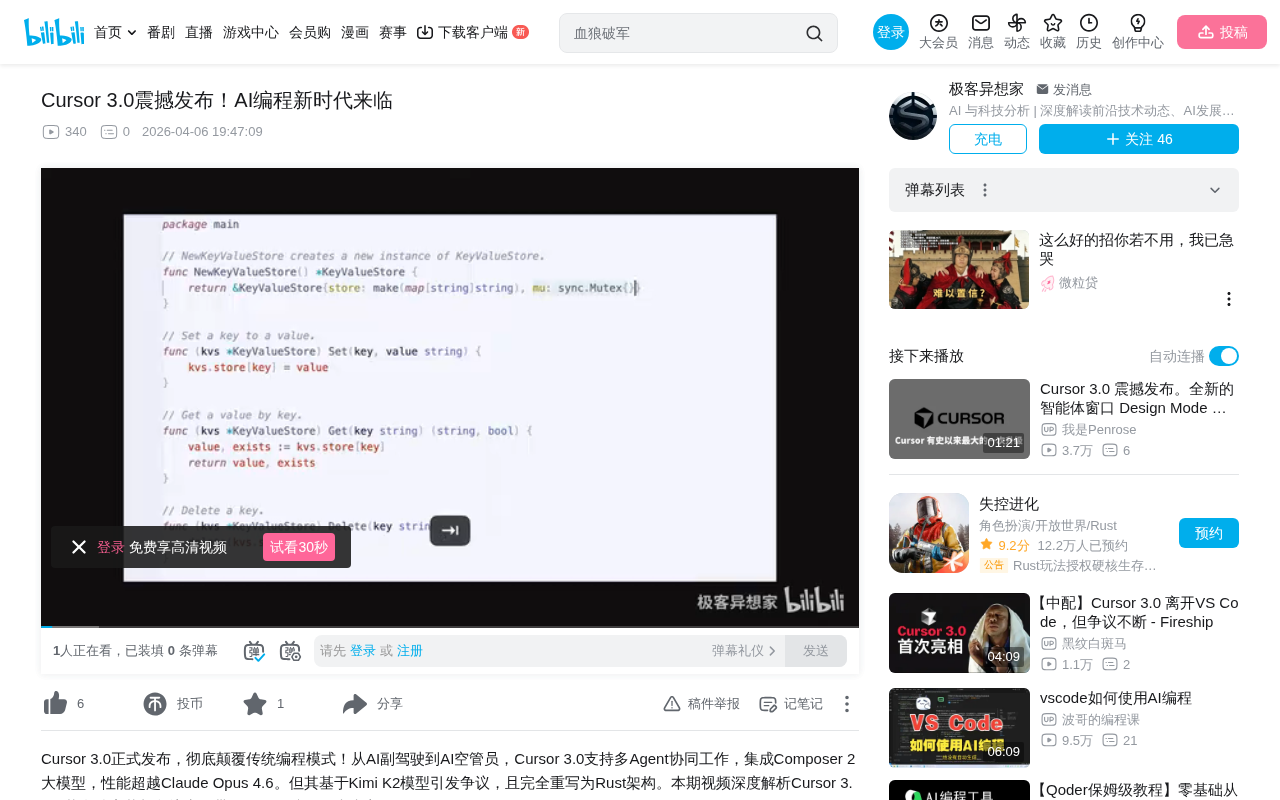
Cursor 3.0 Deep Dive: Rust Rewrite, In-House Model & Agent Orchestration Platform Fully Explained
Deep analysis of Cursor 3.0's three core upgrades: Rust rewrite leaving VS Code behind, in-house Composer 2 model with 86% cost reduction, and Agent Windows for multi-agent parallel development.
Read more →
 Product Reviews
Product Reviews·3 min
Cursor 3.0 Deep Dive: From Code Editor to AI Agent Command Center
Deep dive into Cursor 3.0's major upgrades: proprietary Composer 2 coding model, multi-agent parallel workflows, built-in browser and design mode. Exploring the shift from VS Code fork to Rust rewrite and the AI agent programming paradigm.
