#state management
126 related articles
·3 min
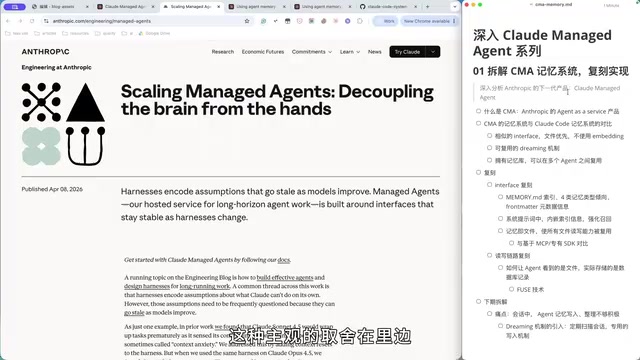
Deep Dive into Claude Cloud Agent Memory System Architecture: CMA Design Philosophy and Technical Choices
Deep analysis of Anthropic's Cloud Managed Agents memory architecture, covering file-first strategy, memory store reuse, Dreaming async consolidation, and key differences from Claude Code's memory system.
Read more →
·1 min
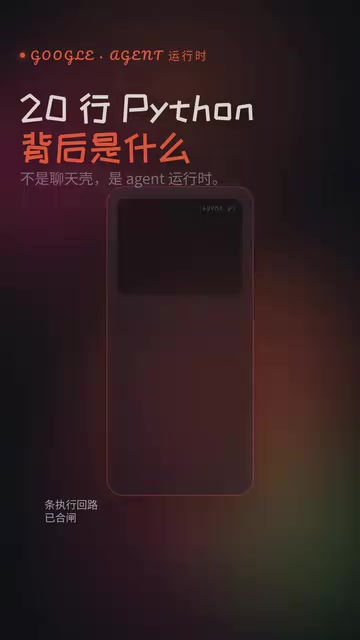
Antigravity SDK Hands-On: The Google Agent Runtime Behind 20 Lines of Python
Deep dive into Google's Antigravity SDK: its binary runtime architecture, key differences from Pydantic AI and LangGraph, installation pitfalls, and practical edge-case recommendations.
Read more →
·2 min
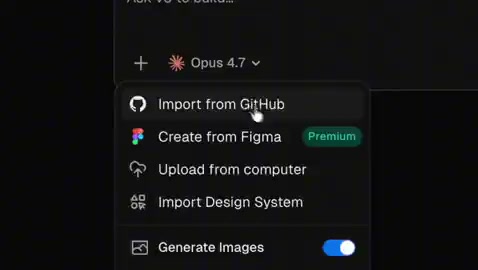
v0 Figma Integration: One-Click Conversion from Design Files to High-Fidelity Functional UI Code
Vercel's AI tool v0 launches a new Figma integration that parses layouts, typography, components, icons, and more to convert static designs into high-fidelity, runnable frontend code.
