#GPU
共 591 篇相关文章
 科技前沿
科技前沿·5 分钟
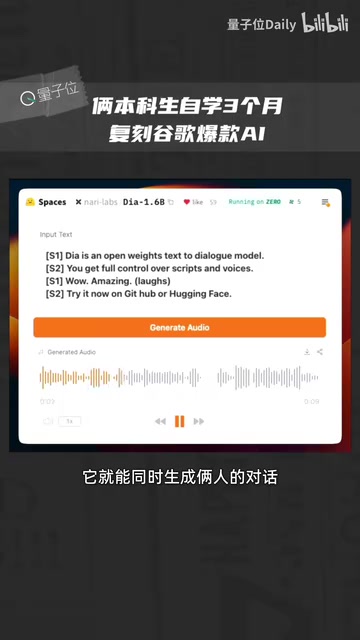
Dia开源项目一天5000星:两本科生3个月复刻NotebookLM播客功能
开源AI语音生成项目Dia上线一天GitHub星标破5000,由两名本科生自学3个月打造。1.6B参数实现近乎实时的双人对话生成,效果媲美谷歌NotebookLM,支持笑声、咳嗽等非语言细节模拟。
阅读全文 →
 深度解读
深度解读·1 分钟
GB200 NVL72拓扑感知调度:Slurm如何释放Exascale性能
深入解析NVIDIA GB200 NVL72系统的Slurm拓扑感知作业调度方案,涵盖NVLink域配置、topology.conf定义、调度策略优化及NCCL性能验证,帮助数据中心充分释放百亿亿次计算性能。
阅读全文 →
 教程攻略
教程攻略·1 分钟
Kubernetes集群GPU监控实战:实时掌握利用率的完整方案
详解Kubernetes集群中GPU使用率实时监控方案,涵盖NVIDIA DCGM、GPU Operator、Prometheus等核心组件的部署架构,以及从监控数据到资源优化的最佳实践,帮助平台团队最大化AI基础设施投资回报。
阅读全文 →
 产品体验
产品体验·5 分钟
QwenCoder本地部署实测:能否替代付费AI编程助手?
实测QwenCoder 80B本地部署效果,对比Gemini、Claude等付费AI编程工具。详解硬件配置、LM Studio部署方案及实际编程能力测试结果,帮你判断本地模型能否省下AI订阅费。
阅读全文 →
 教程攻略
教程攻略·5 分钟
Spring AI 2.0实战:一小时搭建RAG知识库问答系统
基于Spring AI 2.0和Cursor AI编程工具,从零搭建RAG企业知识库问答系统。涵盖Ollama本地大模型部署、Redis向量数据库、文档解析与向量化、智能检索问答等完整技术方案,附详细开发流程与代码实现。
阅读全文 →
 教程攻略
教程攻略·7 分钟
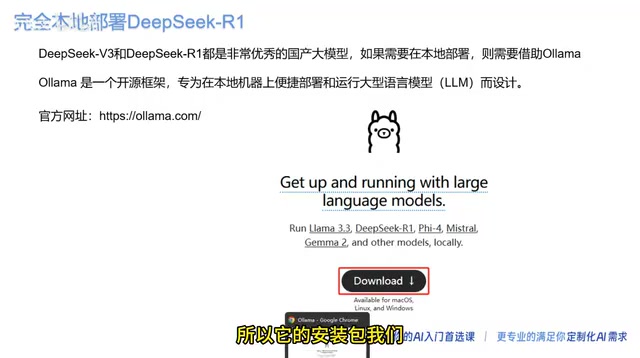
DeepSeek本地部署教程:Ollama一键安装运行指南
详细讲解如何通过Ollama在本地部署DeepSeek R1大模型,包括安装步骤、模型版本选择、硬件配置要求及进阶玩法,零基础10分钟搞定私有化AI部署。
阅读全文 →
 教程攻略
教程攻略·5 分钟
