#LLM inference
41 related articles
 Tech Frontiers
Tech Frontiers·2 min
OpenAI Voice Hackathon: 4 Real-Time Voice AI Projects Built in Just 6 Hours
OpenAI hosted Voice Hack Night where teams built 4 real-time voice agent projects in 6 hours. Deep analysis of technical challenges, use cases, and developer ecosystem trends in real-time voice AI.
Read more →
 Research
Research·2 min
Agent Loops in Practice: Transforming Token Output into Productivity from CUDA Kernels to Automated Research
Deep dive into how the Humanize framework transforms LLM tokens into engineering productivity via Agent Loops. Covers KDA winning CUDA kernel contests, virtual hardware optimization, and 50% research cost reduction.
Read more →
 Tutorials
Tutorials·2 min
Tutorial: Deploying a PD-Disaggregated SGLang Multi-Node Inference Cluster on AMD GPUs
Learn how to deploy a PD-disaggregated SGLang inference cluster on AMD GPUs using a single config file, boosting LLM throughput and latency performance.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
SGLang v0.5.12.post1 Released: DeepSeek V4 Stability Fixes and Blackwell Adaptation
SGLang v0.5.12.post1 stability patch details: 12 critical fixes covering DeepSeek V4 garbled text and crashes, NIXL PD disaggregated inference logic, Blackwell B300 adaptation, and cold start optimization.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
Step 3.7 Flash: Deep Dive into the 198B Sparse MoE Multimodal Model
Deep dive into StepFun AI's Step 3.7 Flash, a 198B sparse MoE vision-language model with 256K context and 3-level reasoning, excelling in multimodal understanding, AI coding, and Agent tool orchestration.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
LFM2.5-8B-A1B: A MoE Model with 1.5B Active Parameters Delivering 4x Its Weight Class Performance
Liquid AI releases LFM2.5-8B-A1B, a MoE model with 8B total params but only 1.5B active, matching 6B-class models in tool calling. Supports 128K context, local deployment, multilingual, with SGLang Day-0 support.
Read more →
 Industry Insights
Industry Insights·2 min
SGLang Enters Finance: How AI Inference Infrastructure Is Reshaping Wall Street
SGLang co-hosts a finance AI inference event with Crusoe AI and Cloudflare, exploring LLM inference deployment in trading, risk management, and compliance — signaling Wall Street's shift to production-grade AI infrastructure.
Read more →
 Industry Insights
Industry Insights·2 min
AMD MI355X Beats B200: Full-Stack Optimization Breakdown for 5% Lower TCO on DeepSeek-R1 Inference
AMD Instinct MI355X achieves 5% lower TCO than NVIDIA B200 on DeepSeek-R1 disaggregated inference via SGLang+MoRI full-stack optimization with 1.25x per-GPU throughput.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
Cloudflare Contributes Critical KV Cache and Mooncake Fixes to SGLang
Cloudflare contributes decode KV cache offload and Mooncake recovery fixes to SGLang, resolving garbled output under high concurrency for Kimi K2.6 and enabling automatic fault recovery in distributed inference.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
SGLang Hosts Agent Loops Office Hour, Focusing on Agentic Loop Architecture Optimization
SGLang team hosts an Agent Loops Office Hour exploring inference optimization for agentic loops, covering KV Cache reuse, low-latency multi-turn dialogue, and tool calling techniques.
Read more →
Industry Insights
Deep Dive into Three Major LLM Career …
·3 min
Deep Dive into Three Major LLM Career Paths: Requirements, Tech Stacks, and Career Prospects