Read more →
·3 min
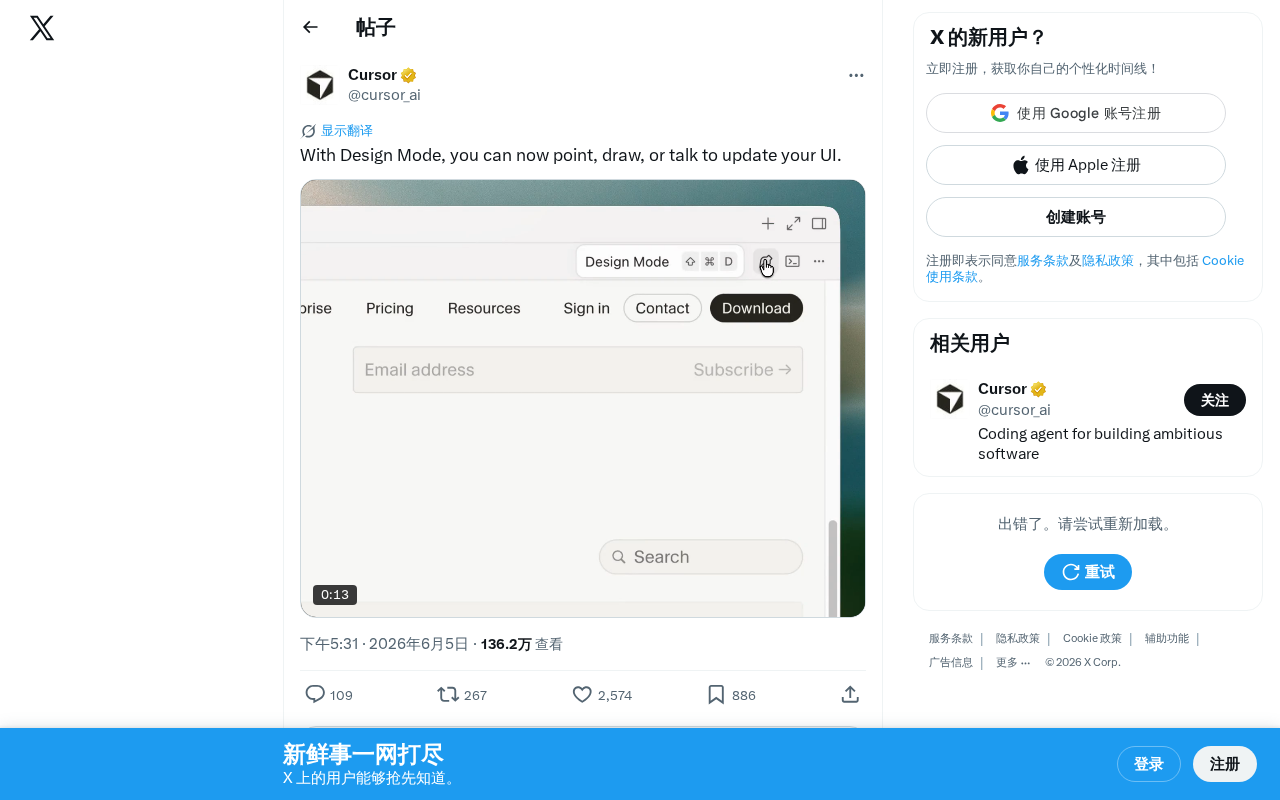
Design Mode: Update UI in Real Time by Pointing, Drawing, or Speaking
Design Mode is a new UI design interaction method supporting point, draw, and voice to directly modify interfaces in real time. Learn how it works and its impact on development.
Read more →
·2 min
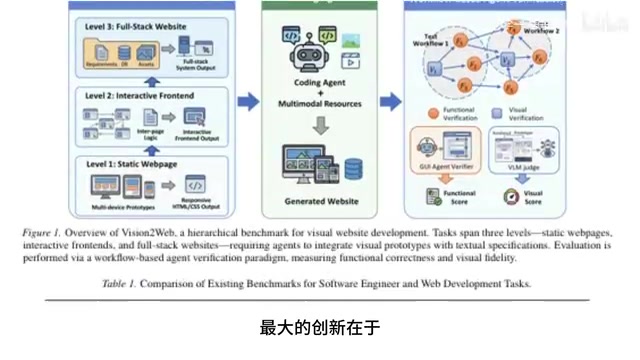
Tsinghua and Zhipu Release Full-Stack Web Dev Benchmark: Top AI Models Fail Spectacularly
Tsinghua and Zhipu AI release a full-stack web dev benchmark with three difficulty levels. Top models like Gemini 2.5 Pro see scores plummet from 63 to 11.7 on full-stack tasks, exposing AI's real limits.
Read more →

·3 min
GPT-5.2 Codex vs Opus 4.5 Hands-On: A Comprehensive Comparison of Coding Ability, Speed, and Developer Experience
Hands-on comparison of GPT-5.2 Codex vs Opus 4.5 across frontend generation, physics simulation, 3D scenes, and code refactoring, with practical selection advice.
Read more →
·4 min
Real-World Comparison of Chinese AI Coding Models: Which One Best Generates a Complete E-Commerce System in One Shot?
