#IDE
1599 related articles
 Industry Insights
Industry Insights·2 min
OpenAI Foundation Commits $250 Million Across Three Key Directions to Promote Shared AI Prosperity
OpenAI Foundation commits $250M across measurement, transition support, and shared prosperity to ensure AI benefits reach broader global populations. Deep analysis of industry implications.
Read more →
 Industry Insights
Industry Insights·2 min
What Problem Do You Most Want AI to Solve? A Deep Reflection on the Future Direction of AI
A simple tweet sparks wide discussion: What do you most want AI to solve? From healthcare to education equity and scientific research, exploring the shift from technology-driven to demand-driven AI.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
OpenAI Codex New Version Released: A Major Upgrade for the AI Programming Assistant
OpenAI releases a new version of Codex with major improvements in code generation accuracy, multi-language support, and developer workflow integration. Analysis of its impact on the AI programming landscape.
Read more →
Tutorials
CLAUDE.md Configuration Guide: Write Y…
·2 min
CLAUDE.md Configuration Guide: Write Your Project Spec Using a Six-Section Structure
A detailed guide to configuring CLAUDE.md with a six-section structure covering project overview, features, tech stack, directory structure, code conventions, and constraints to boost AI coding efficiency.
Read more →
Tutorials
Claude Code Hidden Configurations Full…
·3 min
Claude Code Hidden Configurations Fully Explained: From Chat Assistant to Semi-Automated Programming Workflow
Explore Claude Code's source code to unlock hidden configurations like Hooks, Agents, Permissions, and Memories. Transform your AI assistant into a customizable semi-automated development workflow.
Read more →
Product Reviews
Cursor 3.0 Deep Dive: The AI Agent Com…
·3 min
Cursor 3.0 Deep Dive: The AI Agent Command Center Rewritten in Rust
Cursor 3.0 abandons VS Code entirely, rewritten from scratch in Rust as an AI agent management platform. Deep dive into its three evolutions, Composer 2 controversy, parallel agent orchestration, and the paradigm shift from assisted to autonomous coding.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
OpenAI Codex Now Fully Supports Windows Development Workflows: A Deep Dive into Computer Use Capabilities
OpenAI Codex adds Windows Computer Use capabilities, enabling direct testing, debugging, and code review in Windows environments. ChatGPT mobile also supports remote Windows machine connections.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
Windsurf Integrates Claude Opus 4.7 Fast Mode with 2.5x Speed Boost
Windsurf integrates Claude Opus 4.7 fast mode with 2.5x speed boost while retaining full intelligence. Analysis of its impact on developer productivity and AI coding tool competition.
Read more →
 Research
Research·2 min
Agent Loops in Practice: Transforming Token Output into Productivity from CUDA Kernels to Automated Research
Deep dive into how the Humanize framework transforms LLM tokens into engineering productivity via Agent Loops. Covers KDA winning CUDA kernel contests, virtual hardware optimization, and 50% research cost reduction.
Read more →
 Tutorials
Tutorials·2 min
Tutorial: Deploying a PD-Disaggregated SGLang Multi-Node Inference Cluster on AMD GPUs
Learn how to deploy a PD-disaggregated SGLang inference cluster on AMD GPUs using a single config file, boosting LLM throughput and latency performance.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
SGLang v0.5.12.post1 Released: DeepSeek V4 Stability Fixes and Blackwell Adaptation
SGLang v0.5.12.post1 stability patch details: 12 critical fixes covering DeepSeek V4 garbled text and crashes, NIXL PD disaggregated inference logic, Blackwell B300 adaptation, and cold start optimization.
Read more →
 Tech Frontiers
Tech Frontiers·2 min
Step 3.7 Flash: Deep Dive into the 198B Sparse MoE Multimodal Model
Deep dive into StepFun AI's Step 3.7 Flash, a 198B sparse MoE vision-language model with 256K context and 3-level reasoning, excelling in multimodal understanding, AI coding, and Agent tool orchestration.