Deep analysis of three core LLM roles—Application Engineer, Development Engineer, and Algorithm Engineer—covering technical requirements, salary thresholds, and career prospects including RAG, fine-tuning, and inference deployment.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
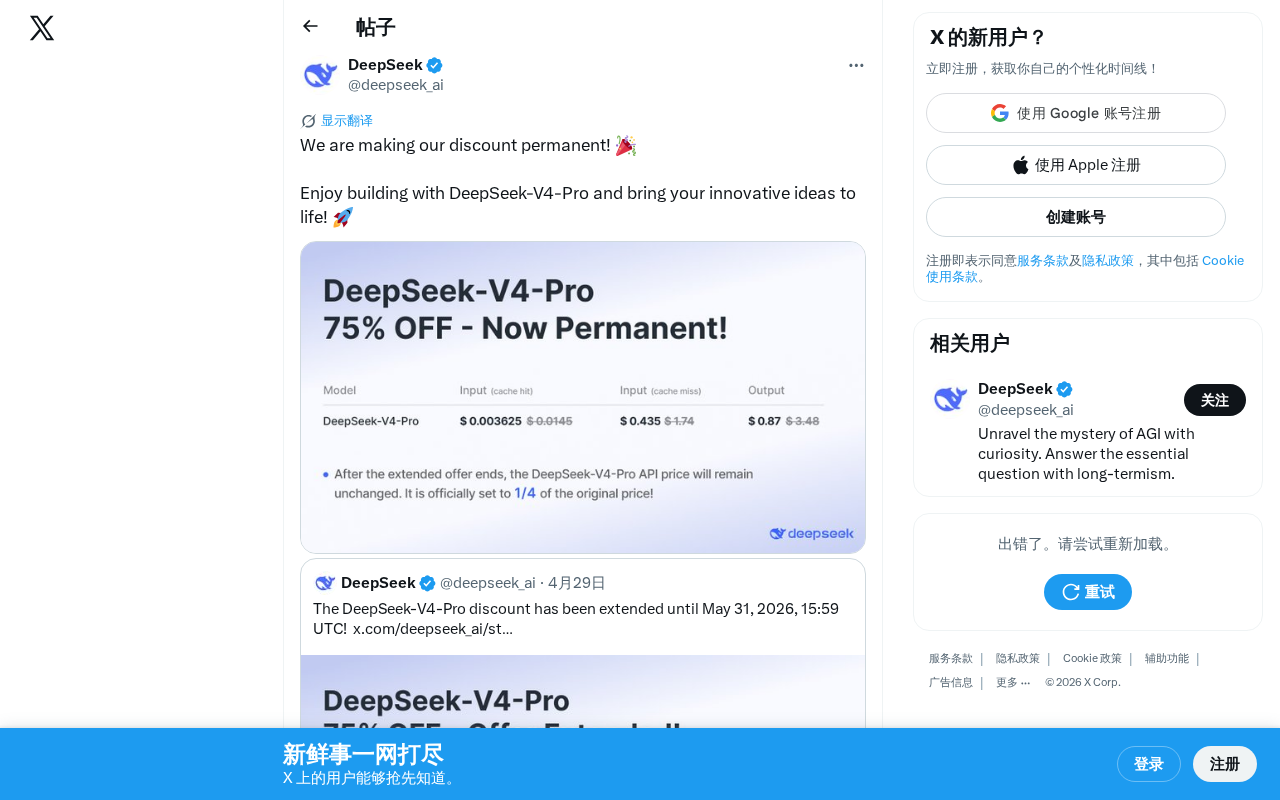
DeepSeek V4-Pro Permanent Price Cut: Lower Developer Costs as LLM Price War Heats Up
DeepSeek announces permanent discount pricing for its V4-Pro model. Learn how this impacts developers, V4-Pro's competitive edge, and the latest LLM price war trends.
Read more →
 Product Reviews
Product Reviews·3 min
Devin 2.0 In-Depth Review: Is the $20/Month AI Coding Agent Actually Worth It?
In-depth analysis of Devin 2.0: dropped from $500 to $20/month, 12x efficiency in code migration, but only 15% completion on complex tasks. Real test data on use cases and limitations.
Read more →
Product Reviews
Local Deployment of Qwen 3.6 27B on 4×…
·3 min
Local Deployment of Qwen 3.6 27B on 4×3080Ti: Real-World Coding Test with OpenCode
Real-world test of Qwen 3.6 27B FP8 deployed on 4×3080Ti 16GB modded GPUs with OpenCode for system tool development. Covers hardware setup, inference speed, context management, and productivity gains.
Read more →
Product Reviews
AI Coding Appliance vs Cloud LLMs: Can…
·2 min
AI Coding Appliance vs Cloud LLMs: Can ¥480K in Annual Fees Buy 4 Local Deployment Solutions?
A deep cost comparison between AI coding appliances and cloud LLM APIs. A 20-person team spending ¥480K/year on tokens can deploy 4 local OnePanel units at ¥99K each, breaking even in 2.5 months.
Read more →
 Industry Insights
Industry Insights·2 min
NVIDIA Blackwell Sets New STAC-AI Records for Financial LLM Inference
NVIDIA Blackwell GPU sets new LLM inference records in STAC-AI financial benchmark. Explore Blackwell architecture advantages, TensorRT-LLM co-optimization, and LLM applications in trading and risk management.
Read more →
Tutorials
Enterprise AI Agent Four-Layer Archite…
·3 min
Enterprise AI Agent Four-Layer Architecture Design and PDCA Continuous Optimization Practical Guide
Deep dive into enterprise AI Agent four-layer architecture design (User, Gateway, Agent Service, Capability layers) with PDCA optimization methodology and dual manual+automated evaluation for production-grade Agent systems.
Read more →
Product Reviews
AI Coding Tools Keep Crashing When Bui…
·2 min
AI Coding Tools Keep Crashing When Building Websites? Root Cause Analysis & Practical Solutions
AI coding tools crashing when building websites? This article analyzes root causes including multi-window concurrency, API rate limiting, and network instability, with practical solutions.
Read more →
 Product Reviews
Product Reviews·3 min
DLSS 4.5 Deep Integration with UE5 and Multilingual AI Characters: Major NVIDIA RTX Game Development Update
NVIDIA releases major RTX update with DLSS 4.5 deep UE5 integration for frame generation performance leaps and multilingual AI characters supporting dynamic dialogue with real-time speech synthesis.
Read more →
Tech Frontiers
Google Anti-Gravity 2.0 Explained: The…
·1 min
Google Anti-Gravity 2.0 Explained: The Multi-Agent Development Platform Replacing Gemini CLI
Google Anti-Gravity 2.0 officially replaces Gemini CLI with a desktop app, CLI terminal, and SDK. Powered by Gemini 3.5 Flash, it supports multi-Agent parallel collaboration and one-click Managed Agents deployment.
Read more →