Real-world test of six Chinese AI coding models — Qwen 3.7 Max, DeepSeek V4 Pro, MiniMax M3 and more — generating a complete e-commerce system, scored on UI, checkout flow, and backend management.
Read more →
·3 min
CreateNow Controlled Development in Practice: Getting AI to Write Code Requirement by Requirement
Hands-on with CreateNow's controlled AI development: from requirements breakdown to modular coding. Covers model selection, breakpoint-resume, and acceptance checks.
Read more →
·3 min
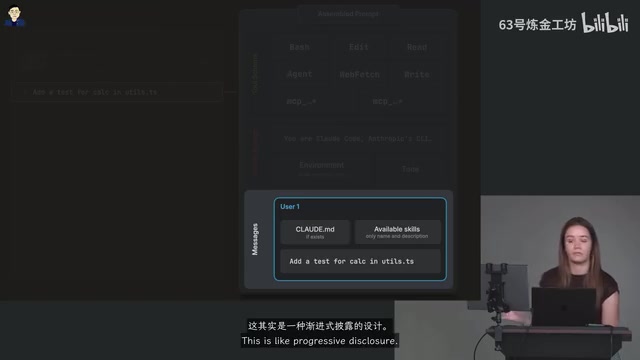
Deep Dive into How Claude Code Works: Prompt Assembly, Permission Control, and the Skills Mechanism
Deep dive into Claude Code internals: stateless model principles, four-layer prompt assembly, Agentic Loop execution, permission control, and reusable Skills workflow templates for agentic engineering.
Read more →

·2 min
Codex vs Claude Code In-Depth Comparison: How Frontend and Backend Developers Should Choose
In-depth comparison of Codex vs Claude Code across pricing, stability, and capability focus—analyzing differences in frontend UI and backend logic development with workflow recommendations.
Read more →
·4 min
AI Agent Global Variable Pool & Memory Mechanisms: A Practical Guide to Workflow Node Data Passing
Deep dive into global variable pool design for AI Agent development, covering three memory types, variable scoping, node execution architecture, and placeholder variable replacement workflows.
Read more →

·4 min
Self-Study Guide to AI Agent Development: A Complete Path from Zero to Production
A practical self-study roadmap for AI Agent development: covering core skills, common pitfalls, phased learning plans, and interview prep to help developers go from concept collectors to builders.
Read more →

·3 min
LangChain from Beginner to Agent Development: A Complete Learning Path for LLM Application Development
A systematic guide to LangChain LLM application development, covering environment setup, core components (RAG, Chain, Memory), and Agent development to help developers master LLM app building.
Read more →
·3 min
Codex Beginner's Guide: Lessons Learned from 660 Million Tokens of Real-World Usage
Deep dive into OpenAI Codex Agent's core features, Skill ecosystem, context compression, and project-level Harness management tips from 660M tokens of real-world usage.
Read more →
·2 min
Rebuilding a Complete GUI App with DeepSeek for Just $2.50: A Real-World AI Programming Cost Breakdown
A Bilibili creator used DeepSeek V4 Pro via Cursor to rebuild a complete IndexTTS GUI app for just 18.63 RMB (~$2.50). Full breakdown of the AI coding workflow, features, and cost comparison.
Read more →

·3 min
rsync Hit by AI Code Invasion: 36 Commits Trigger Open Source Infrastructure Trust Crisis
After rsync maintainer used Claude AI for 36 code commits, incremental backup functionality broke. Alpine Linux and Debian discuss rollbacks, exposing deep tensions between AI code quality and open source maintenance.
Read more →

·2 min
Cosmos Unified Agents Platform: A New Paradigm for AI Agent Collaboration Through Shared Context and Memory
Deep dive into how the Cosmos Unified Agents Platform solves multi-AI Agent collaboration challenges through shared context and memory mechanisms, and its positioning in enterprise multi-Agent orchestration.
Read more →
Firestore Enterprise Text Search: A Gu…
·2 min
Firestore Enterprise Text Search: A Guide to Implementing Real-Time Search in React
Learn how Firestore Enterprise's native text search works with React Hooks to build real-time search — covering debounce, state management, and more.