Read more →
 Product Reviews
Product Reviews·2 min
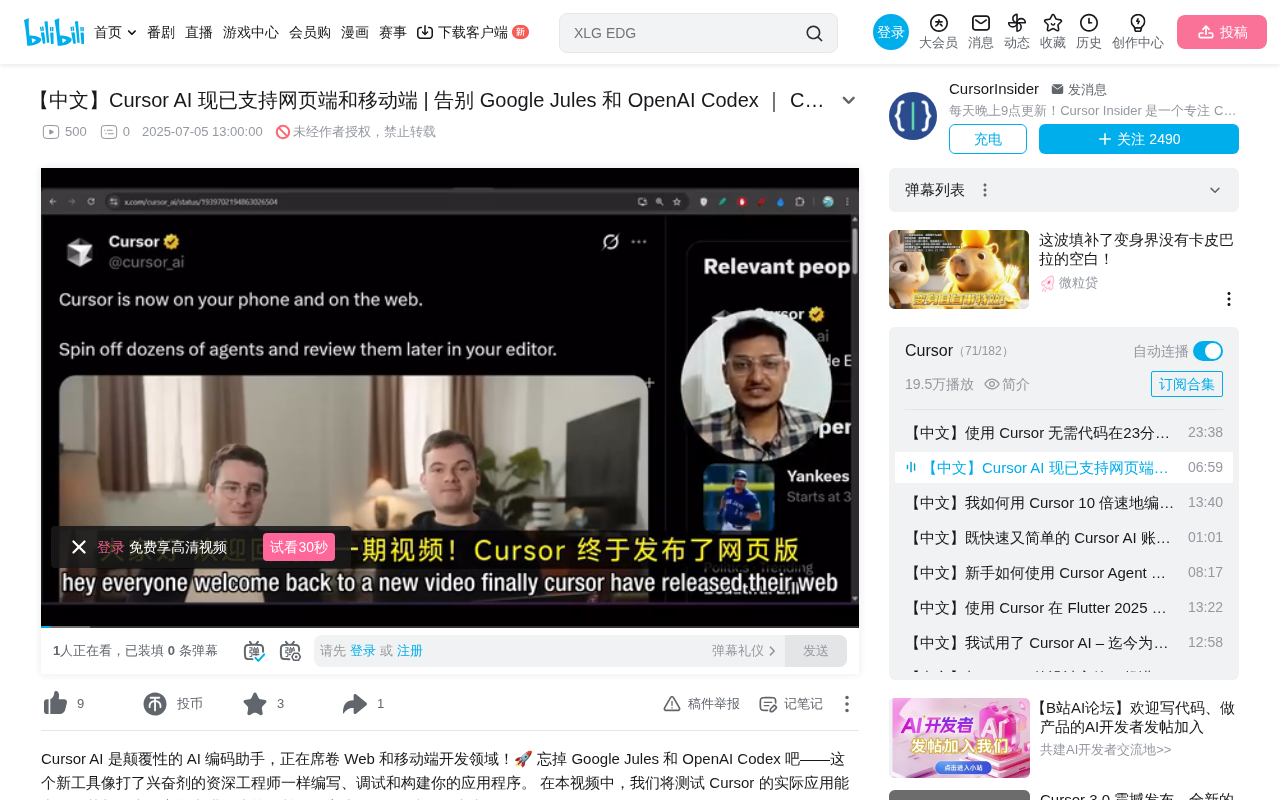
Cursor Web and Mobile Launch: Hands-On with Cloud AI Coding Agents
Cursor launches web and mobile versions supporting multi-agent parallel execution and mobile code review. A detailed look at core features, comparison with Google Jules and OpenAI Codex, and the PWA mobile experience.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
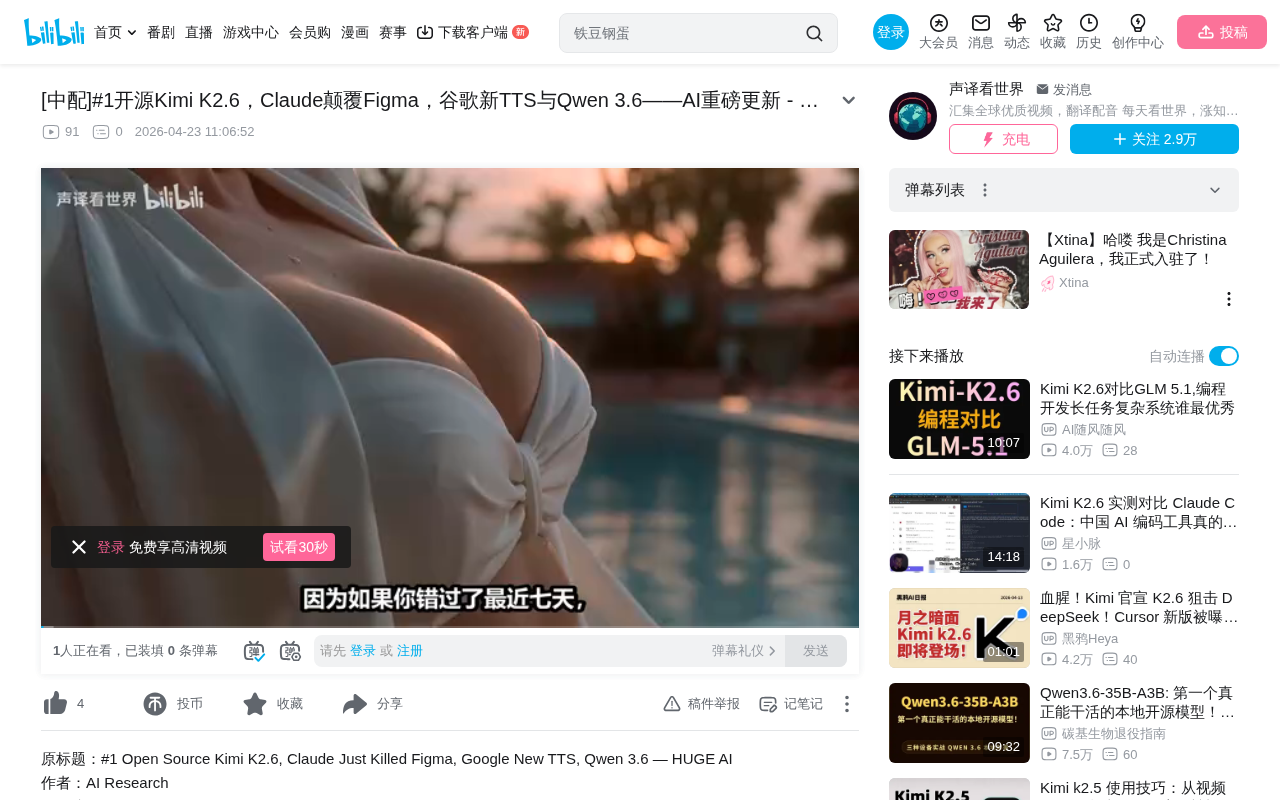
AI Weekly: Kimi K2.6 Tops Open-Source Rankings, Qwen 3.6 and Google TTS Launch Together
Weekly AI roundup: Kimi K2.6 tops open-source rankings, Anthropic launches Opus 4.7 and Claude Design, Alibaba rolls out Qwen 3.6 series, Google releases emotion-controllable TTS model.
Read more →
 Tutorials
Tutorials·2 min
Gemini 3.0 Pro + Claude Opus 4.5: A Practical Guide to Dual-Model Programming Workflows
Compare Gemini 3.0 Pro and Claude 4.5 Opus in programming tasks, build a dual-model workflow with KiloCode for architecture planning and code execution.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
GPT-5.2 Released: The Truth and Concerns Behind Its 390x Efficiency Gain
OpenAI releases GPT-5.2 with a 390x efficiency gain on ARC-AGI, beating Claude Opus 4.5. Deep analysis of the efficiency leap, user experience paradox, Disney's $1B deal, and the AI content quality crisis.
Read more →
 Product Reviews
Product Reviews·2 min
Kimi K2.6 In-Depth Review: Comprehensive Evaluation of Coding, Multi-Agent, and Frontend Development Capabilities
