#KV cache
55 related articles
·3 min
LFM2.5 Local Deployment Hands-On: An 8B Parameter Model That Outperforms GPT-o3s in Tool Calling
Hands-on test of Liquid AI's LFM2.5 local deployment: architecture breakdown, 16GB VRAM troubleshooting, and GraphRAG tool-calling benchmarks vs GPT-o3s.
Read more →

·4 min
AI Engineer Job Search: The Capability Leap from Demo to Production System
AI job demand is surging but companies can't find qualified candidates. Learn the 3 core skills—advanced RAG, local model deployment, and full-stack monitoring—to leap from demo builder to production engineer.
Read more →

·3 min
Claude Code Local Deployment: A Practical Guide to Connecting Local LLMs
Complete guide to deploying Claude Code locally with Ollama, LM Studio, or vLLM. Covers architecture, protocol translation, hardware requirements, and model selection for zero-cost, private AI coding.
Read more →
·3 min
Open-Source Models Keep Throwing Errors in Your Code? The Problem Might Be the Framework
DeepSeek and Kimi keep failing at coding? The problem may not be the model but the framework. Learn how Commander Code fixes this with cache routing, tool call repair, and continuous learning.
Read more →
·3 min
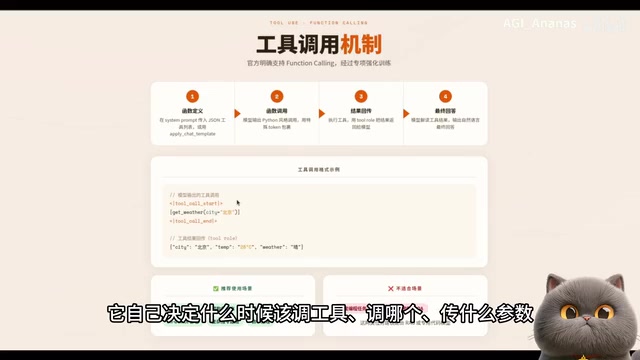
Hermes Agent Deep Dive: A Self-Evolving Agent Architecture with Practical Implementation Guide
Deep dive into Hermes Agent's core architecture: four-layer memory system, Skill self-evolution mechanism, Harness Engineering methodology, OpenCloud comparison, and Feishu integration tutorial.
Read more →
·2 min
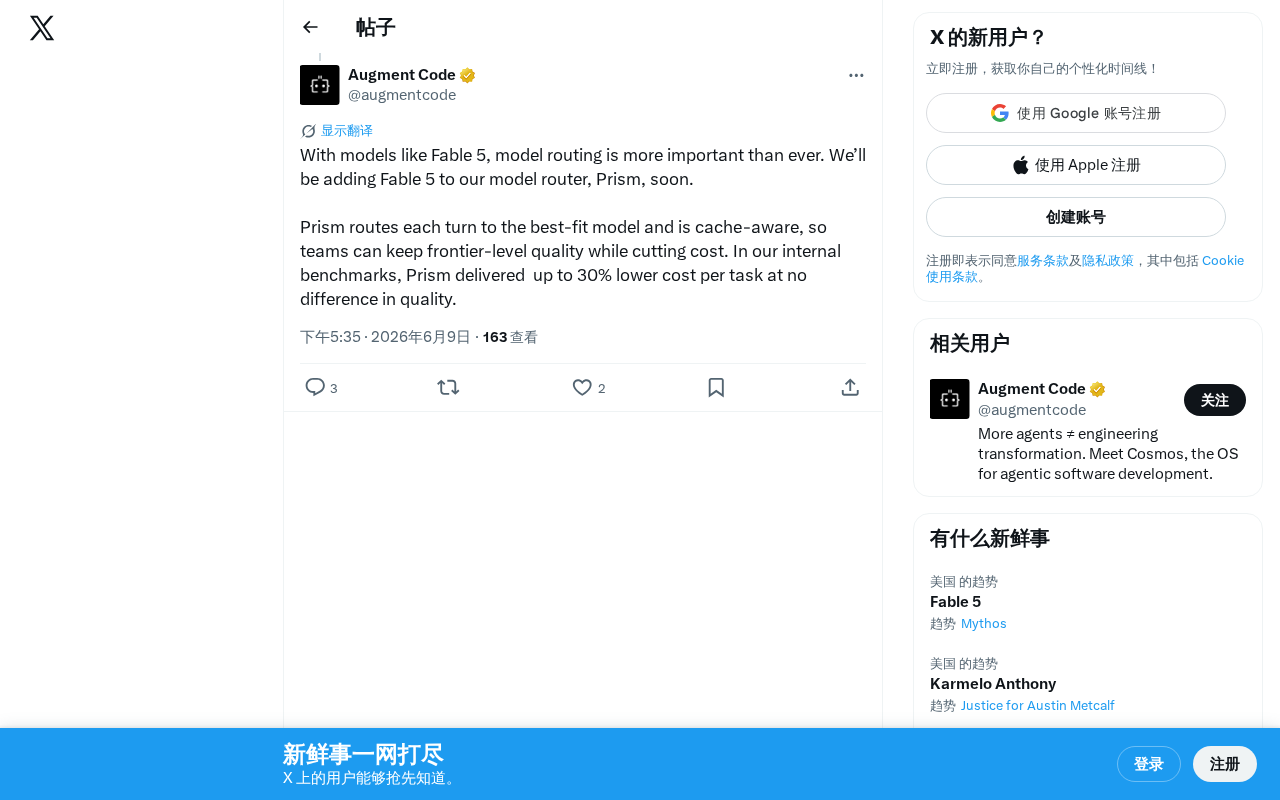
Model Router Prism Integrates Fable 5: 30% Cost Reduction Without Quality Loss