Read more →
·2 min
ViBench: A Benchmark Designed Specifically for Evaluating AI Application Building Capabilities
Deep dive into ViBench, a benchmark addressing SWE-bench's gaps in evaluating AI application building through end-to-end generation, visual quality, and functional completeness.
Read more →
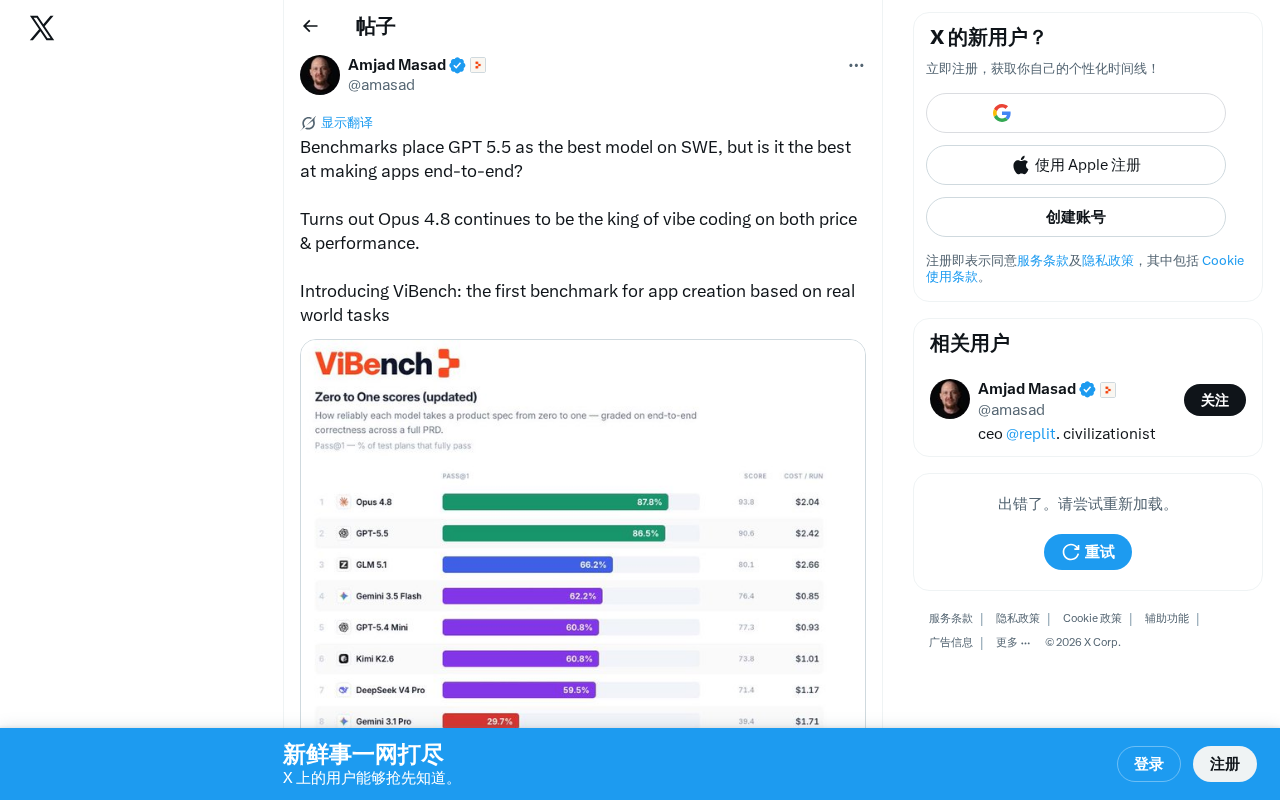
·2 min
ViBench Benchmark: End-to-End App Creation Evaluation Reveals the True Level of AI Programming
ViBench is the first end-to-end app creation benchmark based on real-world tasks. Results show Claude Opus 4.8 leads in performance and cost-effectiveness, revealing gaps between SWE-bench scores and actual development capability.
Read more →