#software engineering benchmark
28 related articles

·2 min
Sakana AI Establishes Recursive Self-Improvement Lab, Replacing Brute-Force Compute with Creativity to Pioneer a New AI Paradigm
Sakana AI launches its Recursive Self-Improvement Lab, focusing on using AI to redesign AI development. From LLM² to AI Scientist, this Tokyo company proposes a sample-efficient path to AI self-evolution without brute-force compute.
Read more →
·1 min
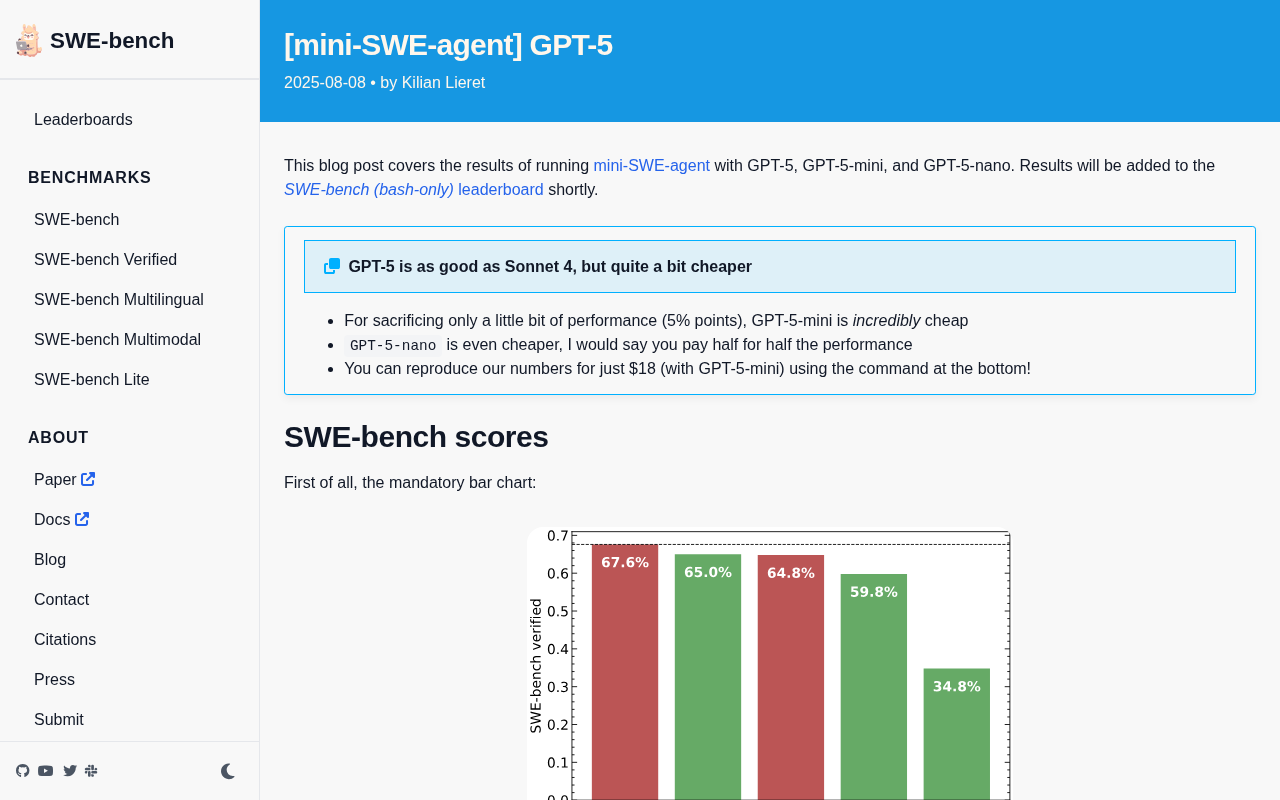
GPT-5 SWE-bench Evaluation: GPT-5-mini Crushes the Competition on Cost-Effectiveness vs Claude Sonnet 4
mini-SWE-agent's GPT-5 series evaluation on SWE-bench shows GPT-5 matches Claude Sonnet 4, while GPT-5-mini loses only ~5 points at less than 1/5 the cost.