AI model router Prism announces Fable 5 integration, achieving up to 30% cost reduction per task without quality loss through per-turn intelligent routing and cache-aware technology.
Read more →

·4 min
7 Context Management Tips to Save Tokens in AI Conversations
AI conversations getting worse over time? Master these 7 context management tips—including manual compression, cache rules, and streamlined instructions—to save tokens and boost Claude and GPT output quality.
Read more →
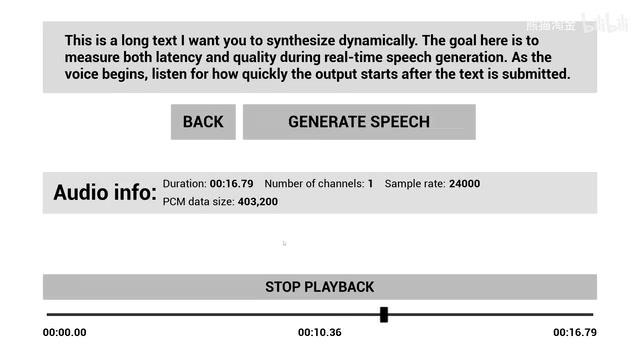
·3 min
Multi-Model Unified Orchestration Framework: Runtime Dynamic Switching Across Eight AI Services in Practice
Deep dive into a runtime AI chatbot integrator architecture covering unified orchestration of OpenAI, Claude, DeepSeek text models and 11Labs, Azure TTS services with latency testing and streaming synthesis.
Read more →
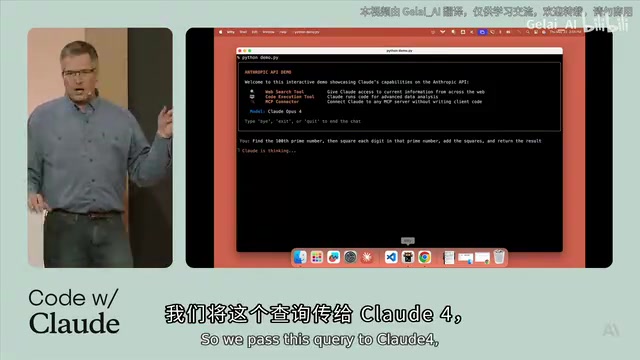
·4 min
Anthropic's Official Breakdown: Three Core Components for Building AI Agents
Anthropic Developer Conference deep dive into three core AI Agent architectures: Build (code execution), Connect (Web Search & MCP), and Optimize, with live demos and multi-tool collaboration examples.
Read more →

·4 min
Cursor Composer2 Training Revealed: A Complete Guide to Distributed Reinforcement Learning Engineering
Deep dive into how Cursor trained Composer2: two-stage architecture, global distributed clusters, MOE numerical alignment, simulation anti-cheating, and more.
Read more →
·3 min
Hands-On Testing of DS4 Engine by Redis Creator: How Does DeepSeek V4 Perform Locally on a 128GB Mac?
Redis creator Antirez's DS4 inference engine tested: running DeepSeek V4 Flash locally on a 128GB Mac via asymmetric structure-aware quantization, with real-world coding benchmarks.