Read more →
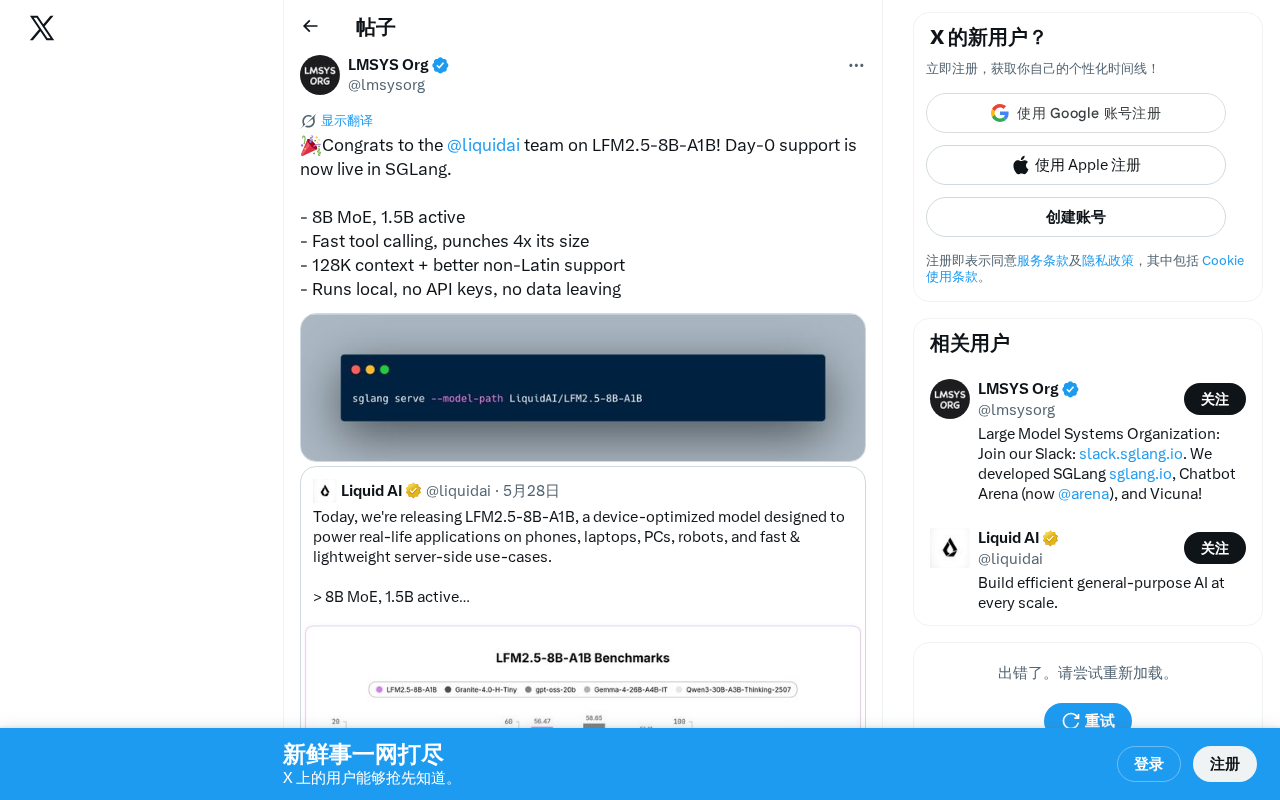 Tech Frontiers
Tech Frontiers·2 min
LFM2.5-8B-A1B: A MoE Model with 1.5B Active Parameters Delivering 4x Its Weight Class Performance
Liquid AI releases LFM2.5-8B-A1B, a MoE model with 8B total params but only 1.5B active, matching 6B-class models in tool calling. Supports 128K context, local deployment, multilingual, with SGLang Day-0 support.
Read more →
 Industry Insights
Industry Insights·2 min
SGLang Enters Finance: How AI Inference Infrastructure Is Reshaping Wall Street
SGLang co-hosts a finance AI inference event with Crusoe AI and Cloudflare, exploring LLM inference deployment in trading, risk management, and compliance — signaling Wall Street's shift to production-grade AI infrastructure.
Read more →
 Industry Insights
Industry Insights·2 min
AMD MI355X Beats B200: Full-Stack Optimization Breakdown for 5% Lower TCO on DeepSeek-R1 Inference
AMD Instinct MI355X achieves 5% lower TCO than NVIDIA B200 on DeepSeek-R1 disaggregated inference via SGLang+MoRI full-stack optimization with 1.25x per-GPU throughput.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
Cloudflare Contributes Critical KV Cache and Mooncake Fixes to SGLang
Cloudflare contributes decode KV cache offload and Mooncake recovery fixes to SGLang, resolving garbled output under high concurrency for Kimi K2.6 and enabling automatic fault recovery in distributed inference.
Read more →
 Tech Frontiers
Tech Frontiers·1 min
SGLang Hosts Agent Loops Office Hour, Focusing on Agentic Loop Architecture Optimization
SGLang team hosts an Agent Loops Office Hour exploring inference optimization for agentic loops, covering KV Cache reuse, low-latency multi-turn dialogue, and tool calling techniques.
Read more →
Product Reviews
O3 vs Gemini 2.5 Pro vs Claude 3.7: Re…
·3 min
O3 vs Gemini 2.5 Pro vs Claude 3.7: Real-World AI Coding Ability Comparison
Real-world comparison of O3, Gemini 2.5 Pro, and Claude 3.7 coding abilities through snake battles, RL training, solar system simulation, and soccer game tasks.
Read more →
Product Reviews
Deep Comparison of o1, o1 pro, and o3-…
·3 min
Deep Comparison of o1, o1 pro, and o3-mini-high Coding Capabilities: A Deep Research Analysis
Deep Research comparison of OpenAI o1, o1 pro, and o3-mini-high coding capabilities, covering code quality, optimization, error rates, and debugging with benchmarks and real-world cases.
Read more →
Product Reviews
Llama 3.3 70B In-Depth Review: Testing…
·3 min
Llama 3.3 70B In-Depth Review: Testing the Strongest Open-Source LLM with 13 Questions
Meta releases Llama 3.3 70B open-source model with just 70B parameters rivaling 405B performance. Tested on 13 logic, math, and coding questions, it passed 12 — reshaping the open-source model landscape.
Read more →