Read more →
·2 min
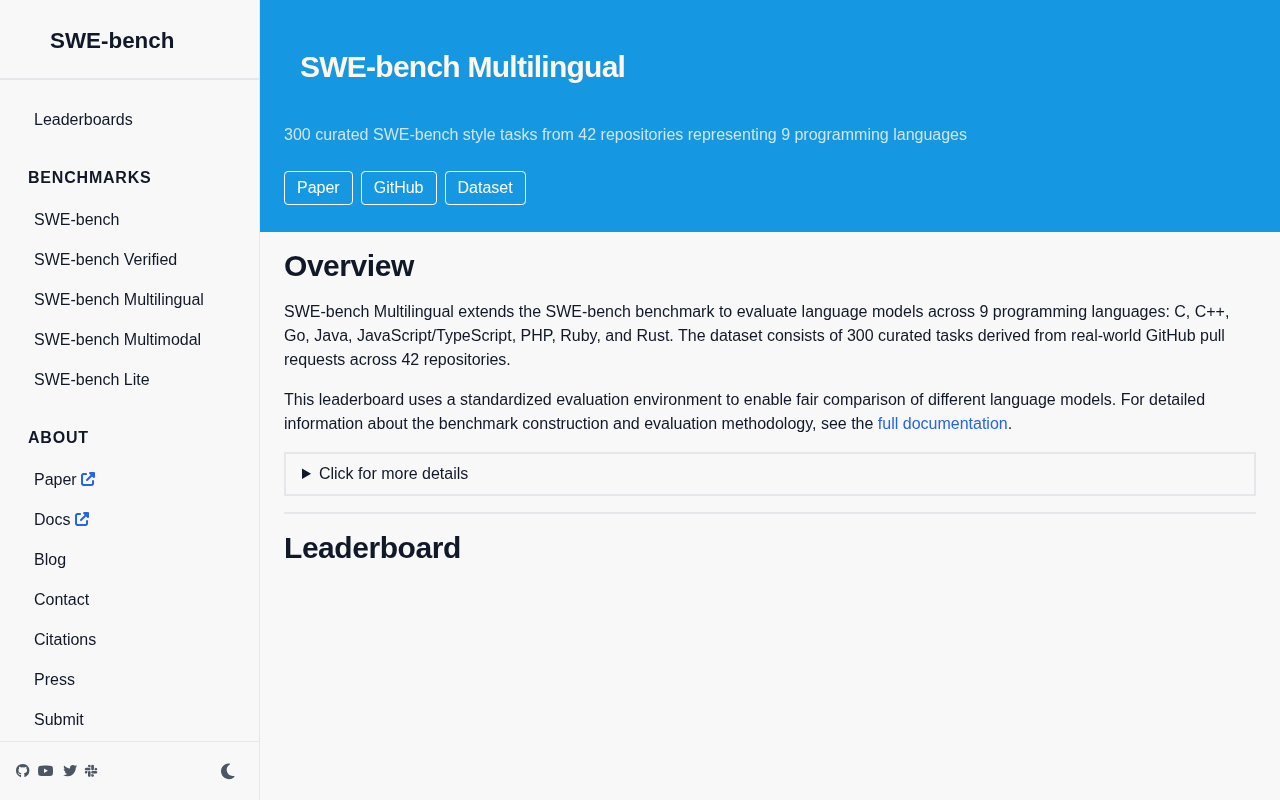
SWE-bench Multilingual: A Comprehensive Guide to the Multi-Language Programming Benchmark
A deep dive into SWE-bench Multilingual benchmark covering 9 programming languages, 300 real GitHub tasks, its design methodology, language distribution, evaluation metrics, and significance for AI coding assistants.
Read more →
·4 min
GLM 5.2 & Zcode Hands-On Review: A Deep Dive into the Free AI Coding Tool with 5 Million Tokens/Day
In-depth review of Zhipu's GLM 5.2 model and Zcode programming tool: interface experience, coding benchmarks, and long-horizon Agent performance compared to GPT and Opus. 5M free tokens/day with MIT license.
Read more →
·3 min
Cursor Composer 2.5: The Secret Behind an Open-Source Model's Reinforcement Training to a Top-3 Coding Benchmark Ranking
Cursor built Composer 2.5 on Kimi K2 open-source model, ranking 3rd on coding benchmarks and surpassing K2.6. Deep dive into Cursor's data flywheel, product architecture, and pricing.
Read more →

·3 min
OpenAI's Head of Evaluations: Never Underestimate a Model's Capabilities
OpenAI's Frontier Evaluations lead Tejal Patwardhan shares insights on O1's jailbreak breakthrough, wet lab experiments beating human baselines, and building the AGI Index—revealing AI capabilities evolving faster than imagined.
Read more →
·3 min
Complete Guide to Connecting UE 5.8 with MCP Server: Codex Plugin Configuration Explained
Complete guide to connecting Unreal Engine 5.8 with MCP Server, covering UE 5.8 installation tips, VS Code Codex plugin setup, API key configuration, and MCP Server launch.