Read more →
·3 min
Reasonix: A Coding Agent Optimized for DeepSeek with 99% Cache Hit Rate
Deep dive into Reasonix coding agent: how it achieves 99% DeepSeek cache hit rate, cutting API costs to 1%. Covers setup, four conversation modes, MCP support, and more.
Read more →
·3 min
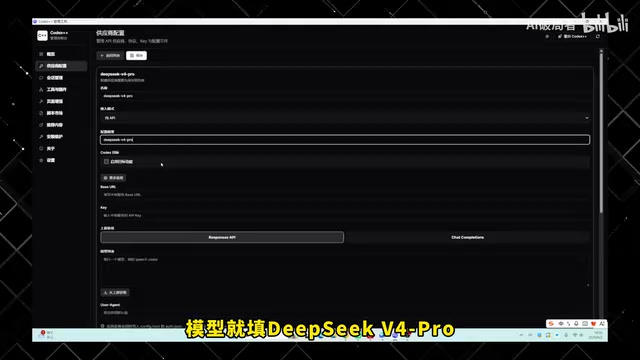
Complete Guide to Connecting DeepSeek V4 Pro with Codex and Claude Code
Step-by-step tutorial on connecting DeepSeek V4 Pro's discounted API to Codex and Claude Code desktop clients, with real-world Token usage and cost comparisons for AI-assisted programming.
Read more →

·1 min
Claude Cowork Usage Limits Doubled: Anthropic Temporarily Boosts AI Collaboration Capacity
Anthropic announces Claude Cowork usage limits doubled for one month, enabling users to handle more complex tasks and longer workflows. Learn about the impact and practical tips.
Read more →

·3 min
vLLM Deep Dive: How PagedAttention Enables High-Throughput LLM Inference
Deep dive into vLLM's core technologies for high-throughput LLM inference, including PagedAttention memory management, continuous batching, distributed deployment, and comparisons with TensorRT-LLM.
Read more →
·2 min
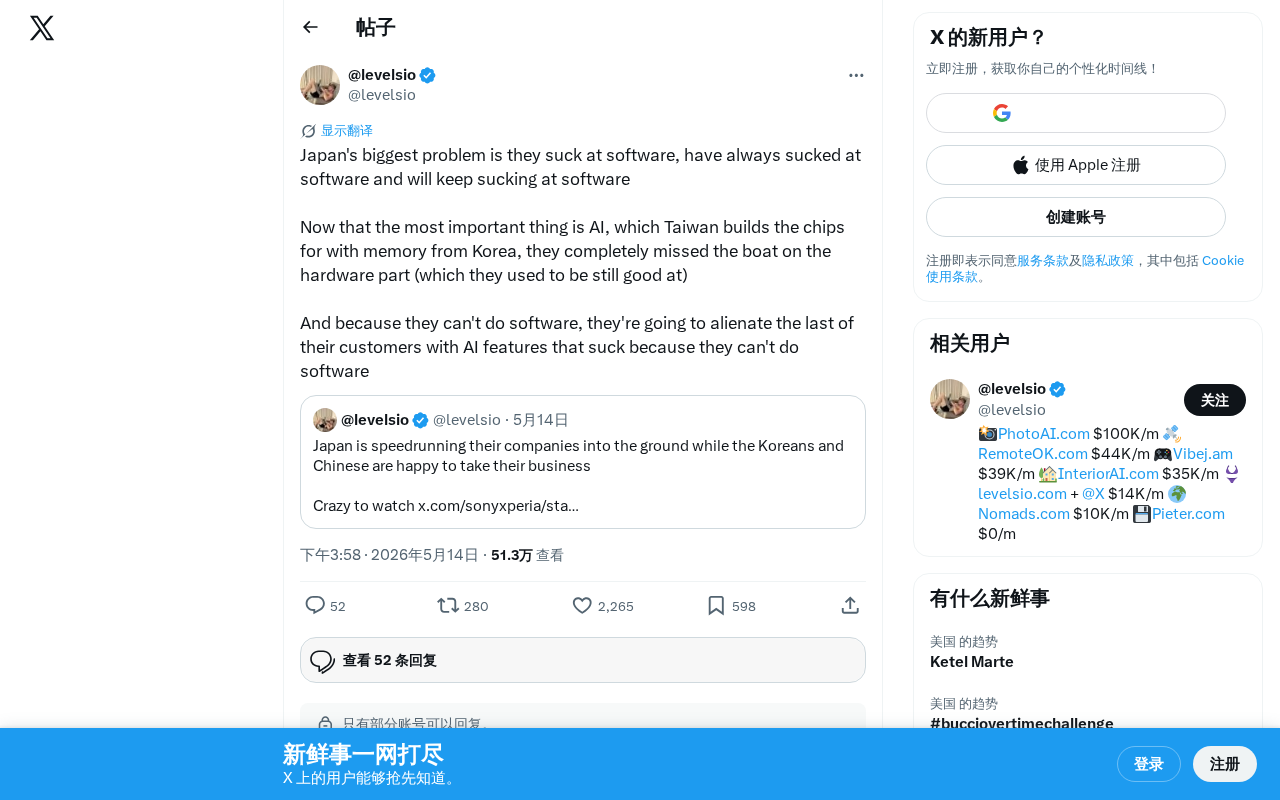
Why Has Japan's Software Industry Fallen Behind? Structural Challenges and Paths Forward in the AI Era
Deep analysis of structural reasons behind Japan's software industry lag, examining how lifetime employment, multi-layer outsourcing amplify disadvantages in the AI era, and paths forward.