In-depth review of Kimi K2.6 open-source model across frontend development, multi-agent collaboration, and long-horizon tasks, covering four professional modes, 3D/SVG generation, and pricing analysis.
Read more →
 Product Reviews
Product Reviews·3 min
Gemini 3.1 Pro vs Claude Opus 4.6: Five Real-World Tests to Determine the Winner
Hands-on comparison of Gemini 3.1 Pro vs Claude Opus 4.6 across five real-world tests including SVG generation, interactive components, website building, and complex reasoning, with practical usage recommendations.
Read more →
 Product Reviews
Product Reviews·2 min
Kimi K2.6 Open-Source Hands-On: How Strong Is Its Orchestration of 300 Concurrent Agents?
Deep analysis of Moonshot AI's open-source Kimi K2.6 Agent orchestration: 300 sub-Agents executing 4000-step tasks, outperforming GPT-5.4 in coding benchmarks, LoRA fine-tuning on 2x RTX 4090s.
Read more →
 Product Reviews
Product Reviews·3 min
Claude 4.5 vs Gemini 3 Pro: A Comprehensive Coding Showdown
In-depth comparison of Claude 4.5 vs Gemini 3 Pro across five benchmarks including ARC-AGI-V2, SWE-Bench, and Terminal Bench 2.0, revealing their real coding and reasoning strengths.
Read more →
 Product Reviews
Product Reviews·3 min
Kimi K2.6 In-Depth Review: A Complete Breakdown of Its Coding and Agent Capabilities
In-depth review of Kimi K2.6's coding, Agent collaboration, and visual development capabilities. #1 open-source on SWE-Bench Pro, 300 parallel sub-agents, API priced at 1/3 of competitors.
Read more →