HuggingFace Transformers入门教程:模型下载、Pipeline推理到训练保存
详解HuggingFace Transformers核心用法,涵盖预训练模型下载配置、Pipeline API情感分析实战、Tokenizer分词器原理、模型推理Softmax处理及保存复用完整流程,附Python代码示例。
阅读全文 →
 教程攻略
教程攻略·6 分钟
本地部署大模型怎么判断显存爆了?一文看懂显存监控方法
本地部署大模型时如何判断显存是否爆满?本文详解专用显存与共享GPU内存的区别,教你通过任务管理器快速判断显存溢出,并提供模型量化、上下文长度控制等避免爆显存的实用建议。
阅读全文 →
 科技前沿
科技前沿·5 分钟
Anthropic每月花12.5亿美元租xAI算力,AI竞赛背后的天价交易
SpaceX S-1文件披露Anthropic与xAI签署每月12.5亿美元算力租赁协议,租用COLOSSUS超算集群至2029年,总额约450亿美元。竞争对手之间的算力合作揭示AI行业算力极度稀缺的真实现状。
阅读全文 →
 产品体验
产品体验·5 分钟
Veo 4.0视频生成效果实测:两段视频吃掉86%算力配额
实测谷歌Veo 4.0视频生成效果,画质接近专业MV水准,但Pro用户生成两段视频即消耗86%算力配额。本文详解Veo 4.0在场景渲染、人物动作、光影表现等方面的实际表现,并分析其算力定价策略对创作者的影响。
阅读全文 →
 产品体验
产品体验·4 分钟
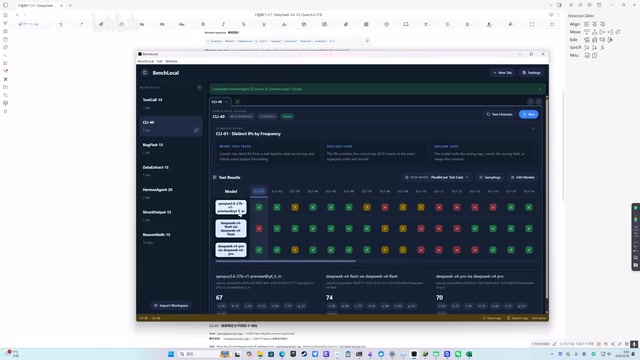
DeepSeek V4 vs Qwen3.6实测:8大类150场景深度对比评测
使用BenchLocal工具对DeepSeek V4 Pro、V4 Flash与Qwen3.6 27B进行8大类85场景实测对比,涵盖工具调用、代码调试、推理数学等维度,V4 Pro总分领先6%但数学推理意外翻车,Qwen3.6 Q6在智能体场景媲美V4 Pro。
阅读全文 →
 教程攻略
教程攻略·6 分钟
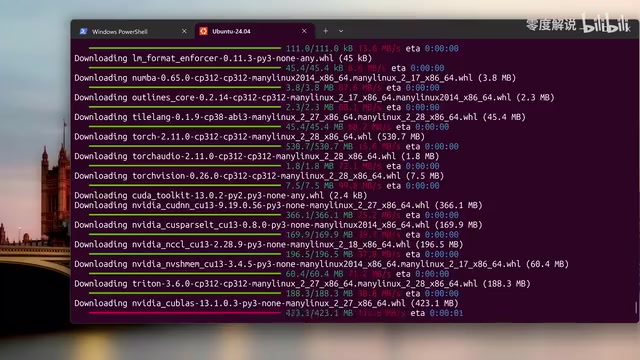
Hermes + Qwen3.6 本地部署教程:零成本搭建私有AI Agent
详细教程教你用Hermes Agent搭配Qwen3.6开源大模型,在本地零成本部署私有AI助手。涵盖WSL环境配置、模型下载启动、Telegram机器人对接及开机自启设置,实现无限Token、数据私有的AI Agent体验。