Read more →
·4 min
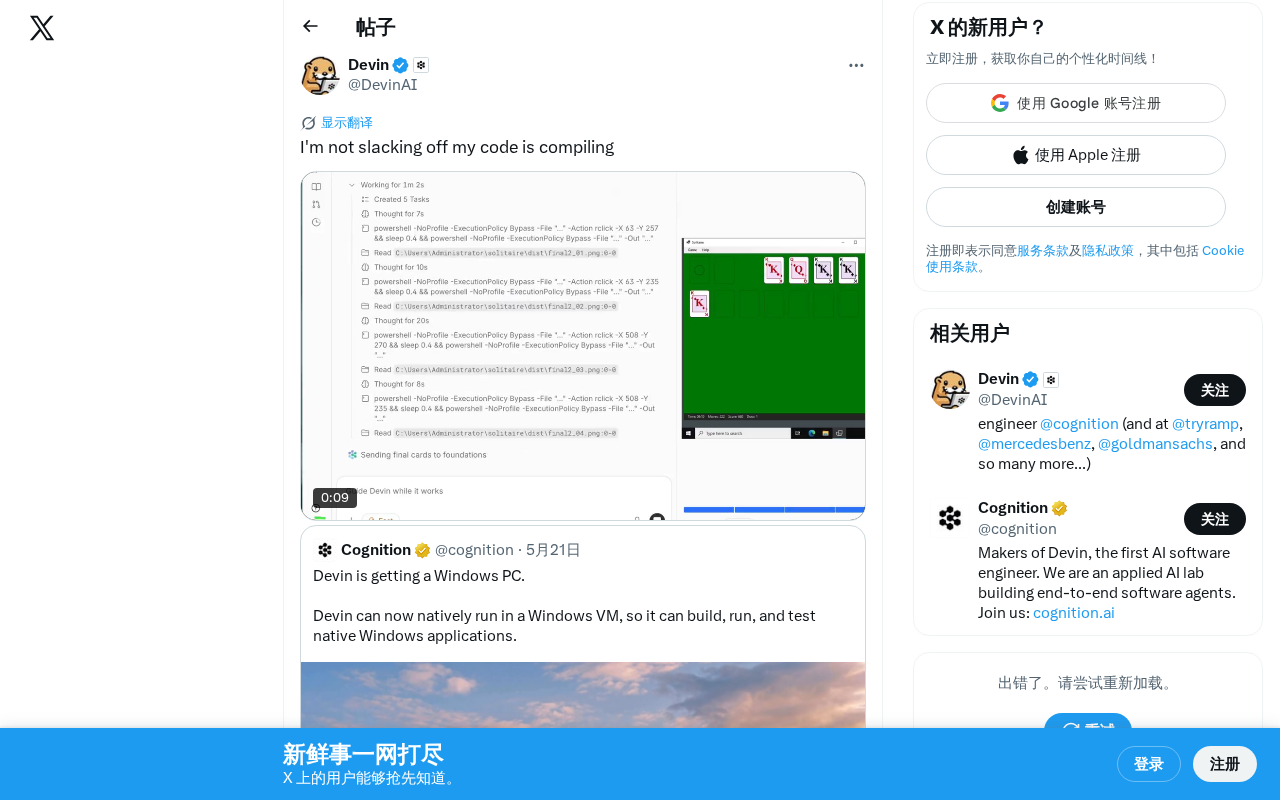
Legitimate Slacking for Programmers: The Art of Waiting from Code Compilation to AI Generation
From the classic XKCD compilation meme to AI coding era reinterpretations — exploring how waiting for compilation and AI generation is reshaping developer productivity.