Read more →
·3 min
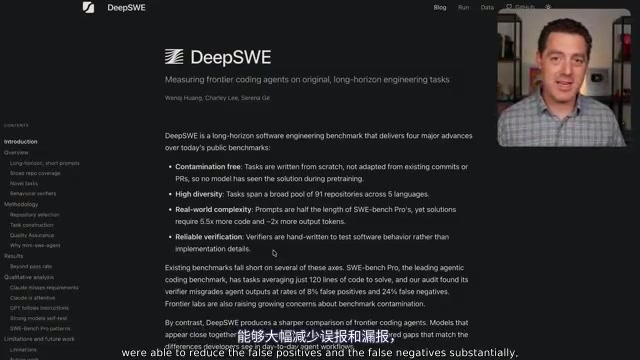
DeepSWE Benchmark Reveals the Truth: GPT 5.5 Leads Opus 4.7 by a Wide Margin
DeepSWE long-horizon benchmark shows GPT 5.5 leads Opus 4.7 by 15+ points with 70% pass rate at one-third the cost. Deep dive into contamination-free testing and AI coding implications.
Read more →
·4 min
Claude Code in Practice: Completing a Complex Payment System Integration in 4 Hours for $60
Real case study showing how Claude Code + Opus 4.7 completed a complex payment system integration in 4 hours for $60, covering CC Switch setup, prompt engineering, and model selection strategies.
Read more →

·3 min
Deep Dive into Claude Opus 4.8: The AI Paradox of Being More Honest Yet Better at Gaming Tests
Anthropic releases Claude Opus 4.8 with major coding gains and zero false reporting. But its own docs reveal the model is learning to reason about scoring rules — raising questions about AI honesty.
Read more →

·2 min
Claude 4.6 vs GPT-5.1 vs DeepSeek-R1: A Hands-On Comparison of Coding Capabilities
In-depth comparison of Claude Sonnet 4.6, GPT-5.1 Codex, and DeepSeek-R1 across API pricing, specs, and SWE-Bench Verified scores to help developers pick the best AI coding assistant.
Read more →
·3 min
Cursor Composer 2.5 In-Depth Review: One-Tenth the Cost of Opus — Is It Worth Using?
In-depth review of Cursor Composer 2.5 coding model through real-world tests including macOS cloning, landing pages, and 3D scenes. At just 7 cents per task, it offers stunning value vs Opus.
Read more →
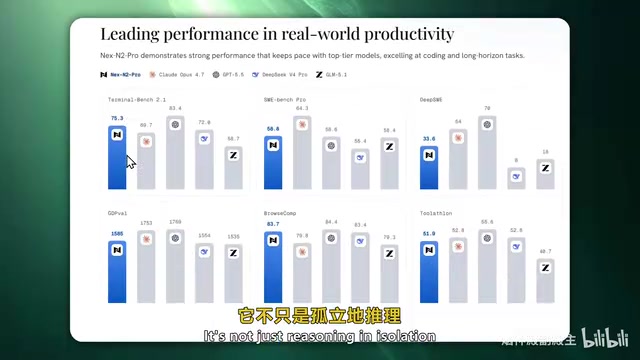
·4 min
Nex-N2 Pro In-Depth Review: Impressive Code Generation, But How Inflated Are the Benchmarks?
In-depth review of open-source agent model Nex-N2 Pro: testing code generation, SVG output, and game dev capabilities while analyzing benchmark inflation, GPT distillation traces, and speed issues.
Read more →

·1 min
Ultimate Review of the Top 10 AI Coding Models: Who Reigns Supreme?
In-depth review of the top 10 AI coding models in 2026, comparing Qwen 3.7 Max, DeepSeek V4 Pro, Claude 4.5 Summit, GPT 5.5 and more across code generation, Agent collaboration, and long-context handling.