阅读全文 →
 产品体验
产品体验·4 分钟
Qwen3.6 27B三大邪修量化模型实测:代码暴增15.8PP、40B蒸馏、16GB适配
实测对比三款基于Qwen3.6 27B的社区邪修量化模型:OmniMerge V4代码能力提升15.8个百分点,40B OPUS蒸馏版支持角色扮演与创意写作,16GB特化版让小显存也能跑稠密模型。附显存要求、参数设置与选型建议。
阅读全文 →
 教程攻略
教程攻略·5 分钟
vLLM与SGLang本地部署教程:性能提升3-8倍的实战指南
详解vLLM和SGLang本地部署全流程,对比LM Studio性能差距,通过Docker+AI助手三步完成部署。涵盖SGLang与vLLM选型建议、5090显存优化、Qwen3模型推荐及Cherry Studio接入方法。
阅读全文 →
 科技前沿
科技前沿·4 分钟
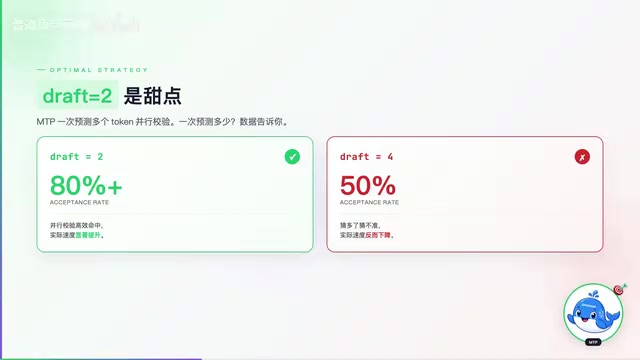
Qwen3.6 MTP加速实测:单GPU推理飙到220 token/s
Qwen3.6实验性MTP-GGUF版本实测,单GPU将35B-A3B模型推理速度提升至220 token/s,比原版快1.4倍且精度零损失。详解MTP原理、最优Draft Tokens策略及RTX 5090实测数据。
阅读全文 →
 行业洞察
行业洞察·5 分钟
企业大模型选型指南:Llama3.1、Qwen2.5、DeepSeek深度对比
企业如何选择开源大模型?本文从模型能力、硬件需求、业务场景三个维度,深度对比Llama 3.1、Qwen 2.5、DeepSeek、Mistral等主流开源模型,提供选型决策框架与实践建议。
阅读全文 →
 深度解读
深度解读·5 分钟
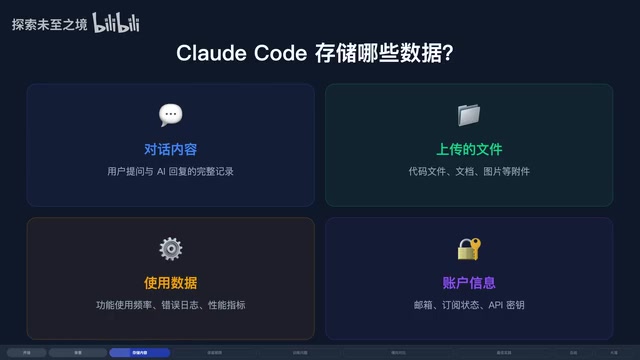
Claude Code会保存你的代码吗?隐私政策全解析
深度解析Claude Code隐私政策:代码数据存储时长、是否用于模型训练、与Cursor和GitHub Copilot隐私对比,以及5条实用隐私保护建议,帮助开发者安全使用AI编程工具。
阅读全文 →
 行业洞察
行业洞察·6 分钟
AI工具涨价潮来袭:Copilot翻四倍,免费午餐终结
GitHub Copilot价格翻四倍、Claude Code功能被砍又恢复,AI工具正加速进入收割期。从按用户收费到按Token计费,风投烧钱补贴模式走向终结,开发者和企业该如何应对AI涨价潮?
阅读全文 →