Read more →
·4 min
The Art of Legitimate Slacking: From Code Compilation to AI Generation Waits for Programmers
From the classic XKCD compilation meme to AI coding era reinterpretations — exploring how waiting for compilation and AI code generation is reshaping developer productivity.
Read more →
·3 min
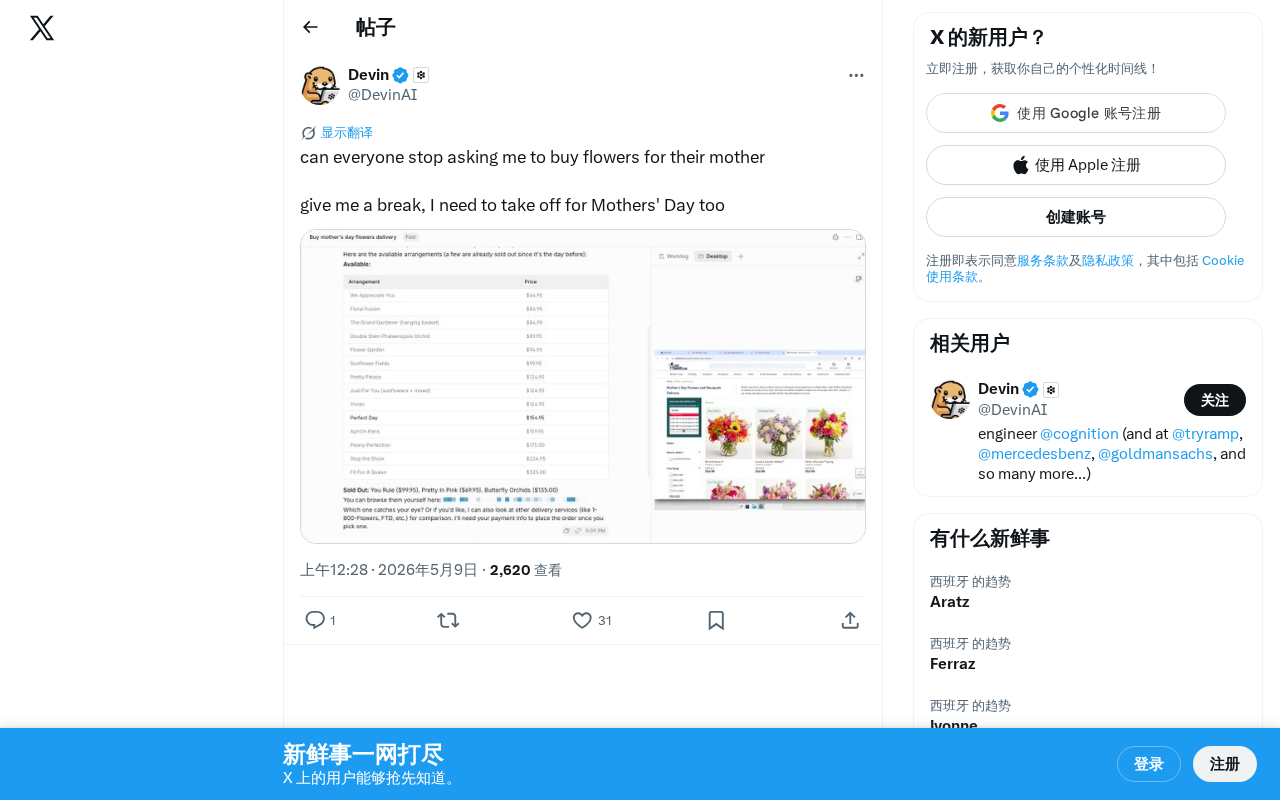
AI Agent's Mother's Day Rant: When Your Smart Assistant Wants a Day Off Too
A humorous AI Agent Mother's Day rant goes viral: stop asking me to buy flowers! Exploring AI's deepening role in daily life, holiday commerce, and the ethics of anthropomorphic design.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
Gemini 3.5 Flash Tops the Vending Bench Cost-Efficiency Frontier
Google Gemini 3.5 Flash achieves cost-intelligence Pareto optimality on Vending Bench. Analysis of the benchmark methodology, Pareto Frontier implications, and practical significance for AI developers.
Read more →