Read more →
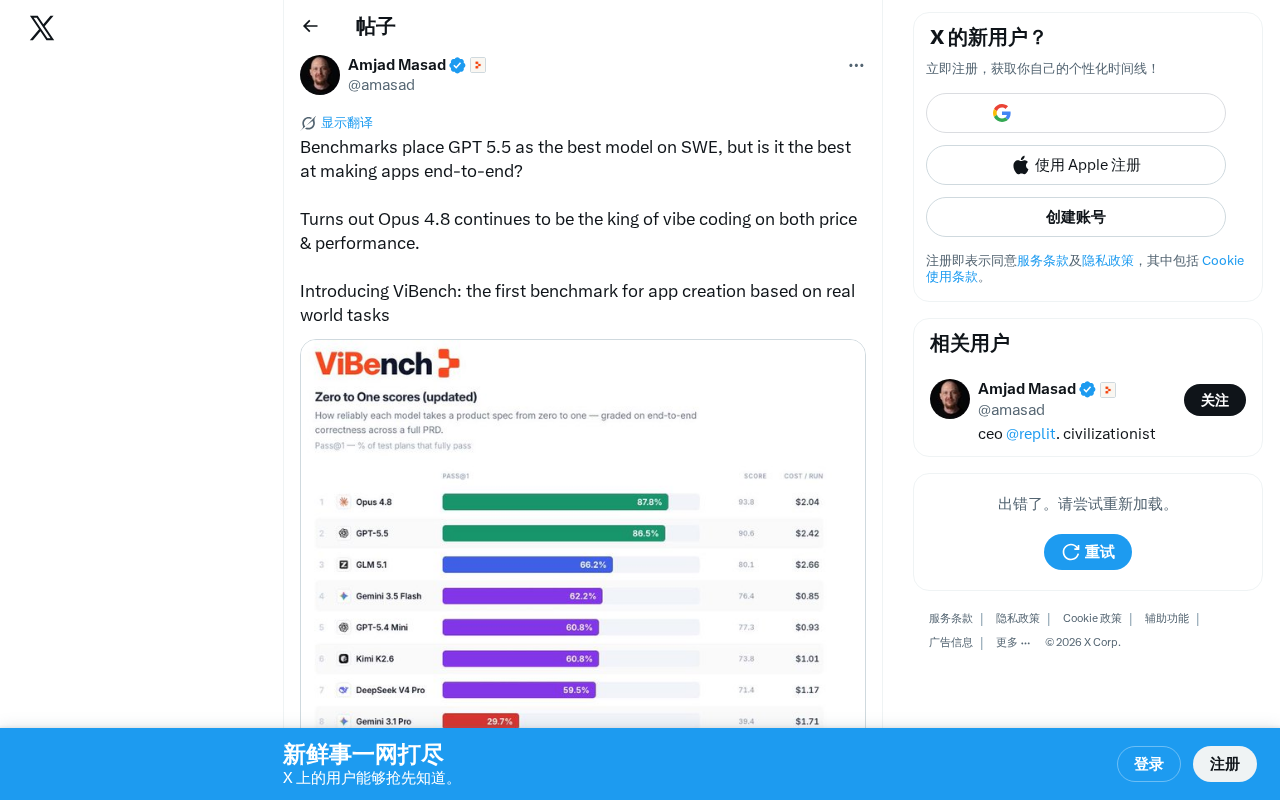
·2 min
ViBench Benchmark: End-to-End App Creation Evaluation Reveals the True Level of AI Programming
ViBench is the first end-to-end app creation benchmark based on real-world tasks. Results show Claude Opus 4.8 leads in performance and cost-effectiveness, revealing gaps between SWE-bench scores and actual development capability.
Read more →
 Product Reviews
Product Reviews·1 min
Claude Haiku 4.5 Hands-On: Coding Ability Rivals Sonnet 4 at One-Third the Cost
Hands-on testing of Claude Haiku 4.5's coding ability, comparing it with Sonnet 4.5 and Opus 4.1 across weather cards, physics simulation, and 3D rendering tasks.
Read more →
 Tutorials
Tutorials·3 min
3-in-1 Refill Tool: Unlimited Usage Solution for Kiro/Cursor/Windsurf
A refill tool integrating Kiro, Cursor, and Windsurf for unlimited AI coding assistant usage including Claude 4.5. Analysis of technical principles, methods, and potential risks.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
Opus 4.7 Fast Mode Lands on Windsurf: 2.5x Speed Boost with No Loss in Intelligence
Claude Opus 4.7 fast mode launches on Windsurf with ~2.5x speed boost while maintaining full intelligence. Analysis of its impact on AI-assisted coding and Windsurf's competitive strategy.
Read more →
Product Reviews
Comprehensive Review of 10 Mainstream …
·4 min
Comprehensive Review of 10 Mainstream AI Coding Tools: How to Choose from Cursor to Claude Code
In-depth comparison of 10 AI coding tools including GitHub Copilot, Cursor, Claude Code, and Windsurf, analyzed across features, target users, and pricing to help developers choose the right AI assistant.
Read more →
Product Reviews
Deep Comparison of o1, o1 pro, and o3-…
·3 min
Deep Comparison of o1, o1 pro, and o3-mini-high Coding Capabilities: A Deep Research Analysis
Deep Research comparison of OpenAI o1, o1 pro, and o3-mini-high coding capabilities, covering code quality, optimization, error rates, and debugging with benchmarks and real-world cases.
Read more →